
文本数据
在数据分析时使用的数据,通常有两类来源:数据库或文件数据。相对于数据库数据,文件数据具有部署发布简便的特点。但是,由于文件数据往往需要整体使用,需要一次读入内存,这样在处理大数据时,文件数据就显得难以使用了。为了解决这样的难题,在集算器中提供了对大数据的支持,可以用游标来读取文件数据,使得文件数据的使用更为方便。
在这里,我们通过最常见的外存文件数据——文本,了解文件数据在集算器中的使用。
文本文件数据的基本使用
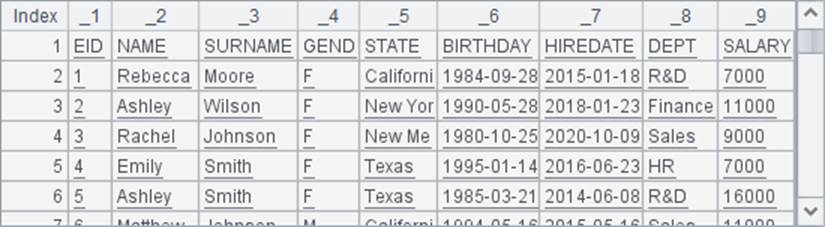
如果需要读入文本文件中的数据,可以使用file函数和import函数。如文本文件empolyee.txt中,保存了500名员工的信息,如下:
|
EID |
NAME |
SURNAME |
GENDER |
STATE |
BIRTHDAY |
HIREDATE |
DEPT |
SALARY |
|
1 |
Rebecca |
Moore |
F |
California |
1984-09-28 |
2015-01-18 |
R&D |
7000 |
|
2 |
Ashley |
Wilson |
F |
New York |
1990-05-28 |
2018-01-23 |
Finance |
11000 |
|
3 |
Rachel |
Johnson |
F |
New Mexico |
1980-10-25 |
2020-10-09 |
Sales |
9000 |
|
4 |
Emily |
Smith |
F |
Texas |
1995-01-14 |
2016-06-23 |
HR |
7000 |
|
5 |
Ashley |
Smith |
F |
Texas |
1985-03-21 |
2014-06-08 |
R&D |
16000 |
|
6 |
Matthew |
Johnson |
M |
California |
1994-05-16 |
2015-05-16 |
Sales |
11000 |
|
7 |
Alexis |
Smith |
F |
Illinois |
1982-06-25 |
2012-06-24 |
Sales |
9000 |
|
8 |
Megan |
Wilson |
F |
California |
1989-02-25 |
2014-02-26 |
Marketing |
11000 |
|
9 |
Victoria |
Davis |
F |
Texas |
1993-10-15 |
2019-10-16 |
HR |
3000 |
|
… |
|
|
|
|
|
|
|
|
在集算器中使用文本数据作为数据表使用时,对其中的格式是有要求的:记录之间用回车分隔,每个字段之间用制表符tab分隔。通过简单的代码,就可以将文本数据导入:
|
|
A |
|
1 |
=file("employee.txt") |
|
2 |
=A1 .import@t() |
|
3 |
=A1 .import() |
在集算器中,import函数用来将文件中的数据读入为序表。其中,A1中创建文件对象,当文件名中未指定路径时,将到设置中的主路径中寻找。在菜单栏中选择Tool>Options,即可在Option窗口的Environment页面中,查看或设置主路径:

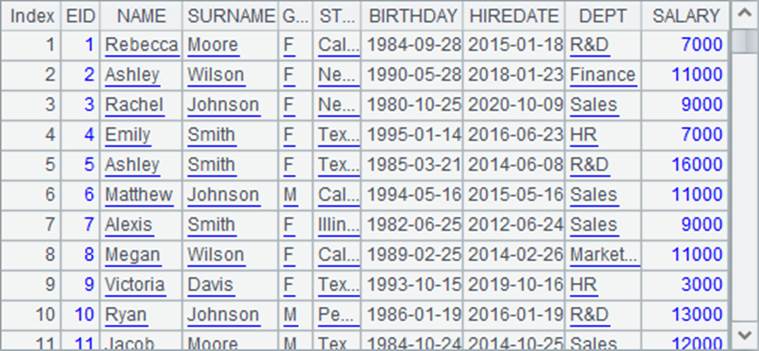
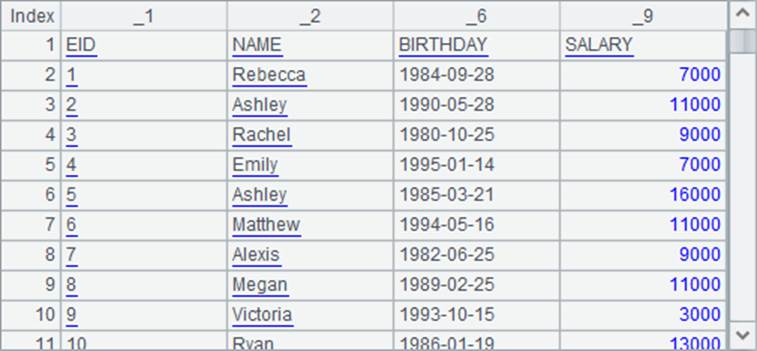
A2将文件导入为报表,使用import函数时,添加了@t选项,导入时会将文本文件的第一行读为各列的名称。为了对比,在A3中导入时未使用选项。执行后,A2中读入的序表如下:
如果文件中,各个字段之间的分隔符并非tab,如csv文件是使用逗号来分隔字段的,此时在使用import时,也可以指定分隔符。如修改A2中的代码为:=A1 .import@t(;,",")。
A3中读入的序表如下:
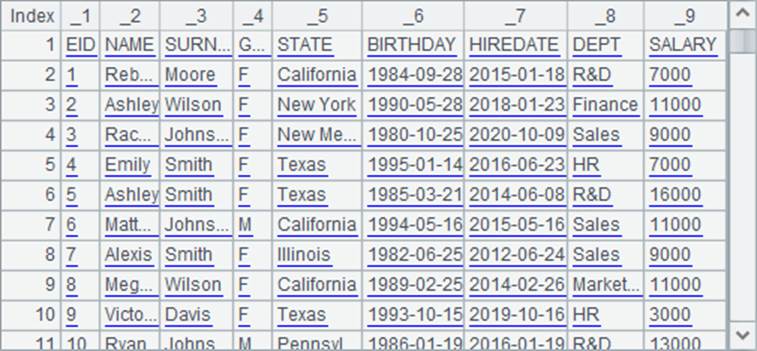
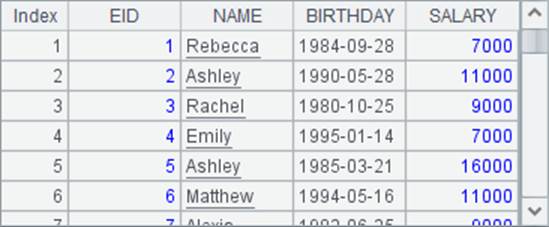
可以看到,当未使用@t选项时,将自动生成序表的字段名,按位置命名为_1,_2,_3等。
在将文本文件中的数据读入时,数据的数据类型会按照第一行数据自动解析。由于empolyee.txt的第一行数据是字段名,因此A3中各个字段的数据都会解析为字符串。如上面结果中的_1列与_9列,都是字符串,因此在展现时都是靠左对齐的;在A2结果中的EID字段和SALARY字段中的数据则是整数,展现时靠右对齐。
将文本文件导入为序表时,也可以只选择其中的部分字段。如:
|
|
A |
|
1 |
=file("employee.txt") |
|
2 |
=A1 .import@t(EID,NAME,BIRTHDAY,SALARY) |
|
3 |
=A1 .import(#1,#2,#6,#9) |
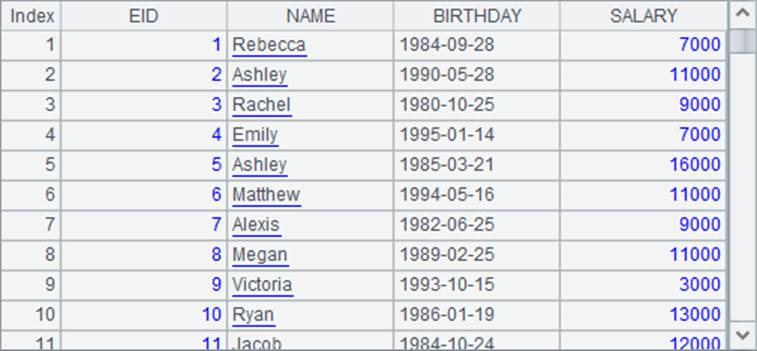
A2中添加@t选项,指定选出字段时可以直接使用字段名,数据如下:
A3中没有读入字段名,指定选出字段时,只能使用字段序号,用#i的格式指定。读入序表如下:

在前面提到,文本文件导入时,数据类型会根据第一行的数据类型自动解析。如果需要特定的数据类型,可以在选择部分数据时,指定导入字段的数据类型。如:
|
|
A |
|
1 |
=file("employee.txt") |
|
2 |
=A1 .import@t(EID:string,NAME,BIRTHDAY:date,SALARY:int) |
|
3 |
=A1 .import(#1:string,#2,#6:date,#9:int) |
在集算器中指定字段类型时,可以使用以下几种设定:
|
设定 |
string |
int |
float |
long |
decimal |
date |
datetime |
time |
bool |
|
类型 |
字符串 |
整数 |
浮点数 |
长整数 |
长实数 |
日期 |
日期时间 |
时间 |
布尔型 |
如果需要进一步了解各个数据类型的信息,可以查看基本数据类型。
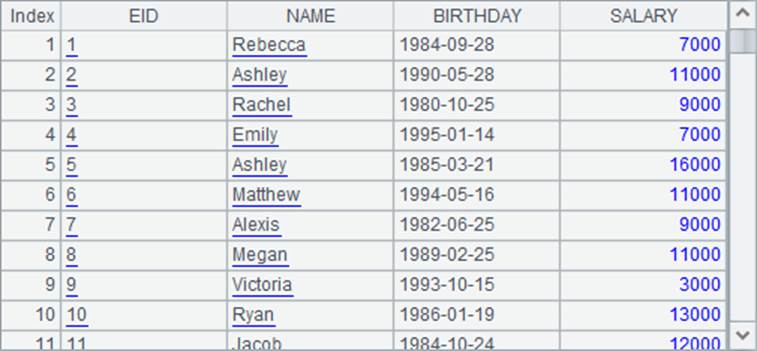
在A2中,读入数据时,指定EID字段为字符串,BIRTHDAY为日期,SALARY为整数。执行后,A2中序表如下:
A3中对各个字段类型的设定与A2相同,读取到的序表如下:
可以发现,在指定了某一列的数据类型时,如果某些数据无法解析为指定类型,将自动解析,如第一行标题行中的数据,会自动解析为字符串。
关于数据导入之后的计算,请参阅使用序表与排列。
在集算器中,还提供了T(fn, Fi, …; s) 函数,通过指定文件名及使用字段名,读出文件数据返回为序表,如:
|
|
A |
|
1 |
employee.txt |
|
2 |
=T(A1, EID,NAME,BIRTHDAY,SALARY; "\t") |
|
3 |
=T(A1, EID,NAME,BIRTHDAY,SALARY) |
|
4 |
=T@b(A1, EID,NAME,BIRTHDAY,SALARY) |
|
3 |
=T@c(A1, EID,NAME,BIRTHDAY,SALARY).fetch@x(100) |
如果分隔符s是制表符\t,那么也可以省略;如果不指定使用字段Fi, …,则会读出所有字段。使用T函数得到的结果和使用import函数是相同的,A2和A3中结果是相同的,如下:
使用T函数时,不能指定各个字段的数据类型,且默认是以首行作为字段名的。如果不使用字段名,则可以添加@b选项,另外,还可以用@c选项将文件数据读取为游标。A4和A5中结果如下:
使用T函数时,数据文件会根据文件名的扩展名自行判断,除了可以使用txt文本文件,还可以使用csv/xls/xlsx等多种类型的文件,还可以使用后面教程中将会提及的btx集文件或者ctx组表文件。
用T函数可以将文件数据读取为序表,集算器还提供了与之有些类似的E函数,它可以将二维序列读取为序表,如:
|
|
A |
B |
C |
D |
|
1 |
EID |
NAME |
BIRTHDAY |
SALARY |
|
2 |
1001 |
Frank |
2001-01-25 |
7000 |
|
3 |
1002 |
Harry |
2003-12-14 |
9000 |
|
4 |
=[[A1:D1],[A2:D2],[A3:D3]] |
|
|
|
|
5 |
=E(A4) |
=E@b(A4) |
=E(A5) |
=E@s(A5) |
|
6 |
=E(D5) |
=E(E(D5)) |
=A4(1).len().(n=~,A4.(~(n))) |
=E@p(C6) |
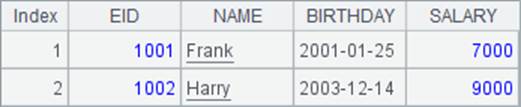
在A4中,用前3行的数据生成二维序列如下:
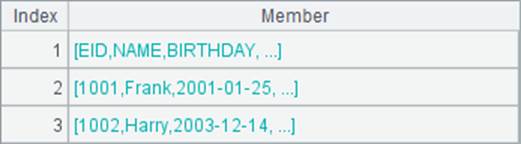
A5中用E函数将A4的二维序列读取为序表,如果添加@b选项,则与T函数类似不设定字段名,A5和B5中结果如下:

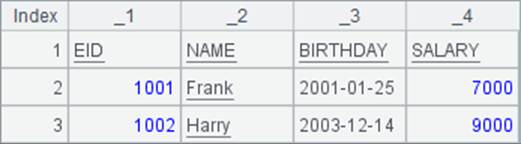
如果E函数的参数本身就是序表,则会将其转换为二维序列,也可添加@s选项,将其转换为字符串,字符串中,记录之间用回车符分隔,而每个字段之间用制表符分隔,在集算器中查看时,制表符和回车符。C5和D5中结果如下:
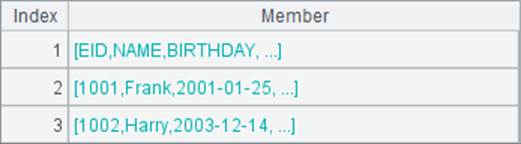

如果E函数的参数是字串,则会将其转换为二维序列,也可以再将结果作为参数得到序表,如A6和B6中结果如下:
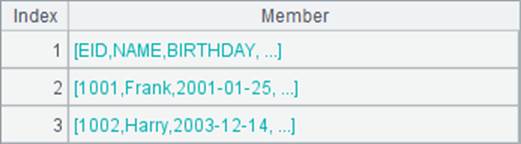
如果二维序列数据是按字段排列的,可以添加@p选项将转置后的二维序列读取为序表,C6和D6中结果如下:


除了将文本数据导入为序表,在集算器中,也可以将数据导出到文本文件中。导出时,通常使用序表或者排列中的数据,但也可以用普通序列。导出到文件时需要使用export函数,如:
|
|
A |
|
1 |
=file("employee1.txt") |
|
2 |
=create(EID,NAME).record([1,"Frank",2,"Harry"]) |
|
3 |
>A1.export(A2) |
A1中创建文件对象,准备将数据存储到employee1.txt中,此时文件仍然存储在报表的主路径中。A2中新建了一个序表,并填入了2条记录如下:

A3中,将序表中的数据导出到文件,employee1.txt中数据如下:

在导出时也可以添加@t选项导出列名,也可以导出部分字段。如将A3中的代码修改为>A1.export@t(A2,NAME),导出后,文件employee1.txt中数据如下:

在导出文件时,字段之间默认使用制表符Tab作分隔,与import的使用类似,在export时也可以指定其它分隔符。如:
|
|
A |
|
1 |
=file("employee2.txt") |
|
2 |
=create(EID,NAME).record([1,"Frank",2,"Harry"]) |
|
3 |
>A1.export@t(A2;"_") |
在A3中用export函数输出文本文件时,在分号后指定了"_"为分隔符,此时输出的文件employee2.txt中数据如下:

用T函数也可以执行导出操作,如:
|
|
A |
|
1 |
employee1.txt |
|
2 |
=create(EID,NAME).record([1,"Frank",2,"Harry"]) |
|
3 |
>T(A1:A2, NAME,EID; ",") |
|
4 |
=T@c(A1,EID,NAME; ",") |
|
5 |
>T@s(A1:A4) |
如果函数T(fn:A, Fi, …; s) 中指定了数据来源,那么这个函数执行时不会从文件fn中读取序表,而是会把A中的数据导出到文件fn中,导出时会根据文件扩展名自动识别文件种类。分步执行上面的网格文件,在A3执行后,文件employee1.txt中数据如下:

从结果中可以看到,使用T函数导出数据到文件后,文件中原本的数据会被覆盖。类似的也可以用函数T(fn:cs, Fi, …; s) 将游标cs中的数据导出到文件。如A4中用函数T@c(…)将刚刚的文件读取为游标,再在A5中将游标数据导出到文件,导出时添加了@s选项忽略字段名。执行上面网格的剩余代码后,再次查看文件employee1.txt,数据如下:

在数据分析处理中,CSV文件是比较常用的,这种文件常为逗号分隔的文本文件,在使用逗号作为分隔符时,可以在export函数中指定,也可以添加@c选项,表示用逗号作为分隔符,如:
|
|
A |
|
1 |
=file("employee3.csv") |
|
2 |
=create(EID,NAME).record([1,"Frank",2,"Harry"]) |
|
3 |
>A1.export@tc(A2) |
此时输出的文件employee3.csv用Excel及文本工具打开结果分别如下:
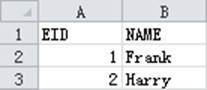

在导入文本文件数据时,也可以添加@c选项使用逗号作为分隔符。
除了使用文本数据,在集算器中还可以使用集文件,只需在export或者import时添加@b选项即可,有关内容将在集文件 中讲述。
分批处理大数据文本文件
当文件中的数据量比较大时,全部读入内存就有可能造成内存溢出,这种时候就需要读取文件中的部分数据。在使用import时,还可以使用分段参数,分段读取数据。如:
|
|
A |
|
1 |
=file("PersonnelInfo.txt") |
|
2 |
=A1.import@t(;100:500) |
|
3 |
=A1.import@t(;101:500) |
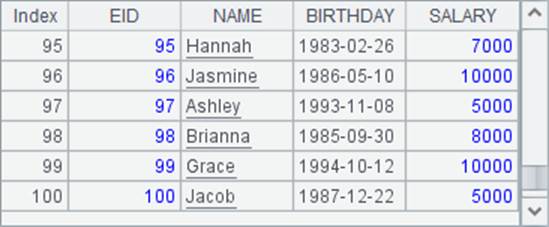
文本文件PersonnelInfo.txt中,存储了一批员工资料。A2和A3在使用import函数时,在分号后添加了分段参数,如100:500,此时A2读取数据时,将数据分为500份,读取其中的第100份,结果如下:

A3中继续读取第101份,结果如下:
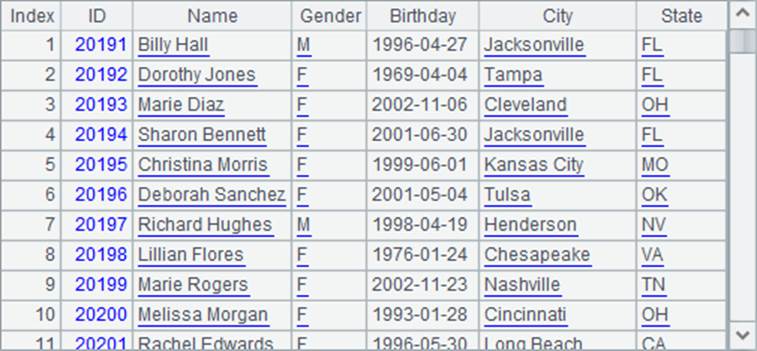
可以发现,在分块读取时,集算器也会调整位置使得读取时整条读入记录,同时保证读取时数据的连续性,避免出现重复或遗漏。
需要注意的是,在import函数中,用分段的方法来分多次从文件中读取数据时,由于每条记录占用的字节数不定,因此每次读到的数据条数也是有变化的。由于同样的原因,也是无法直接获取指定某行的数据的。如果想找到指定位置的某行记录,只有遍历读取它前面的所有数据,效率低下。如果需要精确访问记录,可以使用外存文件游标来处理,将在下一节内容中介绍。
将大数据文件分段,这样就可以把单文件的计算任务拆分为多个子任务执行。因此,分段读取数据对于集群计算很有意义,在服务器 中,将讲解如何在集群计算中分批处理大数据文件。
在面对大数据的计算时,在输出数据到文本文件时,同样会受到内存的限制。由于数据无法一次读入到内存,也就不能简单export到某个文件。对于大数据的输出,同样可以分批处理,使用时需要在export函数中添加@a选项,每次输出时,都在已有的数据后面添加导出。如:
|
|
A |
B |
|
1 |
=file("PersonnelInfo.txt") |
=file("PersonnelInfo1.txt") |
|
2 |
for 500 |
=A1 .import@t(ID,Name,State;A2:500,) |
|
3 |
|
>B1.export@at(B2) |
在A2中执行循环,分500次读出PersonnelInfo.txt中的数据,并选择部分字段存储到新文件PersonnelInfo1.txt中。在存储时,添加了@at选项,输出列名,同时每次写数据时都用附加的方式。执行后,文件PersonnelInfo1.txt中数据如下:
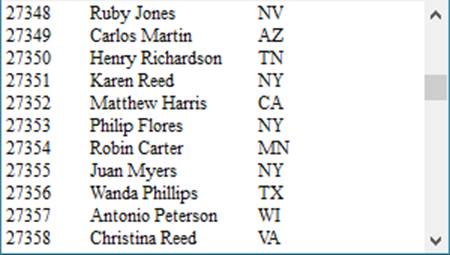
如果没有添加@a选项,在输出时则会把文件中原有数据清除。
使用游标访问大数据文本文件
在处理大数据文本文件时,更方便的用法是使用游标。用文本文件生成外存文件游标后,就可以方便地调用各种游标函数了。如:
|
|
A |
|
1 |
=file("PersonnelInfo.txt") |
|
2 |
=A1.cursor@t(ID,Name,Gender,State) |
|
3 |
>A2.skip(10000) |
|
4 |
=A2.fetch(1000) |
|
5 |
=A2.fetch(1000) |
|
6 |
>A2.close() |
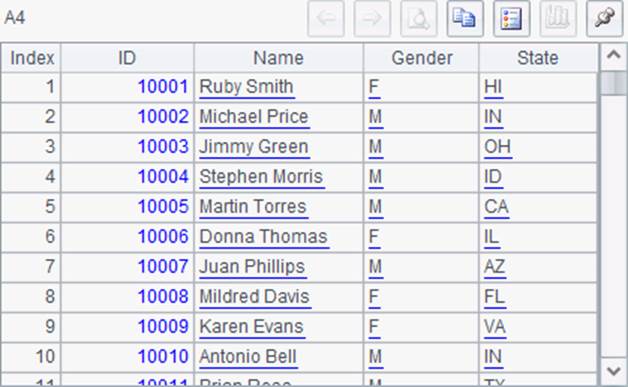
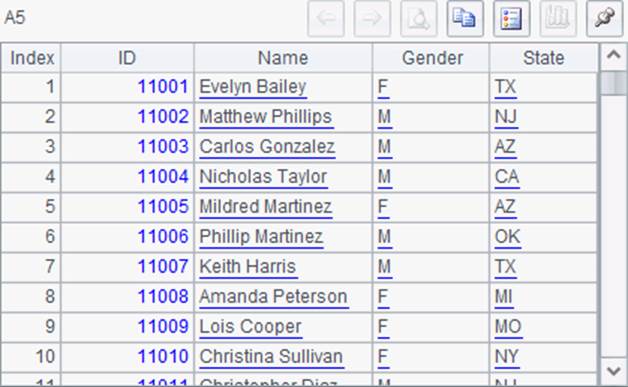
A2中用cursor函数创建文件游标,其中添加@t选项将文件中的第1行作为列名。在A3中跳过前10,000条记录,接着在A4和A5中各读出1,000条记录如下:
使用游标,可以方便快捷地按位置读取数据。在使用f.cursor() 生成游标时,与第1节中介绍的f.import() 类似,也可以选择所需的字段,或者指定某个字段的数据类型。
在生成外存文件游标后,就可以很方便地做各类运算,具体使用可以阅读游标使用,以及有关集算器外存计算的其它文章。
使用游标,也可以将数据输出到文件,如:
|
|
A |
|
1 |
=file("employee2.txt") |
|
2 |
=demo.cursor("select * from EMPLOYEE") |
|
3 |
>A1.export@t(A2,EID,NAME+" "+SURNAME:FullName,GENDER,STATE) |
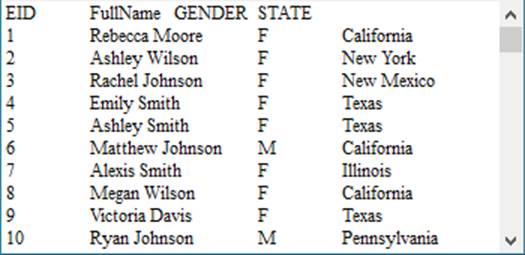
在A2中生成数据库游标,在A3中根据游标中的数据计算出需要的结果,输出到文件中。执行后,文件employee2.txt中的数据如下:
将游标中的数据输出,代码简洁,使用方便。如果在输出时,需要保留文件中已存在的数据,也可以添加@a选项,追加写出。
在集算器中,除了使用文本数据之外,还可以使用集文件数据。集文件占用的内存更小,使用时效率更高,关于集文件的使用,请阅读集文件。