循环计算
在集算器的序列、序表以及排列中,循环计算可以针对序列中的每一个成员,或者序表和排列中的每一条记录执行计算。通过使用简单的循环函数,就可以完成这样的计算,而不必使用循环语句。
循环计算
循环计算序列时,在循环函数参数中可以引用序列成员:~ 表示当前序列成员,也称为基成员;# 表示当前成员的序号。
循环计算序表或排列时,可以用字段名F直接引用当前记录的字段值,需要注意的是,如果在排列中 引用字段值,排列中的所有记录都需要存在字段F。在引用时,也可以用~.F, r.F或 A.F,表明引用的字段属于哪个记录r,或者哪个排列(序表) A。
特别强调:如果内存中有与字段同名的变量,则不可以在循环函数中使用该字段的省略写法,必须写全~.F或A.F,仅写F将被解释为同名的变量。
由结果构成序列
对序列A中的每个成员循环计算,并返回由结果构成的新序列,可以用函数A.(x) 实现。如:
|
|
A |
|
1 |
[2,5,-3,8] |
|
2 |
=A1.() |
|
3 |
=A1.(#*#) |
|
4 |
=A1.(power(~,3)) |
A2函数中没有循环表达式,直接返回A1中的序表,A3中计算序号的平方值构成的序列, A4中计算成员的立方构成的序列。A1,A2,A3,A4中的数据如下:

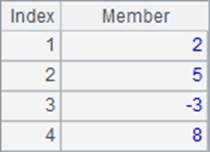
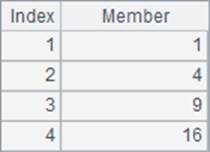
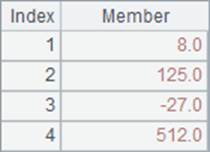
其中,A1与A2中显示的其实是同一个序列,A3和A4都是由计算结果新生成的序列。
在序表或排列中,同样可以用函数A.(x) 循环计算,此时表达式中可以引用记录的字段。如:
|
|
A |
|
1 |
=demo.query("select EID,NAME,SURNAME,GENDER, BIRTHDAY,STATE from EMPLOYEE") |
|
2 |
=A1.(STATE) |
|
3 |
=A1.(age(BIRTHDAY)) |
A1中是从数据库获得的序表:
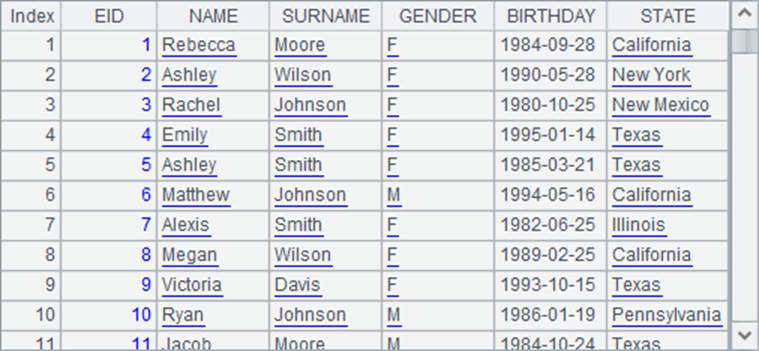
A2计算出每位员工所在的州,A3计算出每位员工的年龄,A2和A3中的数据如下:
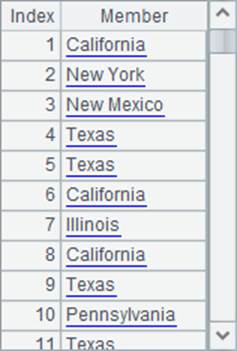
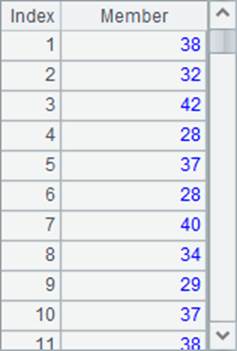
可以发现,在序表或序列中,A.(x) 返回的结果是序列而不是序表,结果中是没有字段名的。
循环计算时,可以设置多个连续计算的表达式,即A.(x, …),此时对A中每个成员循环计算时,会依次计算每个表达式,但之后记录最后一个表达式的结果,返回这些结果构成的序列。如:
|
|
A |
|
1 |
[2,3,5,7,11] |
|
2 |
>sum=0 |
|
3 |
=A1.(sum=sum+~, round(~/sum,2)) |
计算后,A1和A3中的值如下:
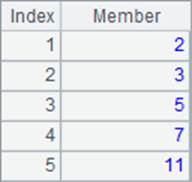
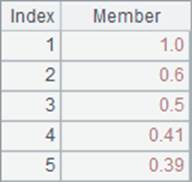
A3中执行循环计算时,先计算出累计和,再计算序列中当前成员的累计占比。计算A.(x, …)时,前方的表达式基本会用来执行赋值处理或者中间计算等,最后一个表达式用来返回所需的结果。
循环后返回原序列
循环序列A中的每个成员,还可以使用A.run(x) 函数,此时也会循环执行表达式x,但是会返回原序列A。如:
|
|
A |
|
1 |
[2,5,-3,8] |
|
2 |
=A1.run(~=~*2) |
程序执行后,A1与A2中的序列是相同的:
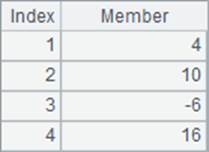
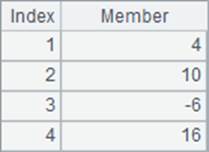
由于run函数返回原序列而不是结果序列,因此通常用来修改序列中的成员,如本例中将原序列成员增大为2倍。
在序表或序列中经常使用A.run(x) 函数来循环修改记录,如:
|
|
A |
|
1 |
=demo.query("select EID,NAME,SURNAME,GENDER, BIRTHDAY,STATE from EMPLOYEE") |
|
2 |
>A1.run(GENDER=case(GENDER,"F":"Female","M":"Male"),BIRTHDAY= string(BIRTHDAY,"dd/MM/yyyy")) |
在A2中,用run函数将GENDER字段的值改为Male和Female,同时将BIRTHDAY字段更改格式,执行后,A1中的序表被修改为如下结果:
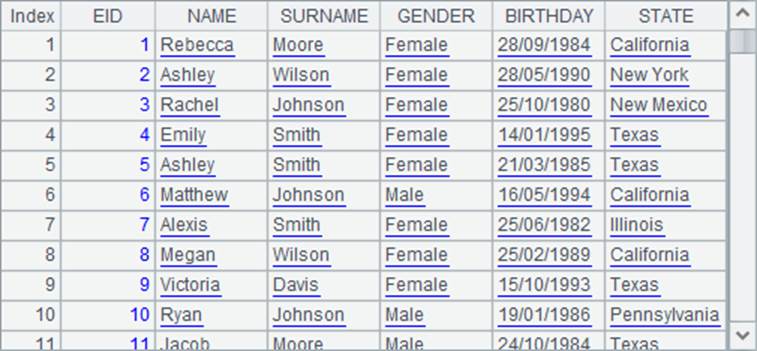
相对引用
在循环计算时,可以用A[i]或~[i]根据来引用序列中当前成员之后序号相差i的成员,i可以是负数。如:
|
|
A |
|
1 |
[2,5,-3,8] |
|
2 |
=A1.(~[1]-~) |
|
3 |
>A1.run(~=~+~[-1]) |
A2中计算的是原序列A1中,后一个成员与当前成员的差值序列:
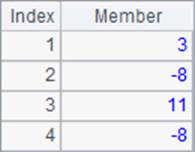
A3中的表达式以>开头,调用run函数时只修改原序列而不返回,执行后A1中的序列变为了原来成员的累加值序列:
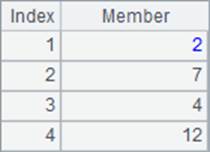
在序列或排列中,除了用~[i]相对引用1条记录,还可以用F[i]相对引用1条记录的F字段,相当于A[i].F。如:
|
|
A |
|
1 |
=demo.query("select EID,NAME,SURNAME,GENDER, BIRTHDAY,STATE from EMPLOYEE") |
|
2 |
=A1.sort(BIRTHDAY) |
|
3 |
=A2.(interval(BIRTHDAY[-1],BIRTHDAY)) |
|
4 |
=A2.(interval(~[-1].BIRTHDAY,BIRTHDAY)) |
A2中将序表中的数据按生日排序:
A3与A4中的表达式是等价的,计算出每位员工比年龄排在他前面1位的员工,生日差多少天:
如果A3中表达式改用BIRTHDAY[1]则表示年龄排在他后面1位员工的生日。
除了相对引用1条记录,类似的,也可以引用多条记录。此时可以用A[a:b], ~[a:b],引用当前成员后的第a个到第b个成员组成的序列或排列。如:
|
|
A |
|
1 |
=demo.query("select EID,NAME,SURNAME,GENDER, BIRTHDAY,STATE from EMPLOYEE") |
|
2 |
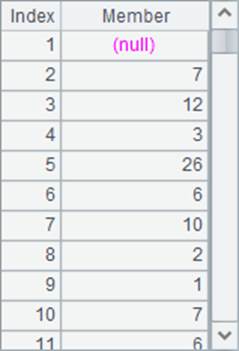
=A1.groups(year(BIRTHDAY);count(~):Count) |
|
3 |
=A2.(~[-1,1]) |
|
4 |
=A2.(Count[-1,1]) |
A2中统计出每年出生的员工总数:
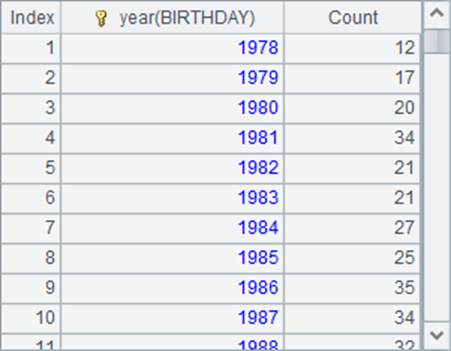
A3中则选出每年的前后1年区间内的统计数据:
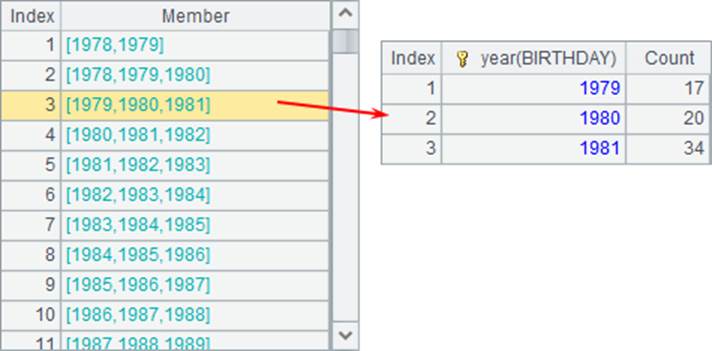
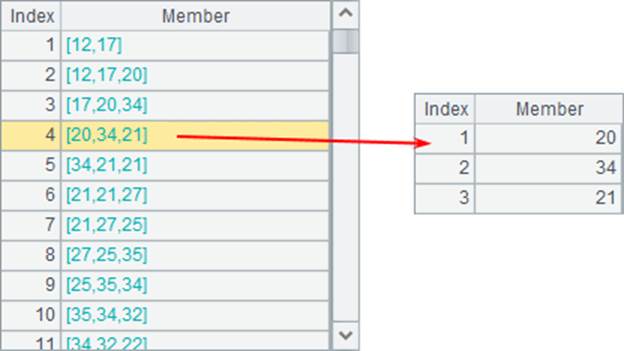
类似的,也可以用F[…]来相对引用多条记录的字段,如A4中选出每年前后1年区间内的员工总数:
循环函数
针对序列的每个成员做某种计算的函数称为循环函数,一般形式为A.f(x),实际上,序列的聚合运算也是循环函数。循环函数的计算行为由函数名决定,如sum表示求和、avg表示平均等等。在函数中,已经对循环函数的一般使用做了说明,使用序表或排列时,可以在循环函数中使用字段或表达式等。
聚合运算
在聚合运算中,对序列或序表/排列中的每个成员循环计算,并根据函数计算结果,如:
|
|
A |
|
1 |
[2,5,-3,8] |
|
2 |
=A1.sum() |
|
3 |
=demo.query("select EID,NAME,SURNAME,GENDER, BIRTHDAY,STATE from EMPLOYEE") |
|
4 |
=A3.avg(age(BIRTHDAY)) |
|
5 |
=A3.count(STATE=="California") |
A2中用A.sum()函数,计算出序列成员的总和如下:

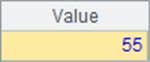
A4中用A.avg()函数计算序表中所有员工的平均年龄,A5中计算加州员工总数,A4和A5的结果如下:

聚合运算类的循环函数很多,还有A.min(),A.max(),A.ranks(),A.variance()等。
|
|
A |
|
1 |
[2,5,,-3,8] |
|
2 |
=A1.min() |
|
3 |
=A1.min@0() |
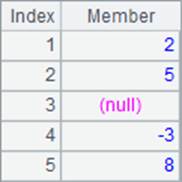
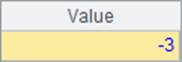
计算A.min() 时,会返回序列A中成员的最小值,但是空值null是不计的。如果需要考虑空值,则需要添加@0选项,在这种情况下,实际上空值就会被认为是最小值。上面例子中,A1, A2和A3中结果如下:

