使用 SQL
在集算器中,可以使用SQL从数据库中获取数据,更可以利用初始的数据库查询结果,进一步分析计算,解决一些只用SQL难以处理的复杂问题。
数据库的连接与断开
用SQL访问数据库,首先要连接到指定的数据库。连接数据库通常可以选择两种方式:在数据源管理器中直接连接,或者在网格中调用函数连接。
|
|
A |
|
1 |
=connect("demo") |
在使用时,数据源管理器中连接的数据库,直接使用数据源名调用,在数据连接未断开时有效;而通过函数连接的,生成的连接对象会作为单元格值存储,可以使用单元格名调用,在调用的连接对象关闭之前有效。
|
|
A |
|
1 |
=connect("demo") |
|
2 |
=demo.query("select * from STATES") |
|
3 |
=A1.query("select * from STATES") |
|
4 |
>A1.close() |
同样,数据库连接的断开,也有两种方式,除了上面调用db.close()函数之外,还可以在数据源管理器中关闭选定数据源:

SQL 的简单使用
使用db.query()函数即可在指定数据库中执行SQL命令。在SQL语句中,可以包含各种查询子句以及数据库函数。
|
|
A |
|
1 |
=connect("demo") |
|
2 |
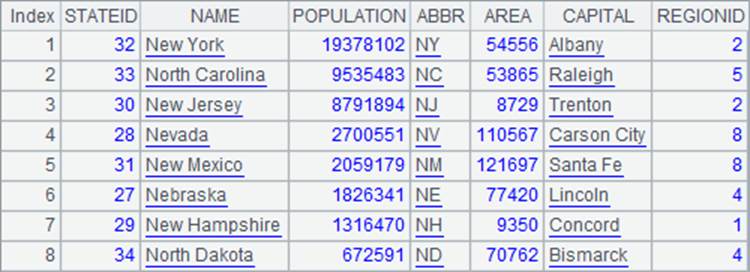
=A1.query("select * from STATES where ABBR like 'N%' order by POPULATION desc") |
|
3 |
>A1.close() |
A2中查询缩写以N开头的州,并按人口降序排序,结果如下:
在SQL语句中,也可以使用网格中的其它数据作为参数:
|
|
A |
|
1 |
=connect("demo") |
|
2 |
[CA,ME,NM,SC,LA] |
|
3 |
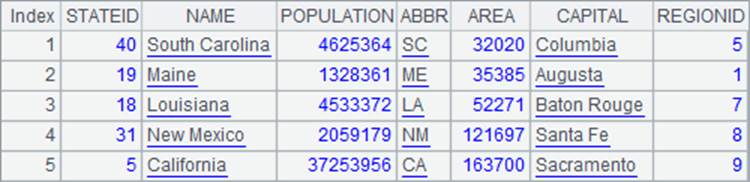
=A1.query("select * from STATES where ABBR in (?) order by AREA",A2) |
|
4 |
>A1.close() |
A3中查询缩写在指定序列内的州,并按面积升序排序,结果如下:
特别的,在使用query函数返回查询结果时,可以添加@1选项只返回第1条记录。此时,通常将返回一个序列作为结果,把第1条记录中各列的值,作为这个序列的成员。当只有1个字段时,则返回单值。如:
|
|
A |
|
1 |
=demo.query@1("select * from CITIES") |
|
2 |
=demo.query@1("select NAME from CITIES where STATEID=5") |
添加@1选项后,A1和A2中结果如下:
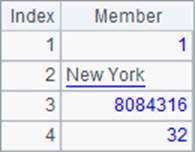

需要注意的是,此时返回值为单值或者序列,而不是序表。
无返回值的 SQL
如果需要通过SQL对数据库操作,而没有返回的结果集,如使用create、update、delete等SQL语句。那么在执行时需要使用db.execute()函数,同时,由于不需要对单元格赋值,在表达式开头使用">"代替"="。如:
|
|
A |
|
1 |
=connect("demo") |
|
2 |
>A1.execute("update STATES set ABBR='CAA' where ABBR='CA'") |
|
3 |
=A1.query("select * from STATES where NAME = 'California'") |
|
4 |
>A1.close() |
A2中的语句修改数据库表STATES中的记录后,A3中查询到的结果如下:

在无返回值的SQL中,也是可以使用参数的:
|
|
A |
|
1 |
=connect("demo") |
|
2 |
CA |
|
3 |
CAA |
|
4 |
>A1.execute("update STATES set ABBR=? where ABBR=?",A2,A3) |
|
5 |
=A1.query("select * from STATES where NAME = 'California'") |
|
6 |
>A1.close() |
A4中的语句将数据库表STATES中刚刚被修改的记录改回原值,A5中查询到的结果如下:

在单元格中直接使用 SQL
除了使用db.query(sql)函数和db.execute(sql)函数,在集算器中还可以用$(db)sql;…直接执行SQL。如果(db)省略,则取之前最后一次使用的数据库连接。其中的sql语句可以带参数,写在分号后面即可。用这种方法时,使用sql语句时不在前方加等号,也不必将语句用引号标记,但是不再支持使用@1选项。此时,不需再用execute或者query函数来区分是否返回结果集。其中select语句会返回结果集,其它语句会各自返回不同的值。如:
|
|
A |
|
1 |
$(demo)select * from STATES where ABBR like 'N%' order by POPULATION desc |
|
2 |
[CA,ME,NM,SC,LA] |
|
3 |
$select * from STATES where ABBR in (?) order by AREA;A2 |
这里的代码,和SQL的简单使用中代码的效果是相同的,执行结果完全一样。其中A3格中并未指明数据源的名称,取之前最后使用的数据连接,仍然是(demo)。
再来看看下面的情况:
|
|
A |
|
1 |
$(demo) create table TESTTEMP (ID int, NAME varchar(20)) |
|
2 |
$(demo) insert into TESTTEMP values (2,'Tom Smith') |
|
3 |
=demo.query("select * from TESTTEMP") |
|
4 |
$(demo)update TESTTEMP set NAME='Jane White' where ID=2 |
|
5 |
=demo.query("select * from TESTTEMP") |
|
6 |
$(demo)drop table TESTTEMP |
A1中新建一个序表,A2中插入1条记录。A4中修改记录中的数据,A6中删除序表。在A3与A5中查询到的数据库更新情况如下:
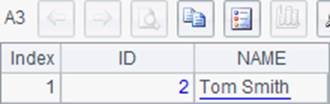
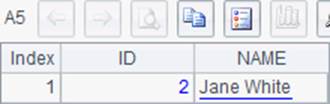
需要注意的是A1,A2,A5和A6中的代码虽然都是执行语句,但都有了返回值,这和上一节中的情况似乎有所不同。我们来看一下返回的结果:
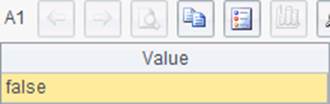
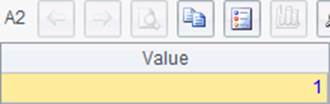
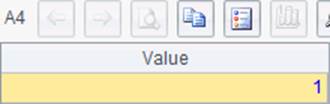
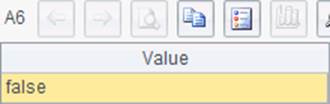
其中,A1和A6中的结果表示SQL语句未返回结果集。A2和A4中的结果表示更新了1条记录。
使用$(db)sql;…的格式,可以使代码更为简洁,但是需要注意使用参数时需要用分号分隔,同时需要区分返回结果的不同。
利用 SQL 的查询结果
在集算器中,可以利用SQL的查询结果,进行过滤、排序、组合等等操作,以提高查询效率,或者解决一些比较复杂的问题。
下面的例子都是在数据源管理器中连接demo数据源,基于A1格中的查询结果做的:
|
|
A |
|
1 |
=demo.query("select * from STATES order by POPULATION desc") |
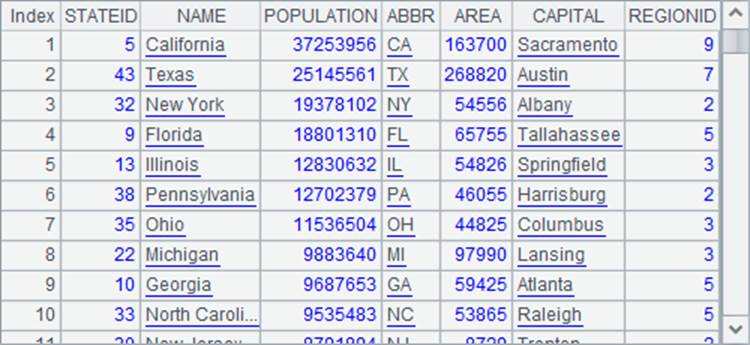
如,对数据过滤,检索指定缩写的州数据:
|
|
A |
|
1 |
=demo.query("select * from STATES order by POPULATION desc") |
|
2 |
[CA,ME,NM,SC,LA] |
|
3 |
=A1.select(A2.pos(ABBR)>0) |
|
4 |
=A1.select(A2.contain(ABBR)) |
A3中用A2.pos(ABBR)>0来判断一个州的缩写是否在指定序列中。判断某个数据是否是指定序列的成员,也可以用A.contain(x) 函数,A3和A4中的表达式是等价的,运算结果也是相同的,如下:
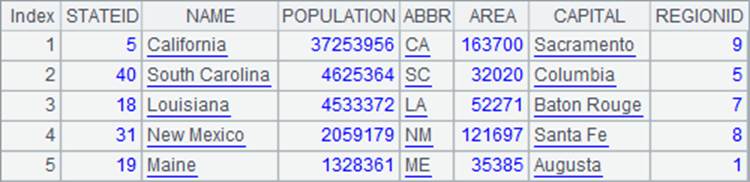
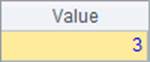
还可以对数据聚合计算,如统计缩写以C开头的州共有多少个:
|
|
A |
|
1 |
=demo.query("select * from STATES order by POPULATION desc") |
|
2 |
=A1.count(left(ABBR,1)=="C") |
更有意义的,就是对数据库数据按要求分组,如按照缩写的首字母分组:
|
|
A |
|
1 |
=demo.query("select * from STATES order by POPULATION desc") |
|
2 |
=A1.group(left(ABBR,1)) |
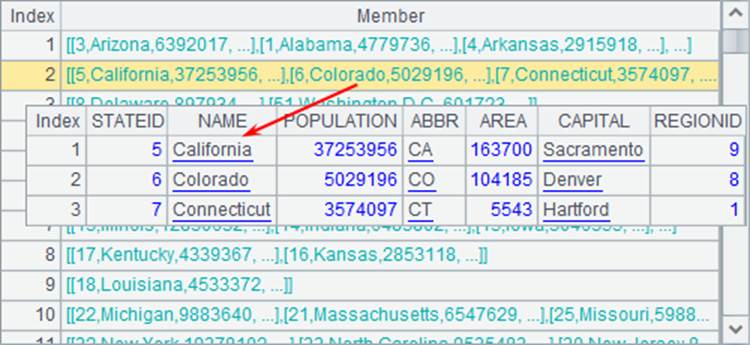
A2按照每个州缩写的首字母分组,其中每一组的数据,都可双击查看内容。
可见,与SQL中未分组汇总服务的“分组”不同,在集算器中对数据的分组是真正的分组,可以在此基础上进行更多的计算。如选出组内州大于等于3个的,计算这些组内的州总数及总人口:
|
|
A |
|
1 |
=demo.query("select * from STATES order by POPULATION desc") |
|
2 |
=A1.group(left(ABBR,1)) |
|
3 |
=A2.select(~.count()>=3) |
|
4 |
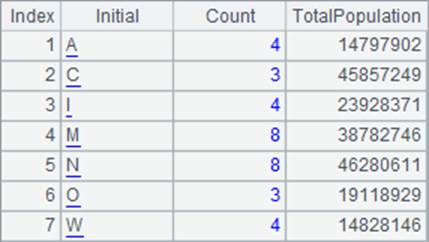
=A3.new(left(ABBR,1):Initial, ~.count():Count, ~.sum(POPULATION):TotalPopulation) |
A4中的最终结果是:
常见的 SQL 语句与集算器语法的对照
1. select * from
|
|
A |
|
1 |
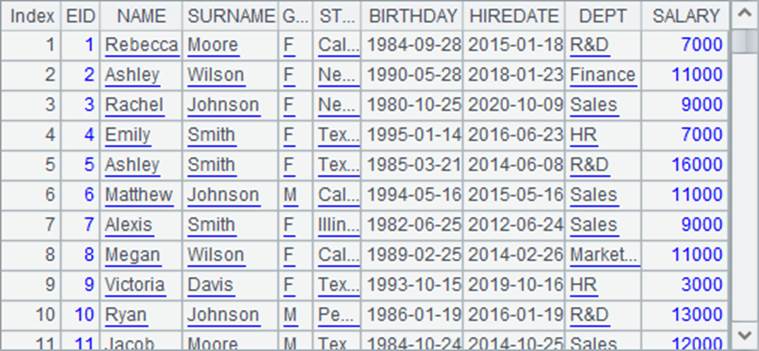
=demo.query("select * from EMPLOYEE") |
查询结果如下:
2. select … from
|
|
A |
|
1 |
=demo.query("select * from EMPLOYEE") |
|
2 |
=A1.new(EID, NAME, SURNAME, GENDER, BIRTHDAY, DEPT) |
|
3 |
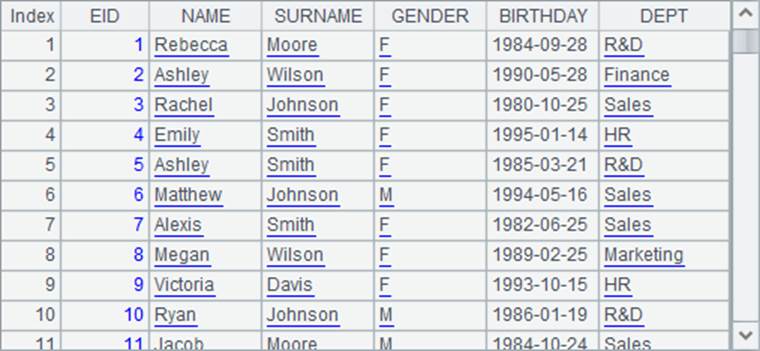
=demo.query("select EID, NAME, SURNAME, GENDER, BIRTHDAY, DEPT from EMPLOYEE") |
从表中取出指定字段,A2与A3中的查询结果是相同的,如下:
3. as
|
|
A |
|
1 |
=demo.query("select * from EMPLOYEE") |
|
2 |
=A1.new(EID, NAME+" "+SURNAME: FULLNAME, GENDER, age(BIRTHDAY):AGE, DEPT) |
|
3 |
=demo.query("select EID, NAME+' '+SURNAME as FULLNAME, GENDER, year(now())-year(BIRTHDAY) as AGE, DEPT from EMPLOYEE") |
根据名(NAME)和姓(SURNAME)计算出全名(FULLNAME),同时根据生日(BIRTHDAY)计算出年龄(AGE),A2与A3中的查询结果基本是相同的,如下:

需要注意的是,A3中,计算年龄时只是简单用年相减,由于SQL没有直接计算年龄的函数,准确计算会更复杂。
4. where
|
|
A |
|
1 |
=demo.query("select * from EMPLOYEE") |
|
2 |
=A1.new(EID, NAME+" "+SURNAME: FULLNAME, GENDER, age(BIRTHDAY):AGE, DEPT) |
|
3 |
=A2.select(AGE<35) |
|
4 |
=demo.query("select EID, NAME+' '+SURNAME as FULLNAME, GENDER, year(now())-year(BIRTHDAY) as AGE, DEPT from EMPLOYEE where year(now())-year(BIRTHDAY)<30") |
查询年龄小于35岁的员工,在集算器中,可以利用已有的结果计算,A3中查询结果如下:

A4中用SQL查询同样的结果,语法就复杂得多,而且在这里由于计算年龄时不精确,因此结果也存在误差。
5. count、sum、avg、max和min
|
|
A |
|
1 |
=demo.query("select * from EMPLOYEE") |
|
2 |
=A1.new(EID, NAME+" "+SURNAME: FULLNAME, GENDER, age(BIRTHDAY):AGE, DEPT) |
|
3 |
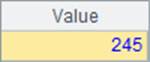
=A2.count(AGE<35) |
|
4 |
=demo.query("select count(EID) from EMPLOYEE where year(now()) - year(BIRTHDAY)-(case when month(now())<month(BIRTHDAY) then 1 WHEN month(now())=month(BIRTHDAY) and day(now())<day(BIRTHDAY) then 1 else 0 end)<35") |
查询年龄小于35岁的员工总数,在集算器中,可以利用已有的结果计算,A3中查询结果如下:
A4中这次用比较精确的方法来计算年龄,获得的查询结果和A3中的一致,但无法利用已有的结果,而语句也复杂得多。
sum、avg、max和min等SQL函数的使用方法和count基本类似。
6. distinct
|
|
A |
|
1 |
=demo.query("select * from EMPLOYEE") |
|
2 |
=A1.id(DEPT) |
|
3 |
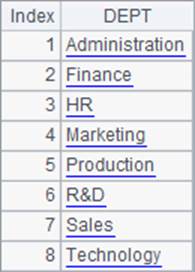
=demo.query("select distinct DEPT from EMPLOYEE") |
查询员工资料来自哪些部门,A2与A3中结果相同,查询结果如下:
7. order by
|
|
A |
|
1 |
=demo.query("select * from EMPLOYEE") |
|
2 |
=A1.new(EID, NAME+" "+SURNAME: FULLNAME, GENDER, age(BIRTHDAY):AGE, DEPT) |
|
3 |
=A2.select(AGE<35).sort(-AGE, FULLNAME ).new(FULLNAME, AGE) |
|
4 |
=demo.query("select FULLNAME, AGE from (select NAME+' '+SURNAME as FULLNAME, year(now())-year(BIRTHDAY)-(case when month(now()) < month(BIRTHDAY) then 1 WHEN month(now())=month(BIRTHDAY) and day(now())<day(BIRTHDAY) then 1 else 0 end) as AGE from EMPLOYEE) where AGE<35 order by AGE desc, FULLNAME") |
查询年龄小于35岁的员工,并按照年龄降序排序,同龄员工按全名升序排序,A3与A4中的查询结果相同,如下:
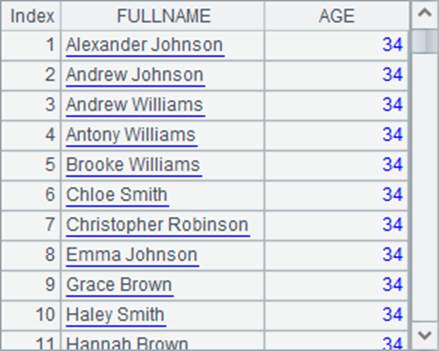
由于SQL中计算年龄比较复杂,而且无法利用已有的结果,A4中这次用嵌套查询来简化语句,但仍然比较复杂。
8. and、or、not和<>
|
|
A |
|
1 |
=demo.query("select * from EMPLOYEE") |
|
2 |
=A1.new(EID, NAME+" "+SURNAME: FULLNAME, GENDER, age(BIRTHDAY):AGE, DEPT) |
|
3 |
=A2.select(AGE<35&& left(FULLNAME,1)== "S" ).new(FULLNAME, AGE) |
|
4 |
=demo.query("select FULLNAME, AGE from (select NAME+' '+SURNAME as FULLNAME, year(now())-year(BIRTHDAY)-(case when month(now()) < month(BIRTHDAY) then 1 WHEN month(now())=month(BIRTHDAY) and day(now())<day(BIRTHDAY) then 1 else 0 end) as AGE from EMPLOYEE) where AGE<35 and left(FULLNAME, 1)='S'") |
查询年龄小于35岁,且全名的首字母是S的员工,结果如下:

可以看到,集算器中,and使用操作符&&来表示,而且,判断是否相等用两个等号==,这和很多程序语言中的习惯相同。与之类似,在集算器中,or使用操作符"||",not使用操作符"!",<>使用操作符"!="。
9. like
|
|
A |
|
1 |
=demo.query("select * from EMPLOYEE") |
|
2 |
=A1.select(like(NAME,"*a")).new(NAME+" "+SURNAME:FULLNAME) |
|
3 |
=demo.query("select NAME+' '+SURNAME as FULLNAME from EMPLOYEE where NAME like '%a'") |
查询名字以a结尾的员工的全名,查询结果如下:
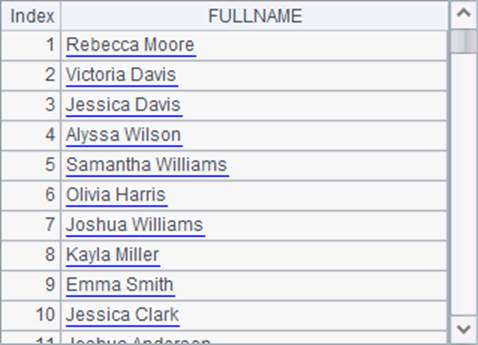
在使用like函数时,不同的数据库,对通配符的使用是不同的,如本例中,用通配符"%"来表示零个或多个任意字符,而在某些数据库中,要用通配符"*";而用集算器来处理的话,对任何数据库,语法都是统一的。
10. group
|
|
A |
|
1 |
=demo.query("select * from EMPLOYEE") |
|
2 |
=A1.new(NAME+" "+SURNAME: FULLNAME, DEPT).group(DEPT) |
|
3 |
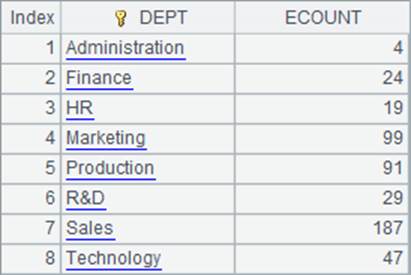
=A1.groups(DEPT;count(~):ECOUNT) |
|
4 |
=demo.query("select DEPT, count(*) as ECOUNT from EMPLOYEE group by DEPT order by DEPT") |
根据员工所在部门分组,在集算器中,可以用group函数对记录分组,如下:

可以看到,用集算器分组的结果,就是把记录分成了若干个组。利用分组的结果,在集算器中还可以根据需要继续计算。
A3中用集算器函数直接计算分组汇总,A4用SQL计算分组汇总,它们的结果是相同的。在SQL中,其实并没有真正的“组”的概念,只能在查询中,根据分组直接聚集计算。结果如下: