
函数
序列与字串
通过s.split()和A.concat()两个函数,序列和字串可以很方便地相互转化。函数s.split(d)用来将字串s以分隔符d拆分成序列,@p选项自动识别数据类型;d缺省为按字符拆分。函数A.concat(d)用来将序列A用分隔符d连接,拼接成字串,自动处理数据类型;d缺省为无分隔符。在这两个函数中可以添加@c选项,表示以逗号为分隔符。
如:
|
|
A |
|
1 |
a,1,c,2011-8-11,false |
|
2 |
=A1.split@c() |
|
3 |
=A2.concat@c() |
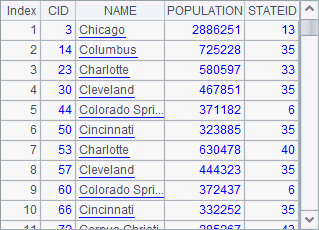
A2和A3中结果如下:
![]()
可以看到,A2中拆分子串后,结果序列中的成员均为字符串,如果需要自动解析数据类型,可以添加@p选项。
正则表达式函数s.regex(rs)用正则表达式rs匹配字串s,返回匹配结果的序列;如果无法匹配,则返回null。regex函数中,可以添加选项@c表示大小写字母不敏感,添加选项@u表示使用unicode匹配。
用regex函数,最简单的用法就是判定某个字符串与指定正则表达式的匹配结果,下面先来看一下与数字字符串的匹配用法:
|
|
A |
B |
C |
|
1 |
="a12b".regex("(a[0-9])") |
="a12b".regex("(a[0-9]*)") |
="a12b".regex("[0-9]b") |
|
2 |
="a12b".regex("\\S*([0-9][a-z])") |
'\S*([0-9][a-z]) |
="a12b".regex(B2) |
先来看A1,B1和C1中的结果:
![]()
![]()
![]()
在A1中使用的正则表达式是"(a[0-9])",其中a就是对应字母a本身,而[0-9]表示0至9之间的1个字符,即1位数字,两边的小括号()表示把字符串中能匹配“字母a开头后接1位数字”的串取出返回,结果就是单一成员a1构成的序列。B1中[0-9]后面的*表示连续匹配前面的字符任意次,这里表示连续的任意位数字,因此B1中返回的结果是a12。C1中,需要返回数字开头后面接着字母b的字符串,但是a12b并非是“以数字开头”的,因此无法匹配,C1中的结果是null。
在A2中使用的正则表达式是"\\S*([0-9][a-z])",其中[a-z]表示字母a至z之间的字符,即所有小写字母。\S*表示连续的任意个可见字符,由于\是字符串中的转义字符,因此需要用\\S*表示。在这里,用小括号表示取出的部分是后面匹配[0-9][a-z]的结果,而前面匹配\S*的部分会被丢弃。在B2中,用字符串常数来表示A2中的正则表达式,此时不涉及字符串转义问题,所以C2中可以获得和A2中相同的结果。A2和C2中的结果如下:
![]()
![]()
在集算器中,用正则表达式匹配字符串时,需要将返回的部分用 () 括起来,将返回由括号括起来的成员所构成的序列,否则在能够匹配时只会返回字符串本身。
在使用regex() 函数时,可以添加@c选项,表示在匹配正则表达式时,大小写字母不敏感,如:
|
|
A |
B |
C |
|
1 |
="a12b".regex@c("(A[0-9])") |
="a12b".regex@c("([A-Z][0-9])") |
="a12b".regex("([A-Z][0-9])") |
A1,B1和C1中结果如下:
![]()
![]()
![]()
A1中正则表达式中要求匹配大写字母A,B1中要求匹配任1个大写字母,由于使用了@c选项,因此用regex() 都能得到匹配结果a1,而C1中未使用@c选项,无法匹配正则表达式,返回null。
用正则表达式rs匹配字串s,返回匹配结果的序列;如果无法匹配,则会返回null。
当用集算器处理非英文字符时,有时需要用unicode来执行正则表达式,这是由于用unicode比较标准,不会被字符集设置所干扰。此时使用regex() 函数时,需要添加@u选项,如:
|
|
A |
B |
|
1 |
="Gerente de Fábrica".regex(".* (.*á.*)") |
="Gerente de Fábrica".regex@u(".* (.*\\u00e1.*)") |
A1的正则表达式.* (.*á.*)中,小数点 . 表示除回车符和换行符外的任一个单字字符,.*则表示任意个字符,A1中取出的是从最后一个包含字符á的单词之后的字符串。B1中的正则表达式是同样的意义,不过regex函数添加了@u选项,其中的字符á用unicode的表示方法,表示为\u00e1,regex@u() 通常用于解析外部字符串,通过unicode设置正则表达式可以避免不同字符集的干扰。A1和B1中的结果是相同的:
![]()
![]()
聚合函数
序列的聚合函数包括求和A.sum()、平均值A.avg()、最大值A.max()、最小值A.min()、方差A.variance()等等。它们的使用方法都类似,如:
|
|
A |
|
1 |
[2,4,6] |
|
2 |
=A1.sum() |
|
3 |
=A1.sum(~*~) |
A2对序列求和,A3求序列中成员的平方和,A2和A3中的结果如下:
![]()
![]()
如果序列中的成员全部是结果为布尔型的判断条件,可以用函数A.cand() 和A.cor() 来判断这些条件是否全部成立,或者是否至少有一个成立。如:
|
|
A |
B |
C |
D |
|
1 |
=[1,2,3,4].cand(24%~==0) |
=[12,-3,0].cor(24%~==0) |
[] |
|
|
2 |
for 500 |
=A2%3==2 |
=A2%5==3 |
=A2%7==2 |
|
3 |
|
if [B2:D2].cand() |
>C1=C1|A2 |
|
A1中,判断序列[1,2,3,4]中的成员,是否全部是24的约数,B1中则判断[12,-3,0]中的成员是否包含了24的约数。中国古代有一道著名算题:“今有物不知其数,三三数之剩二;五五数之剩三;七七数之剩二。问物几何?”在第2、3行,计算了这道题目在500以内的解,记录在了C1中。计算后,A1,B1和C1中结果分别如下:
![]()
![]()

当序列中出现重复成员时,可以用不同的聚合函数A.count()和A.icount()来统计。如:
|
|
A |
|
1 |
[2,3,3,2,5,7,1] |
|
2 |
=A1.count() |
|
3 |
=A1.icount() |
A2中计算序列中所有成员的个数,而A3中只计算不同成员的个数,A2和A3中的结果如下:
![]()
![]()
如果序列中的成员都是整数,可以添加选项以提高计算效率,用A.icount@n() 来计算。如果序列中的成员都是整数或者长整数,则可以用A.icount@b() 来计算。
还有一些聚合函数是和排序相关的,如排序函数A.rank(y) 和中位数函数A.median(k:n)。如:
|
|
A |
B |
C |
|
1 |
[6,8,1,3,7,2,4,9,5] |
|
|
|
2 |
=A1.rank(8) |
=A1.rank@z(8) |
|
|
3 |
=A1.median() |
=A1.median(1:4) |
=A1.median(:3) |
A2中计算8在序列中从小到大的排名,B2中则计算8在序列中从大到小的排名,A2和B2中结果分别如下:
![]()
![]()
A3计算序列A1中的中位数,即序列中值的大小位于最中间的一个成员,如果序列中成员为偶数个,那么中位数将返回最中间的两个成员的平均值。如果在median函数中添加参数,则可以取出序列中成员按照从小到大的顺序,处于参数所指定分段点的成员,类似的,如果分段点正好处于两个成员中间,则会返回两个成员的平均值。如B3中即返回位于1/4点的数据,因此,A.median(k:n)的参数中,分段数n必须为不小于2的整数,而k必须小于。当参数中的k省略时,将返回序列n等分点位置的数据。A3,B3和C3中的结果如下:
![]()
![]()

还有一些函数是用来在多个序列之间聚合运算的,如:
|
|
A |
B |
|
1 |
[[1,2,3],[3],[3,4],[6,5,3]] |
|
|
2 |
=A1.conj() |
=A1.union() |
|
3 |
=A1.diff() |
=A1.isect() |
在使用A.conj(),A.union(),A.diff(),A.isect()这些函数时,应该是序列的序列。A2,B2,A3,B3分别计算A1中各个序列成员的和列、并列、差列和交列,结果分别如下:

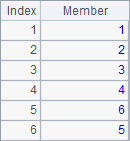
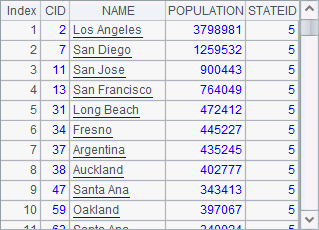
![]()
循环函数
循环函数可以针对序列的每个成员进行计算,可以将结构复杂的循环语句用简单的函数来表达,包括循环计算、过滤、定位、查找、排名、排序等,如:
|
|
A |
B |
C |
|
1 |
[2,4,-6] |
=A1.(~+1) |
|
|
2 |
=A1.select(~>1) |
=A1.pselect@a(~>1) |
=A1.pos([-6,2]) |
|
3 |
=A1.ranks@z() |
=A1.sort() |
=A1.sort(-~) |
B1将序列中每个成员加1,结果如下:
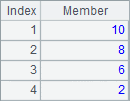
A2过滤出大于1的成员,B2定位出大于1的所有成员的序号,C2查找成员-6和2在序列A1中的序号。A2,B2和C2中的结果如下:
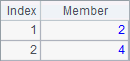

A3中,通过在ranks函数中添加@z选项,按降序求得序列各成员的排名,B3将序列中的成员升序排序,C3则将序列中的成员降序排序。A3,B3和C3中的结果如下:
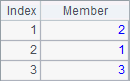
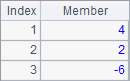
特别的,使用某些定位函数时,可以指定查找的起始位置,如:
|
|
A |
B |
|
1 |
[2,4,-6,null,4,3,] |
|
|
2 |
=A1.pselect@a(~>1, 5) |
=A1.pos(4,3) |
A2中,从第5个成员开始查找大于1的成员位置,B2中从第3个成员开始查找4的位置,A1和B2中结果如下:
![]()
在定位函数中,除了常用的@1和@z选项,还经常使用@0选项,如:
|
|
A |
B |
C |
|
1 |
[2,4,-6,null,4,3,] |
|
|
|
2 |
=A1.pselect(~>10) |
=A1.pselect@0(~>10) |
=A1.pos(5) |
|
3 |
=A1.pos@0(5) |
=A1.pmin() |
=A1.pmin@0() |
A2,B2,C2,A3,B3,C3执行后的结果如下:
![]()
![]()
![]()
![]()
![]()
![]()
可见,添加了@0选项后,A.pselect()和A.pos()函数在无法找到成员的情况下会返回0而不是空值,A.pmin@0()则会在序列中存在空值时返回首个空值所在的位置。@0选项还可以用于其它的一些定位或选出函数,如A.pfind(), A.ptop ()和A.top()。
除了@0选项,A.pselect()和A.pos()函数还可以使用@n选项,在无法找到成员的情况下返回序列的总长度+1,如:
|
|
A |
B |
|
1 |
[2,4,-6,null,4,3,] |
|
|
2 |
=A1.pselect@n(~>10) |
=A1.pos@n(5) |
A2和B2中的结果是相同的:
![]()
![]()
需要注意的是,@0选项和@n选项是互斥的,不能同时使用。