特别的,对于[x1, x2,…xn].f()这种样式的聚合运算,在没有歧义的情况下,也可以写为f([x1, x2,…xn])或f(x1, x2,…xn),如:
|
|
A |
|
1 |
[2,5,-3,8] |
|
2 |
=sum(A1) |
|
3 |
=sum(2,5,-3,8) |
|
4 |
=demo.query("select EID,NAME,SURNAME,GENDER, BIRTHDAY,STATE from EMPLOYEE") |
|
5 |
=avg(A4.(age(BIRTHDAY))) |
A2和A3中的计算结果和上一个例子中A2中结果相同。A5中的结果和上例A4中结果相同。
整数循环
对于需要循环指定次数的运算,可以用[1,2,3,…,n]这样的序列来循环计算。to(n).f(x)可以简写为n.f(x),称为整数循环,如:
|
|
A |
|
1 |
=10.sum() |
|
2 |
=demo.query("select EID,NAME,SURNAME,GENDER, BIRTHDAY,STATE from EMPLOYEE") |
|
3 |
=5.(A2(rand(500)).NAME) |
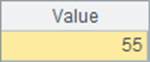
A1中计算出1至10的总和如下:
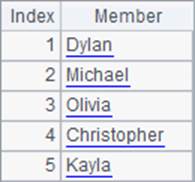
A3中随机选出5位员工,并列出他们的名字,结果如下:
嵌套
循环函数可以嵌套使用,即在计算表达式中再使用循环计算,类似A1.f1(A2.f2(x)) 这样的格式。在嵌套的循环函数中,~、#将解释为里层序列的当前成员和序号,而引用外层序列时需冠以序列名称,写作A.~、A.#。如:
|
|
A |
|
1 |
=demo.query("select EID,NAME,SURNAME,GENDER, BIRTHDAY,STATE from EMPLOYEE") |
|
2 |
=A1.group(year(BIRTHDAY)) |
|
3 |
=create(Year,Male,Female) |
|
4 |
>A2.run(A3.insert(0,year(BIRTHDAY),A2.~.count(GENDER== "M"),A2.~.count(GENDER=="F"))) |
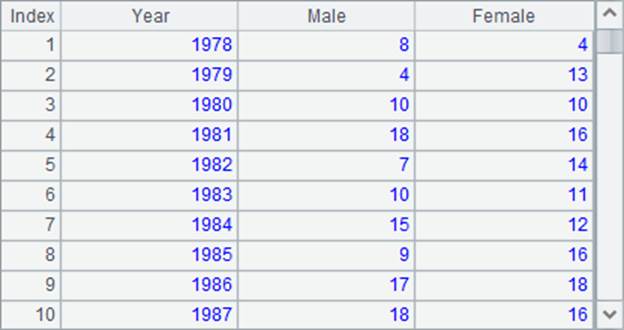
A2中将员工数据按出生年份分组:
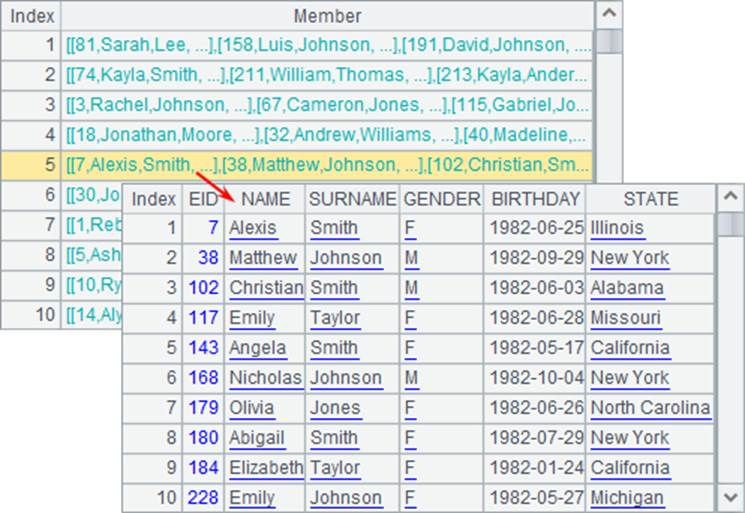
A3建立空序表准备存储计算结果。在A4中,循环分组后每年的数据,计算这一年中男员工和女员工的总数,将结果插入到结果序表中。在这里,执行后,可以在A3中查看到结果如下:
迭代函数
在循环函数计算中,会依次取出序列或排列中的成员,来执行某种计算,如果在计算过程中,需要根据已有的结果迭代计算,可以使用迭代函数。最基本的迭代函数是iterate(x,a;Gi,…),它需要在循环过程中调用,迭代时,会循环计算表达式x,而在其中可以用~~来调用已有的结果,并在计算后将x保存到~~,如果计算时设定的表达式Gi,…有变化,则x会根据a重新计算出初始值~~,如:
|
|
A |
|
1 |
=demo.query("select * from CITIES") |
|
2 |
=A1.sort(STATEID, left(NAME,1),CID) |
|
3 |
=A2.derive(iterate(~~+1, STATEID*100; STATEID):Code1) |
|
4 |
=A3.derive(iterate(~~+1, 0; STATEID,left(NAME,1)):Code2) |
A3和A4的表达式中,在用derive添加字段时,使用了迭代函数。A3函数中,iterate中对同一个州的城市顺序编号,而对每个州内,城市的初始值用州编码乘以100得到。A4继续用迭代函数添加字段Code2,iterate中对同一个州且城市名首字母相同的顺序编号,每次都从0开始重新编号。计算后,A4中的结果如下:

对于A4中的情况,每次都是累加计数,而且从0开始,迭代时可以用seq(Gi,…)来简写即如果把A4中的表达式修改为=A3.derive(seq(STATEID,left(NAME,1)):Code2),结果是相同的。
在迭代时,除了用seq,在未产生变化时依次计数,还可以使用rank(F;Gi,…)或ranki(F;Gi,…)根据指定表达式F的变化来排序,对于F相同的记录,获得相同的编号如:
|
|
A |
|
1 |
=demo.query("select * from CITIES") |
|
2 |
=A1.sort(STATEID, left(NAME,1),CID) |
|
3 |
=A2.derive(iterate(~~+1, STATEID*100; STATEID):Code1) |
|
4 |
=A3.derive(seq(STATEID,left(NAME,1)):Code2) |
|
5 |
=A4.derive(rank(left(NAME,1);STATEID):Rank1) |
|
6 |
=A5.derive(ranki(left(NAME,1);STATEID):Rank2) |
A5中用迭代函数rank添加字段Rank1,A6中用迭代函数ranki添加字段Rank2,计算后,A6中的结果如下:

A5和A6的迭代计算中,函数中的参数Gi,…都只设定了STATEID,比较Rank1和Rank2可以发现,使用rank时,同一个州内的城市编号时,并列的编号会使后面的排名顺延;而使用ranki时,并列的编号只记为1个。
除了生成编码,用迭代函数还可以计算累计求和,如:
|
|
A |
|
1 |
=to(6) |
|
2 |
=A1.(iterate(~~+~*~)) |
|
3 |
=A1.(cum(~*~)) |
|
4 |
=to(10).iterate(~~+~*~,0,~>6) |
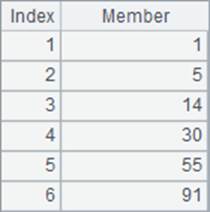
A2中,计算A1中数的累计平方和,结果如下:
在从0开始累计迭代时,可以用cum简写,A3中的结果和A2中是相同的。如果只需要最后的结果,可以使用A.iterate(x,a,c)函数,A4中,迭代计算累计平方和,至序列中的成员大于6为止。这样,A4中可以直接得到1至6的平方和,结果如下: