大数据结果集的外存分组原理
在获得了数据表中的数据之后,我们经常需要将这些数据按照需要分组,或者计算出分组汇总的结果。在集算器中,可以用groups函数计算数据的分组汇总结果,也可以用group函数将数据先分组,再在后面的计算中进一步分析计算。
但是,在面对大数据时,情况就会有所不同,这时无法一次将所有记录读入内存后再划分到各组。有时,分成的组的数量很大,连分组汇总的结果都不能一次返回。在这两种情况下,需要使用外存分组。
首先,我们先来准备一个简单的大数据表记录员工资料,包括员工编号、所在州和生日三个字段,其中编号顺次生成,所在州使用缩写,从demo数据库的STATES表中随机获取,生日从1994-1-1往前,随机选择10,000天之内的日期。为方便起见,大数据表存储为集文件。
|
|
A |
B |
C |
|
1 |
1000000 |
1000 |
=A1/B1 |
|
2 |
=file("BirthStateRecord.btx") |
=create(ID,Birthday,State) |
=demo.query("select ABBR from STATES") |
|
3 |
1994-1-1 |
0 |
=C2.(ABBR) |
|
4 |
for C1 |
for B1 |
>B3=B3+1 |
|
5 |
|
|
=elapse(A3,-rand(10000)) |
|
6 |
|
|
=C3(rand(C3.len())+1) |
|
7 |
|
|
>B2.insert(0,B3,C5,C6) |
|
8 |
|
>A2.export@ab(B2) |
|
|
9 |
|
>B2.reset() |
|
|
10 |
=A2.cursor@b() |
>A10.skip(50000) |
=A10.fetch(1000) |
|
11 |
>A10.close() |
|
|
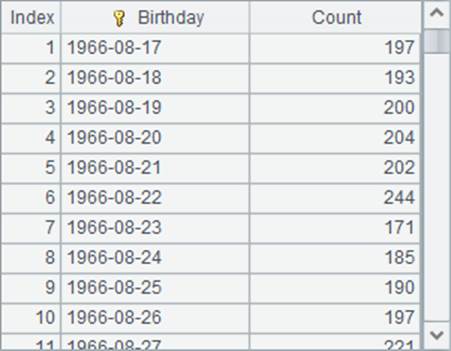
总共生成1,000,000条数据,在C10中,可以看到用游标读取第50001条到51000条的结果如下:

在对游标中的数据做分组计算时,很多时候,我们并不需要知道每一组中的具体数据,而仅需要获得分组汇总的结果,如获得BirthStateRecord数据中,每个州的员工总数,这时,可以用groups函数,计算分组汇总的结果:
|
|
A |
|
1 |
=file("BirthStateRecord.btx") |
|
2 |
=A1.cursor@b() |
|
3 |
=A2.groups(State;count(~):Count) |
|
4 |
>A2.close() |
这样在A3中就能获得分组汇总的结果:
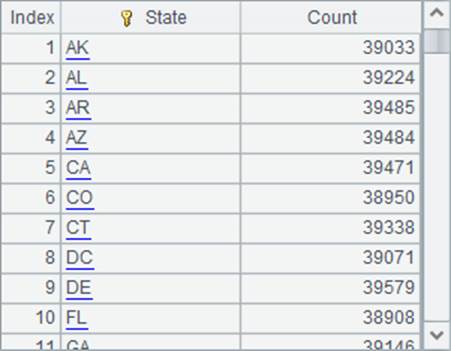
在这里,我们可以注意到,分组汇总函数groups在计算后将返回结果序表。在处理大数据计算时,有时需要分成的组会非常多,分组汇总结果集本身就很庞大,无法一次返回。如电信公司分组统计每位客户的账单;网上商城分组统计每样商品的销售情况等等。此时,如果仍然使用groups函数,将有可能造成内存溢出。在这种情况下,应该使用groupx(x:F,…;y:F,…) 函数,利用外存来完成分组汇总计算,如:
|
|
A |
|
1 |
=file("BirthStateRecord") |
|
2 |
=A1.cursor@b() |
|
3 |
=A2.groupx(Birthday;count(~):Count;1000) |
|
4 |
=A3.fetch(1000) |
|
5 |
>A2.close() |
在这里A3中使用groupx函数时,仍然添加缓存行数参数,设定为1000,注意这个参数只是为了说明外存分组的原理才添加的测试用参数,实际使用中并不需要,在内存无法容纳时才会自动生成缓存文件。我们仍然分步执行代码,一直到A4的代码执行之前。A3中用groupx函数使用外存来分组汇总。在游标计算中,用外存分组汇总,与直接指定组号的分组,同样都使用groupx函数,区别在于参数不同。A3中根据员工的生日分组,汇总计算出每天出生的员工总数,A3返回的结果是游标,如下:

当A3中代码执行后,就会在临时文件目录下,生成外存文件,可以在临时文件目录下找到这些文件:

我们可以读取其中一个临时文件中的数据:
|
|
A |
|
1 |
=file("/temp/tmpdata1786998866046507792") |
|
2 |
=A1.import@b() |
|
3 |
=A2.count() |
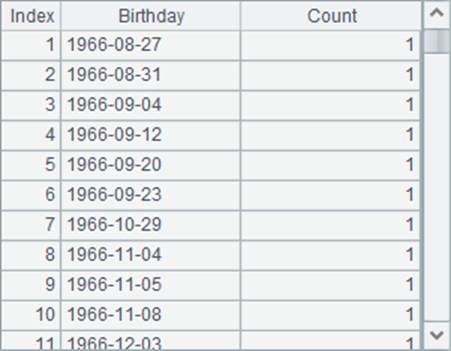
A2中读取到的数据如下:
A3中的数据如下:
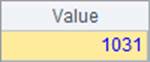
可见,每个临时文件都是一部分数据按照员工生日分组汇总的结果,所有的临时文件构成的游标,将由集算器整合后返回计算结果。在生成临时文件时,集算器会选取当前内存可顺利执行计算的组数。
在前一个网格文件中,继续运行网格。在A5中将游标关闭时,临时文件会自动删除。A4从第A3生成的游标中,读取出前1000个生日的员工总数如下: