跨网游标
在游标概念中,我们初步了解了跨网游标的使用。在这里,将继续研究跨网格使用游标时的一些问题。
跨网格游标基本使用
跨网游标通常用来处理大数据的分析计算,但是对数据量并没有硬性要求,我们先来用较少的数据来了解跨网游标的使用。例如,网格D:\files\FindEmployees1.splx如下:
|
|
A |
|
1 |
$(demo) select * from EMPLOYEE where DEPT = ?;arg1 |
|
2 |
>output("before return") |
|
3 |
return A1 |
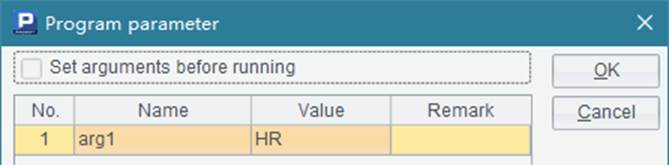
网格中的程序比较简单,从数据库中查询出某个部门的员工数据,并在A3中用return语句返回结果序表。另外,在A2中用output() 函数向控制台输出了信息以便了解代码的执行情况。在A1中用到了参数arg1,这是一个网格参数,用来设定部门名称,需要在菜单栏中点击Program>Parameter设置:
在子程序中,讲述了用call函数执行其它网格文件中程序的方法,跨网格游标的使用与其类似,只是需用cursor来返回游标。在主网格中调用如下:
|
|
A |
|
1 |
=cursor("FindEmployees1.splx";"Sales") |
|
2 |
>output("before fetch") |
|
3 |
=A1.fetch() |
在用cursor生成跨网游标时,直接指定所调用的脚本文件名,如果需要使用参数,写在网格文件后面,用分号分隔。执行后,A1中的数据是跨网游标,它的使用与普通的游标相同:

A3中用fetch返回了销售部的员工序表:
在两个网格中,都使用了output函数,这个函数会在执行时将字符输出到后台,有助于我们了解网格的执行顺序。在菜单栏中选择Tool> Options,并在Option窗口的General页面中选定Console takeover,查看控制台输出情况如下:
可见,在跨网游标计算时,当真正开始用fetch取数时,才会调用指定网格中的程序开始计算。
在A1中调用脚本文件时,并未使用全路径,此时文件需置于集算器的主路径或者寻址路径中。主路径及寻址路径的设定,与用call函数跨网格调用时的设定是相同的,在下面再说明一下。
在菜单栏中点击Tool>Options,在选项设定的Environment页面中,可以设定主路径和寻址路径,如:

在上面的设置中,脚本文件置于主路径Main Path中,或者寻址路径Searching Path的任何一个目录中,在调用时,都可以只用文件名,而不用写全路径。
如果是被集成使用时,则需要在配置文件raqsoftConfig.xml中,设置主路径与寻址路径:
<splPathList>
<splPath>E:\tools\raqsoft\esProc\demo\Case\Structural</splPath>
<splPath>D:\files\txt;D:\files</splPath>
</splPathList>
<mainPath>D:\files\demo</mainPath>
返回多个结果的网格
在跨网游标调用的网格文件中,有可能会返回多个结果。如D:\files\FindEmployees2.splx如下:
|
|
A |
|
1 |
$(demo) select * from EMPLOYEE where DEPT = ?;arg1 |
|
2 |
return A1.select(GENDER=="F") |
|
3 |
return A1.select(GENDER=="M") |
在网格中,从数据库中查询出某个部门的员工数据,并在A2中用return语句返回其中女员工构成的排列,在A3中用return语句返回其中男员工构成的排列。网格参数和上一节中的设定相同。
在主网格中调用跨网游标如下:
|
|
A |
|
1 |
=cursor("FindEmployees2.splx") |
|
2 |
=A1.fetch() |
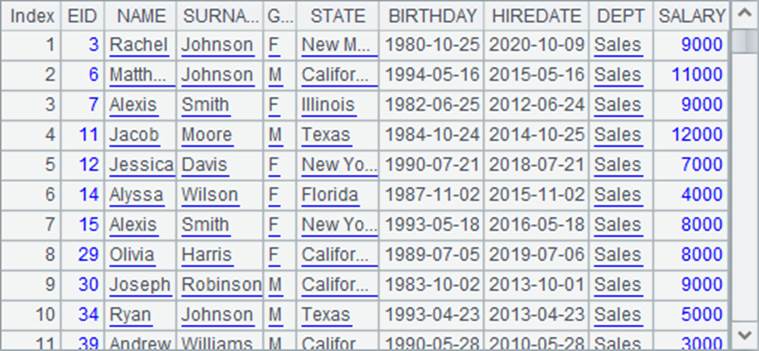
在调用cursor生成跨网游标时,如果没有使用参数,计算时将使用网格参数的默认值。即查询部门HR的数据。执行后,A2中返回的结果如下:

结果序表中,前半部分是人力资源部女员工的数据,后半部分是人力资源部男员工的数据。从结果中可以看到,当调用的网格用多个return语句返回了多个结果时,在使用跨网游标时,会将各个结果依次拼接在一起。
由于调用返回多个结果的网格时,返回的结果会被同一个游标返回,因此,返回的所有结果必须具有相同的数据结构,否则会产生错误。
为了更清楚地了解执行情况,在被调用的网格中添加output语句,修改为D:\files\FindEmployees3.splx如下:
|
|
A |
|
1 |
$(demo) select * from EMPLOYEE where DEPT = ?;arg1 |
|
2 |
>output("return GENDER F") |
|
3 |
return A1.select(GENDER=="F") |
|
4 |
>output("return GENDER M") |
|
5 |
return A1.select(GENDER=="M") |
在网格中,从数据库中查询出某个部门的员工数据,并在A2中用return语句返回其中女员工构成的排列,在A3中用return语句返回其中男员工构成的排列。网格参数和上一节中的设定相同。
调用跨网游标如下:
|
|
A |
B |
|
1 |
=cursor("FindEmployees3.splx") |
[] |
|
2 |
for A1,5 |
>output("fetch"+string(#A2)) |
|
3 |
|
>B1=B1|A2 |
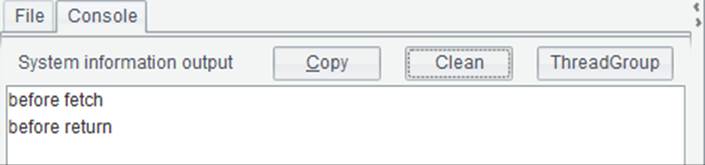
在这里跨网游标中的数据量很少,只是为了说明游标的调用情况。在A2中循环游标中的数据,每次获取5条记录,循环时,在B2中输出信息,在B3中将游标中返回的数据拼到B1的排列中。执行后B1中的数据与前面的结果是相同的,仍然是人力资源部中女员工与男员工组成的数据。控制台中的输出结果如下:
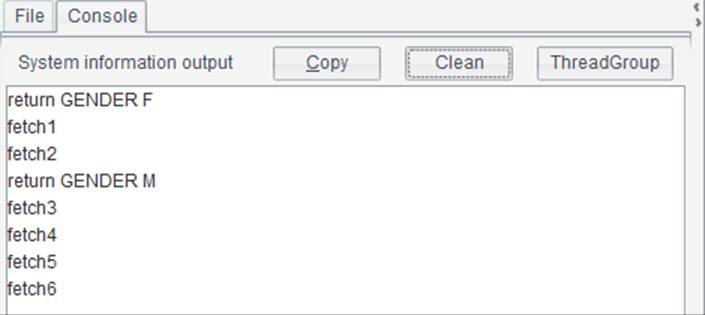
从输出结果中可以看到,在FindEmployees3.splx被主网格调用时,会根据需要返回的记录数,逐步执行。当A3中女员工的记录全部返回之后,才会继续向后执行,返回男员工数据。
在循环中返回数据的网格
当跨网游标中需要返回大量数据时,可以通过返回多个结果的方式,逐步用return返回结果,由主网格将它们合并。但是,处理大数据时,更为常用的方法是使用游标,在被调用的网格中通过循环逐步返回游标中的数据,在主网格读取数据时会自动将结果合并。如D:\files\Order1.splx如下:
|
|
A |
B |
|
1 |
=file("Order_Books.txt") |
=A1.cursor@t() |
|
2 |
for B1,5000 |
return A2 |
在A2中循环读取游标中的数据,然后在B2中用return返回每一次fetch的结果构成的序表,而不是前面例子中那样一次返回所有的序表或排列。
在主网格中,跨网游标的使用和前面的方法是完全相同的:
|
|
A |
|
1 |
=cursor("Order1.splx") |
|
2 |
=A1.fetch(1000) |
|
3 |
>A1.close() |
跨网游标返回的数据较多,在A2中仅读出前1000条如下:
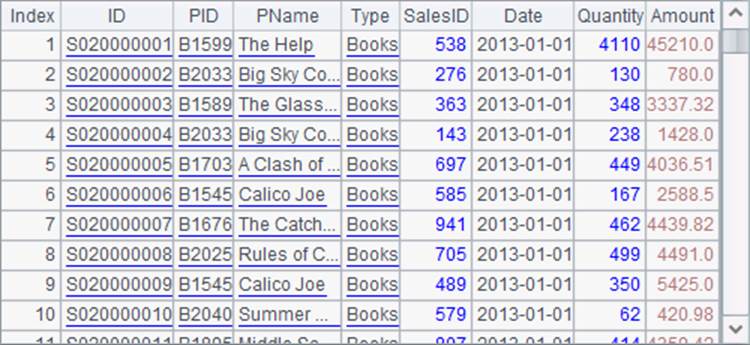
由于数据未全部读完,因此在A3中关闭游标。当跨网游标被关闭时,被调用网格中的游标也会被关闭。
在返回游标时,也可以用多个return返回多个结果,此时各个游标中的数据也会被拼接在一起读出,与返回多个排列时的情况一样。因此,多个游标中的数据也需要具有相同的数据结构。
跨网游标的实际应用
跨网游标中通过调用网格执行计算,将结果返回成游标使用,这样,就可以利用网格中的代码解决一些比较复杂的数据处理工作。比如,在大数据分析处理中,经常会使用文本数据作为源数据。文本数据并不像数据库中的数据一样有着严格的规范,经常需要用程序去整理,此时使用跨网游标。
下面是D:\files\EmployeeMul.txt中的员工数据:
|
1 |
Nicole Jones |
F |
2009-08-01 |
|
1990-01-03 |
Philadelphia |
Pennsylvania |
Production |
|
36801 |
NicoleJones_PA@mail.xxx |
|
|
|
2 |
Tammy Powell |
F |
2010-09-29 |
|
1992-07-31 |
Pittsburgh |
Pennsylvania |
Technology |
|
43711 |
TammyPowell2@mail.xxx |
|
|
|
3 |
Jack Anderson |
M |
2007-04-12 |
|
1984-08-26 |
Cleveland |
Ohio |
R&D |
|
36094 |
JackAnderson_OH@mail.xxx |
|
|
|
4 |
Margaret Morales |
F |
2014-03-18 |
|
1992-11-12 |
Washington |
Washington |
Sales |
|
48983 |
MargaretMorales4@mail.xxx |
|
|
|
5 |
Willie Roberts |
M |
2012-07-06 |
|
1988-07-01 |
Plano |
Texas |
Technology |
|
43711 |
WillieRoberts5@mail.xxx |
|
|
|
6 |
Todd Gray |
M |
2009-01-04 |
|
1981-09-06 |
Baltimore |
Maryland |
R&D |
|
36094 |
ToddGray_MD@mail.xxx |
|
|
|
7 |
Kevin White |
M |
2007-04-19 |
|
1986-07-10 |
Minneapolis |
Minnesota |
Technology |
|
43711 |
KevinWhite_MN@mail.xxx |
|
|
|
…... |
|
|
|
在这个文本数据中,每位员工的数据分为3行,包括员工编号、姓名、性别、录用日期、生日、所在城市等信息。将字段较多的一条记录拆分为多行,这样的存储方式,在文本数据中比较常见。现在,需要从中选择出费城的员工资料。
由于在集算器中直接引入文本数据作为序表或游标时,是要求文件中的每行数据作为1条记录的,因此这样的文本数据不能直接使用。如果需要根据EmployeeMul.txt中的数据来分析计算,需要将数据重新整合。此时,如果使用跨网游标,则能使问题变得更为直观。首先,在mergeRecord.splx中处理数据:
|
|
A |
B |
C |
D |
|
1 |
