
json
作为常见的数据交换格式,json格式的数据可能自于外部Java程序、本地文件或者http服务器。集算器可以很简便的解析和计算json格式字符串。
这里通过几个例子来看一下,集算器脚本具体的写法。
首先看json字符串从外部Java程序以参数的形式传入的情况。
例如:待处理字符串是json格式的员工信息,包含EID、NAME、SURNAME、GENDER、STATE、BIRTHDAY、HIREDATE、DEPT等字段,这个例子要解析数据,按条件找出1981年1月1日(含)之后出生的女员工。Json字符串内容如下:
[{EID:1,NAME:"Rebecca",SURNAME:"Moore",GENDER:"F",STATE:"California ",BIRTHDAY:1974-11-20,HIREDATE:2005-03-11,DEPT:"R&D",SALARY:7000},
{EID:2,NAME:"Ashley",SURNAME:"Wilson",GENDER:"F",STATE:"New York",BIRTHDAY:1980-07-19,HIREDATE:2008-03-16,DEPT:"Finance",SALARY:11000},
{EID:3,NAME:"Rachel",SURNAME:"Johnson",GENDER:"F",STATE:"New Mexico",BIRTHDAY:1970-12-17,HIREDATE:2010-12-01,DEPT:"Sales",SALARY:9000},…]
实现的思路是:Java程序调用集算器程序并传入json字符串,集算器解析json格式数据完成条件过滤,之后将结果以json字符串的方式返回给Java程序。
需要查询1981年1月1日(含)之后出生的女员工,esProc程序可以从外部获得两个输入参数“jsonstr”和“where”条件,如下图:
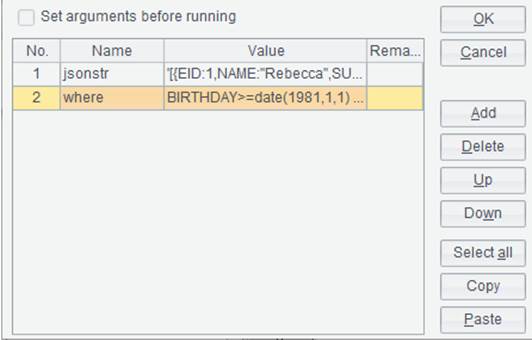
where是个字串,其值是:BIRTHDAY>=date(1981,1,1) && GENDER=="F"。
注意:jsonstr是个字串,输入值时需要在json字符串前添加单引号'表示其类型是字符串。
esProc代码如下:
|
|
A |
|
|
1 |
=json(jsonstr) |
|
|
2 |
=A1.select(${where}) |
|
|
3 |
=A2.export@j() |
[{EID:4,NAME:"Emily",SURNAME:"Smith",GENDER:"F",STATE:"Texas",BIRTHDAY:1985-03-07,HIREDATE:2006-08-15,DEPT:"HR",SALARY:7000}…] |
|
4 |
return A3 |
|


A1:把json格式数据解析成序表。esProc的集成开发环境可以直观的显示出计算结果,如上图右边部分。
A2:按照条件过滤。这里使用宏来实现动态解析表达式,其中的where就是传入参数。集算器先计算${…}里的表达式,将计算结果作为宏字符串值替换${…}之后解释执行。这个例子中最终执行的是:=A1.select(BIRTHDAY>=date(1981,1,1) && GENDER=="F")。
A3:将过滤之后的序表生成json格式字符串。
A4:向外部程序返回符合条件的结果集。
在Java程序中调用上述esProc脚本的方法,参见esProc教程。
再看json数据来自HTTP服务器的情况。假设有一个testServlet可以返回json格式的员工信息字符串,可以用下面的代码获取、计算:
|
|
A |
|
1 |
=httpfile("http://localhost:6080/myweb/servlet/testServlet?table=employee&type=json") |
|
2 |
=A1.read() |
|
3 |
=json(A2) |
|
4 |
=A3.select(${where}) |
|
5 |
=json(A4) |
|
6 |
return A5 |
A1:定义了httpfile对象,url是:http://localhost:6080/myweb/servlet/testServlet?table=employee&type=json
A2:读取httpfile对象返回的结果。
A3:解析json格式字符串,生成一个序表。
A4:按照条件过滤数据。
A5:将过滤后的序表转换为json格式字符串,json函数将自动判断参数类型,执行json串的导入或导出。
A6:将A4中的结果返回给调用这段集算器程序的Java代码。
最后,如果json格式数据包含嵌套对象,集算器也可以解析、计算。例如:json格式的blog信息中嵌套的评论信息,集算器可以解析为字段引用。Blogs.json文件数据内容如下:
[
{ "id" : 1000,
"content" : "It is too hot",
"comment" :
[
{
"author" : "joe",
"score" : 3,
"comment" : "just so so!"
},
{
"author" : "jimmy",
"score" : 5, "comment" : "cool! good!"
}
]
},
{ "id" : 1001,
"content" : "It is too cold",
"comment" :
[
{
"author" : "james",
"score" : 1,
"comment" : "yes!"
},
{
"author": "jimmy",
"score" : 5,
"comment" : "cool!"
}
]
},
{ "id" : 1002,
"content" : "It is windy day today",
"comment" :
[
{
"author" : "tom",
"score" : 3,
"comment" : "I do not thinkso!"
},
{
"author" : "jimmy",
"score" : 5,
"comment" : "cool!"
}
]
}
]
使用集算器编辑器编写脚本读取json格式文件,解析内容并完成计算的脚本如下:
|
|
A |
|
1 |
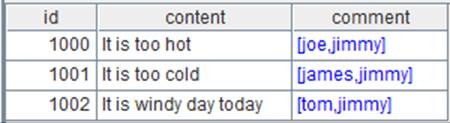
=json(file("D:/files/work/txt/blogs.json").read()) |
取出结果序表后发现,comment字段是个引用字段,引用了一个序表,如下图:
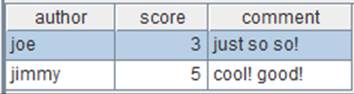
当我们双击第一行蓝色部分的时候,可以详细查看这个引用序表,如下图:
对于这个带引用字段的序表,集算器可以进一步进行复杂的集合运算。