
多线程
本节讲解有关使用fork函数执行多线程计算的内容,非应用程序员如不需了解可以跳过,不影响正常阅读。
在解决计算问题时,串行计算是最为简单直观的处理方式。但是,当前的服务器或者个人计算机使用的CPU早已步入多核时代,完全有能力同时处理多个任务。此时,如果仍然使用串行计算,就无法充分利用CPU的计算能力。因此,在处理比较复杂的计算任务,或者面对大批数据时,就应该采取并行计算,用多线程甚至多台计算机共同完成计算任务。
在这里,我们先来研究最简单的并行计算——多线程计算。
用 fork 执行多线程计算
多线程计算是指在执行计算任务时,多个子任务使用各自独立的线程,同时计算的处理方式。在集算器中,可以使用fork语句来执行多线程计算。我们先用下面的例子了解fork语句的使用:
|
|
A |
B |
|
1 |
$(demo) select * from EMPLOYEE |
[Sales,R&D,Finance,Production] |
|
2 |
fork B1 |
=A1.select(DEPT==A2) |
|
3 |
|
=B2.minp(BIRTHDAY) |
|
4 |
|
return B3 |
在A1中,从数据库中读出EMPLOYEE表中的数据:
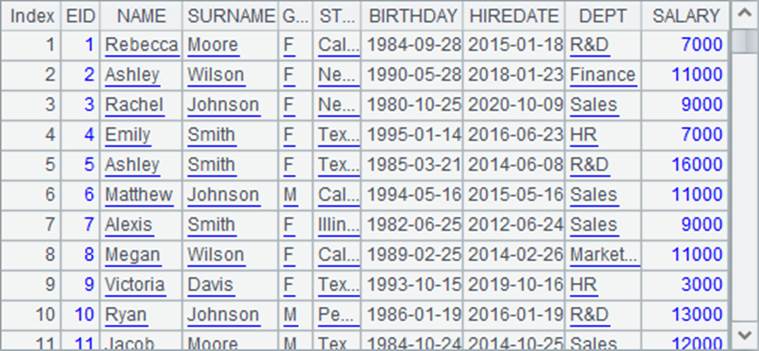
在A2中用fork语句执行多线程计算,分别选出B1的各个部门中年龄最大的员工。执行后,A2中的结果如下:
在用多线程执行代码时,用fork循环序列参数,会根据参数序列的长度,分为多个线程同时执行fork语句的代码块,代码块中用return返回的结果将在主线程中拼为序列。
使用fork虽然也类似于循环计算,但是它与一般的for循环是不同的。在for循环中,代码块是按顺序用单线程完成循环计算的,而fork根据序列参数执行的计算是同时处理的。
为了进一步了解各个线程的执行情况,我们在A2的代码块中用output函数输出信息到控制台:
|
|
A |
B |
C |
|
1 |
$(demo) select * from EMPLOYEE |
[Sales,R&D,Finance,Production] |
|
|
2 |
fork B1 |
>output(A2+"-begin") |
=A1.select(DEPT==A2) |
|
3 |
|
=B2.minp(BIRTHDAY) |
>output(A2+"-end") |
|
4 |
|
return B3 |
|
在A2的代码块执行时,当计算开始和结束时,在B2和C3中分别输出信息。执行后,在控制台中可以看到输出结果如下:
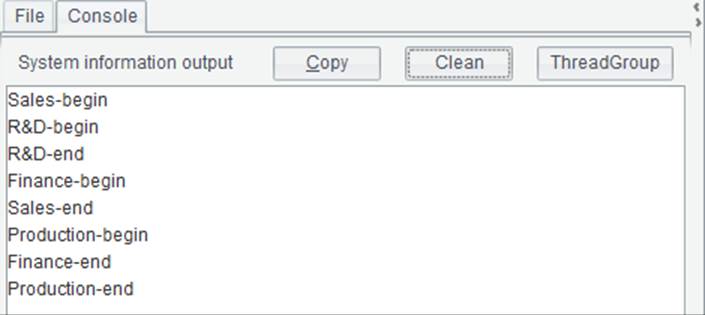
从输出结果中可以看出,多个子任务有可能会同时计算,有的子任务也有可能需要等待资源才能开始执行。在多线程任务执行时,是由系统分配的,系统将会根据CPU的空闲情况来控制各个子任务的执行。每个子任务的计算时间会受本身的计算量以及执行线程的影响,多线程任务的执行在不同情况下也经常是有区别的。
在执行多线程计算时,也可以使用多个参数,如:
|
|
A |
B |
C |
|
1 |
$(demo) select * from EMPLOYEE |
[Sales,R&D,Finance,Production] |
[Texas,Illinois,Ohio,Florida] |
|
2 |
fork B1,["F","F","F","F"],C1 |
=A1.select(DEPT==A2(1) && GENDER==A2(2) && STATE==A2(3)) |
|
|
3 |
|
=B2.minp(BIRTHDAY) |
|
|
4 |
|
return B3 |
|
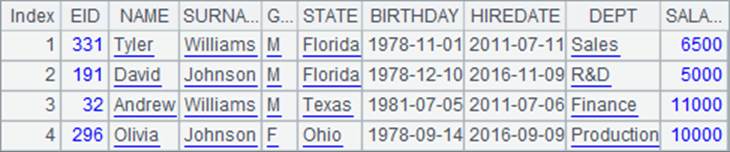
在A2执行多线程计算时,使用了3个参数,计算时将会按顺序匹配,即使用的参数依次为[Sales,F,Texas], [R&D,F,Illinois], [Finance,F,Ohio] 和 [Production,F,Florida]。此时寻找最大年龄的员工时,指定了部门、性别和所在州。A2中的计算结果如下:
如果执行多线程计算时使用多个参数,那么各个参数的序列长度应该是相等的。
我们可以注意到,在上面的代码中,查找各个部门的员工时,性别要求是同样的,此时可以将参数写为单值。如下面的例子:
|
|
A |
B |
C |
|
1 |
$(demo) select * from EMPLOYEE |
[Sales,R&D,Finance,Production] |
[Texas,Illinois,Ohio,Florida] |
|
2 |
fork B1,"F",C1 |
=A1.select(DEPT==A2(1) && GENDER==A2(2) && STATE==A2(3)) |
>A1=B2 |
|
3 |
|
return B2 |
|
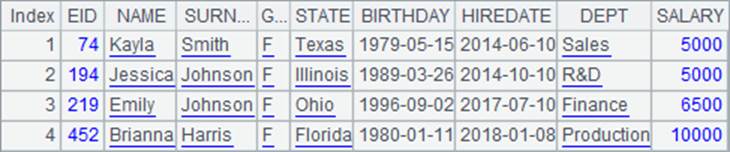
调用多线程计算时,单值参数会被复制到每个线程中,使用相同的参数值。另外,在这里代码块用return返回的并不是单条记录,而是排列,此时A2中的结果也会是排列构成的序列:
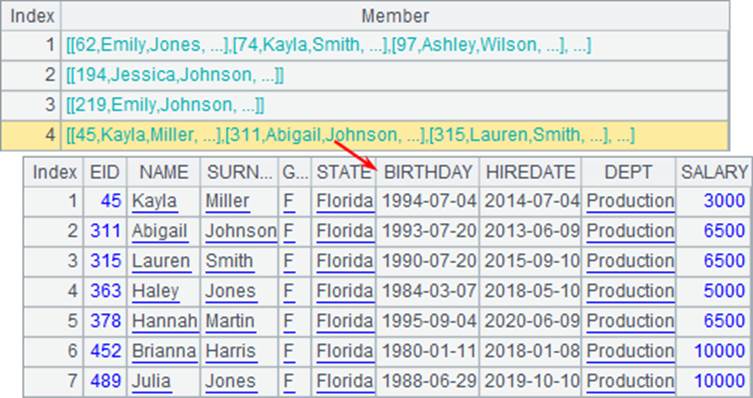
另外,在代码块中的C2中,将A1中的数据修改为选出的子程序中选出的排列。但是运行后,查看A1可以发现,A1中的数据并未被多线程运算的代码块修改。实际上,多线程运算的子程序在执行时,会各自复制当前的网格状态,是互相独立、互不影响的。因此它们也不能影响主代码中的数据。
fork语句除了可以用于多线程运算,也可以用于集群计算,相关内容请看后面集群计算 中的讲述。
使用多线程的性能优势
从执行上看,多线程计算的代码与普通的循环非常类似,那么为什么要用多线程计算呢?下面我们来比较一下多线程与普通循环的区别:
|
|
A |
B |
|
1 |
=file("PersonnelInfo.txt") |
|
|
2 |
=now() |
|
|
3 |
fork to(4) |
=A1.import@t(;A3:4) |
|
4 |
|
return B3.select(City=="San Diego") |
|
5 |
=A3.conj() |
=interval@ms(A2,now()) |
|
6 |
|
|
|
7 |
=now() |
|
|
8 |
for 4 |
=A1.import@t(;A8:4) |
|
9 |
|
>A10=A10|B8.select(City=="San Diego") |
|
10 |
[] |
=interval@ms(A7,now()) |
在这个例子中,从文本文件PersonnelInfo.txt中找到圣地亚哥的员工数据。在2~5行使用多线程,在7~10行使用普通循环。计算时,在B3和B8同样采取分段读取数据的方法。需要注意的是,使用多线程计算时,fork to(4) 不能简写。在A5和A10中,两种方法计算出的结果是相同的:
在B5和B10中估算出两种方法的耗时如下:
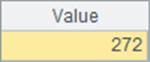

可以发现,由于用多线程计算时,CPU的利用率较高,因此计算耗时会少于使用普通循环。
线程数的合理设置
既然使用多线程计算可以提高计算效率,那么是不是线程越多越好呢?我们可以来实验一下:
|
|
A |
B |
|
1 |
=file("PersonnelInfo.txt") |
|
|
2 |
=now() |
|
|
3 |
fork to(4) |
=A1.import@t(;A3:4) |
|
4 |
|
return B3.select(City=="San Diego") |
|
5 |
=A3.conj() |
=interval@ms(A2,now()) |
|
6 |
|
|
|
7 |
=now() |
|
|
8 |
fork to(400) |
=A1.import@t(;A8:400) |
|
9 |
|
return B8.select(City=="San Diego") |
|
10 |
=A8.conj() |
=interval@ms(A7,now()) |
在这里,2~5行使用多线程计算,分4个线程完成计算。7~10行同样使用多线程计算,不过使用了400个线程完成计算。在A5和A10中获得的结果,和上一节中的情况结果都是相同的。
现在来查看B5和B10中估算的计算耗时:
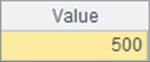

可以发现,虽然在A8中的多线程计算使用了非常多的线程,但是计算效率不但没有明显的提升,耗时还变多了。这是由于,系统空闲的CPU是有限的,过多的线程仍然需要等待顺次计算,往往不但无法提升效率,反而由于线程本身需要占用一定的资源,而造成速度变慢。在实际使用中,线程数略小于系统的CPU核数就可以获得比较好的性能了。