=file("EmployeeMul.txt").cursor() |
|
|
|
|
2 |
for A1,5000*3 |
=A2. step(3,1) |
=A2. step(3,2) |
=A2. step(3,3) |
|
3 |
|
=join@p(B2:L1;C2:L2;D2:L3) |
=B3.new(L1.#1:ID,L1.#2:Name,L1.#3:Gender, L1.#4:EntryDate,L2.#1:Birthday,L2.#2:City, L2.#3:State,L2.#4:Dept,L3.#1:SuperiorID, L3.#2:MailAdress) |
|
|
4 |
|
return C3 |
|
|
在A1中,将文本文件读为游标。在A2中每次读取5000*3条记录,并在语句块中将数据合并。其中,在每3条记录中,B2取出第1条记录构成排列,C2取出第2条记录构成排列,D2取出第3条记录构成排列。B2,C2和D2在最后一次循环中获取的数据分别如下:
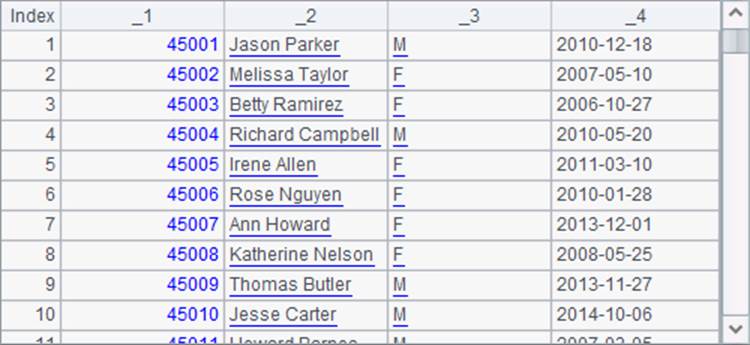
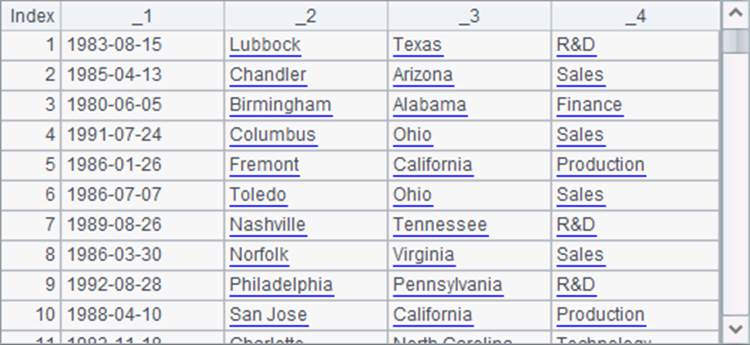
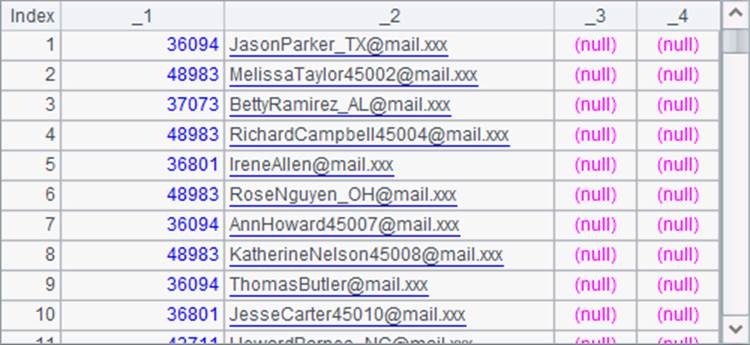
其中,D2中的数据只有前两列有效。在B3中,用join@p函数将上面三个序表中的记录横向连接:
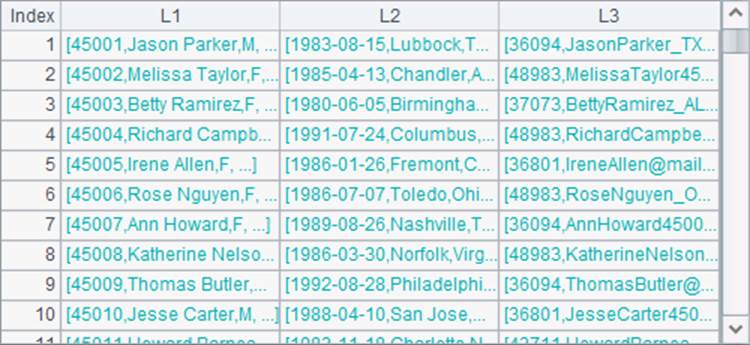
这样,在C3中就可以使用这些初始数据,生成所需的记录了:

通过跨网游标调用mergeRecord.splx,就能简单完成所需处理的计算:
|
|
A |
|
1 |
=cursor("mergeRecord.splx") |
|
2 |
=A1.select(City=="Philadelphia") |
|
3 |
=A2.fetch() |
通过跨网游标,将较复杂的多行记录处理在子网格中完成,使得程序目的明确,简洁易读。同时,用游标来操作,可以很方便地完成大数据文件的分析计算。例子中的数据量并不很大,在A3中,一次读出所有费城的员工数据如下:
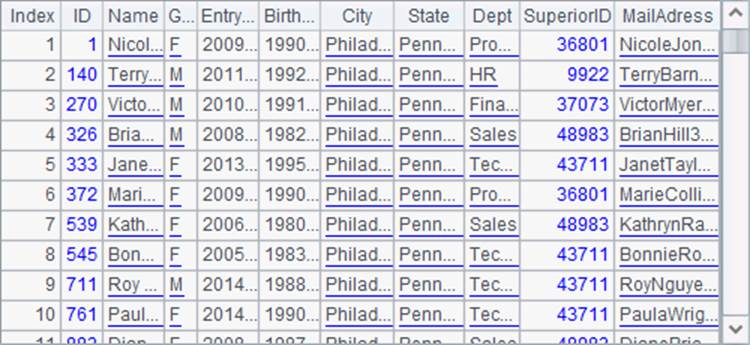
有时,存储在文本中的数据,不仅需要将多行数据合并为一条记录,同时结构也更为复杂。如下面的D:\files\mailInfo.txt:

文档中,简单存储了一些邮件的内容,包括收件人地址,发件人地址及邮件正文,分别用RECIPIENT:,SENDADDRESS:和CONTENT:作为开头。其中,邮件正文的行数是不定的,因此这样的数据无法读出指定行数的数据合并处理,更无法直接使用。在集算器中,同样可以使用跨网游标,先在readMail.splx中处理数据:
|
|
A |
B |
C |
|
1 |
=file("mailInfo.txt").cursor@s() |
>A1.skip(2) |
="" |
|
2 |
for A1,5000 |
=C1+A2.(#1).concat("\r\n") |
=B2.split("RECIPIENT:") |
|
3 |
|
if A1.fetch@0(1) |
=C2.len() |
|
4 |
|
|
>C1="RECIPIENT:"+ C2(C3)+"\r\n" |
|
5 |
|
|
>C2=C2.to(2,C3-1) |
|
6 |
|
else |
>C2=C2.to(2) |
|
7 |
|
=C2.regex("(.+)[\\s\\S]+" +"SENDADDRESS:(.+)[\\s\\S]+ " +"CONTENT:([\\s\\S]+)"; Recipient,SendAddress,Content) |
|
|
8 |
|
return B7 |
|
A1中用文本文件建立游标。由于文本中前两行数据无效,因此在B1中跳过。由于文件数据中,到底多少行数据正好能够构成一条记录是无法确定的,因此需要考虑,C1中存储循环时未处理的剩余数据。
在A2中,循环读取游标,每次处理5000行数据。在B2中,读入的数据连接成一个大字符串,如果上次循环中有未处理的数据,置于数据最前方。每条邮件记录都是以RECIPIENT:开始的,因此在C2中根据这一点将大字符串按邮件拆分。在刚拆分完的序列中,第一个成员将是空行,而最后一个数据无法确定是否已读取完成。因此在3~7行继续处理数据。在B3中的cs.fetch@0()使用了@0选项,此时并不会实际取数,而是判断游标中的数据是否已全部读出。如果未读取完成,则将最后的数据存储在C1中。如处理第一批数据时,B2和C2中数据分别如下:

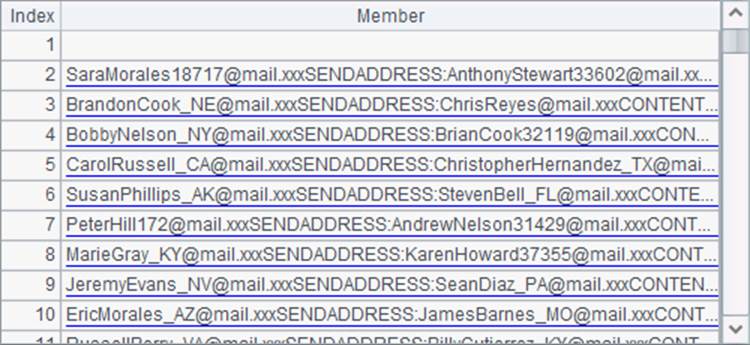
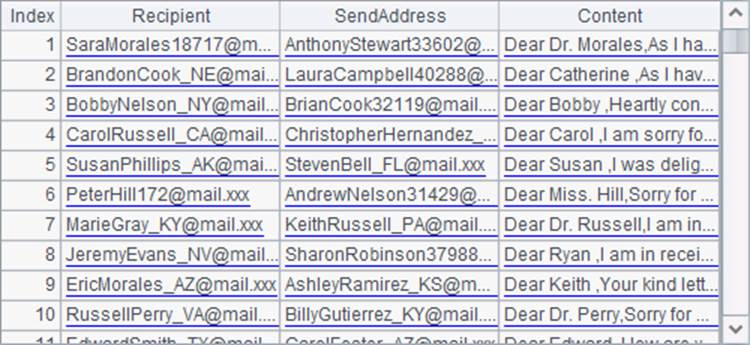
在B7中,将C2中的每条数据用regex函数进行正则表达式解析,根据剩余的关键字SENDADDRESS:和CONTENT:读取出所需数据作为字段。这里用到的正则表达式串比较长,为便于查看拆分为了多个字符串相加。在处理第一批数据时,解析后B7中的结果如下:
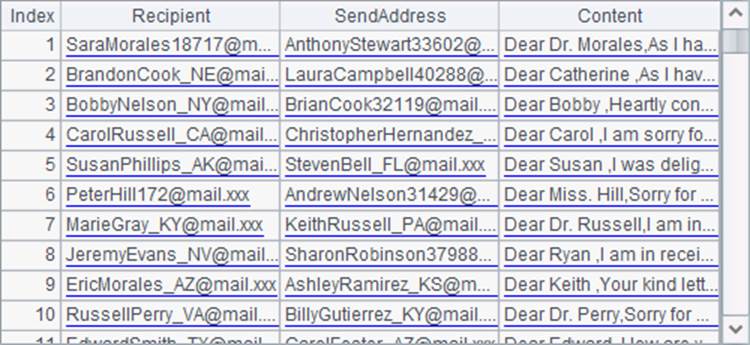
在B8中将每次的解析结果返回主程序。
这样,无论数据解析的过程多么复杂,在主程序中都只需要通过简单的跨网游标代码读取数据,和普通的游标数据使用起来没有什么区别:
|
|
A |
|
1 |
=cursor("readMail.splx") |
|
2 |
=A1.fetch(1000) |
|
3 |
>A1.close() |
在A2中读取出前1000条数据如下: