
排序与排名
在数据统计与分析中,将数据排序,或者计算出数据的排名,都是经常遇到的问题。我们有可能需要将销售记录按照日期排序;或者计算出销售人员的业绩排名,作为绩效考核的依据,这都是排序与排名的问题。
序列的排序与排名
在集算器中,使用psort,sort,rank,ranks等函数将数据排序或排名,下面我们首先来看如何将序列中的数据排序,或者计算成员的排名:
|
|
A |
|
1 |
[8,1,2,7,0,5,3] |
|
2 |
=A1.sort() |
|
3 |
=A1.psort() |
|
4 |
=A1.ranks() |
|
5 |
=A1.rank(5.5) |
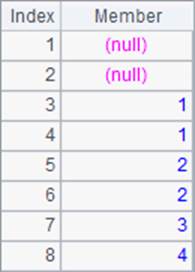
A2~A5根据A1中的序列来计算排序或排名。A2和A3的结果如下:
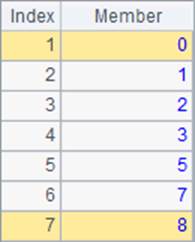
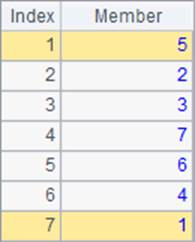
其中,A2计算序列中成员升序排序后的结果。A3中计算的是升序排序后的结果中,每个位置的成员在原序列中的序号。如最小的0,在原序列中的序号是5;最大的8,在原序列中的序号是1。实际上A2中的表达式,和 =A1(A1.psort()) 的结果是相同的。因此,在数据计算中,psort函数可以用来生成索引数列。
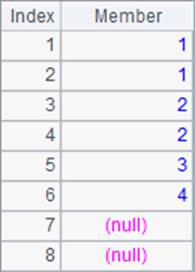
A4和A5中的结果如下:

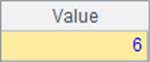
其中,A4获得的结果,是原序列中每个成员从小到大的名次。A5中计算的是5.5和A1中序列的各个成员比较,能排到的名次。
当排名结果中有可能出现并列时,可以用@i和@s选项调整rank函数的排序结果,如:
|
|
A |
B |
|
1 |
[2,1,2,3,4,4,5] |
|
|
2 |
=A1.ranks() |
|
|
3 |
=A1.ranks@i() |
=A1.rank@i(3.8) |
|
4 |
=A1.ranks@s() |
=A1.rank@s(2) |
A2中是默认情况下的排名,A3中添加了@i选项,A4中添加了@s选项,A2,A3和A4中的结果如下:
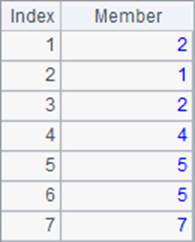
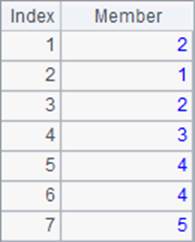
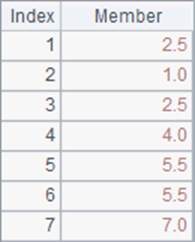
默认情况下,并列的名次会占位,使得后续的排名顺延,如出现两个第2名后,下一个就是第4名了。添加了@i选项时,会忽略并列名次的影响,无论有多少个并列第2名,下一个始终是第3名。添加了@s选项后,当出现并列排名时,会计算出排名的平均值作为并列名次,使得名次更能体现其实际位置。如两个并列第2名,他们实际占据了第2,3名的两个位置,因此认为他们的实际名次都是均值2.5。
与ranks类似,添加@i和@s选项后,rank函数的计算也会有所不同。B3和B4中的结果如下:
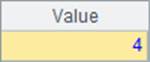
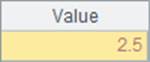
特别的是,在计算A.rank@s(y) 时,如果y在A中已经存在,会直接返回A中对应值的排名,而不会用再把y加入到A中计算排名均值。
当序列中包含空值时,排序时空值数据将被认为是最小的数据,如果有特殊需要,可以添加@0选项,使得空值被认为是最大的数据。如:
|
|
A |
|
1 |
[1,2,,,4,3,2,1] |
|
2 |
=A1.sort() |
|
3 |
=A1.sort@0() |
A2和A3中的排序结果如下:
使用psort/sort等排序相关函数时,都可以使用@0选项。
在实际运算中,直接使用常数序列排序的情况很少,通常需要排序的序列都是由计算获得。如:
|
|
A |
B |
C |
|
1 |
=demo.query("select * from EMPLOYEE where EID<6") |
|
|
|
2 |
=A1.(NAME+" "+SURNAME) |
=A2.sort() |
=A2.ranks() |
|
3 |
=A1.(BIRTHDAY) |
=A3.sort() |
=A3.ranks() |
|
4 |
=A1.(age(BIRTHDAY)) |
=A4.sort@z() |
=A4.ranks@z() |
为了更容易比较结果,A1中仅取出了前5条员工数据用于计算。A2计算出员工的全名并在B2中排序,在C2中计算各位员工的全名排名,A2,B2和C2中结果如下:
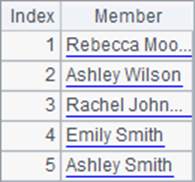
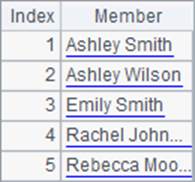
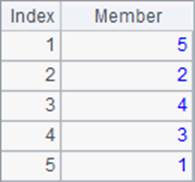
可以发现,在将字符串排序时,是按照字母顺序来排列的。实际上,在处理字符串的排序和排名时,是根据每个字符的ASCII码来比较的。
A3中求出员工的生日,并在B3中排序,C3中则计算生日的排名。A3,B3和C3中的结果如下:
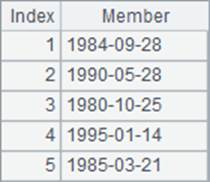
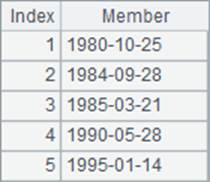
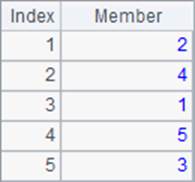
可以看到,日期数据的排序,就是以时间顺序处理的。需要注意的是,集算器中可以点击Tool>Option,在Option窗口的Environment页中设定日期格式。而日期或者日期时间类型的数据,排序或者计算排名的结果是和格式无关的。
A4中计算出员工的年龄。在B4中将年龄排序时,添加了@z选项,表示排序时降序排序;类似的,在C4中计算每个年龄的排名时,添加了@z选项,表示排名时从大到小。类似的,psort函数和rank函数同样可以使用@z选项。A4,B4和C4中结果如下:
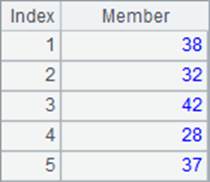
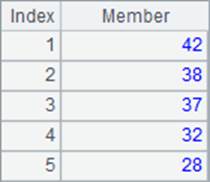
需要注意的是,添加了@z选项后,sort函数和rank函数的比较顺序也是相反的。另外,值得注意的是,在年龄数据中出现了相等的数据。从排序结果中可以看到,两个42的排名都是2,而排在它们下一位的37的排名变成了4。这说明,在默认情况下,并列的排名会占去相应的位置。我们将在第3节继续关于排名计算的研究。
在字符串排序时,是按照每个字符的ASCII码处理的,但是这种方式在遇到非英语的文字时,排序就有可能出现错误。在这种情况下,需要使用A.sort(…;loc),添加语言参数loc,如:
|
|
A |
|
1 |
[Íker,Álvaro,Estela,Alba,César,Sancho] |
|
2 |
=A1.sort() |
|
3 |
=A1.sort(;"esp") |
A1的序列中是几个西班牙语名字,在A2和A3中分别对它们排序,所不同的是A3在排序时指定了语言参数"esp",即使用西班牙语。A1,A2和A3中的数据如下:

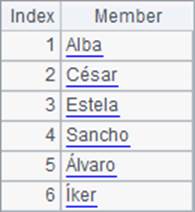
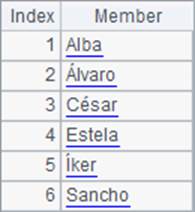
从结果中可以看到,指定语言参数后,可以获得正确的排序结果。
集算器能支持的语言和字符集可以从参考文档中查阅。
记录排序
我们在数据计算中同样经常需要将数据表中的记录按需要排序。如:
|
|
A |
|
1 |
=demo.query("select EID,NAME,SURNAME,GENDER, BIRTHDAY from EMPLOYEE where EID<6") |
|
2 |
=A1.sort(NAME+" "+SURNAME) |
|
3 |
=A1.sort(BIRTHDAY) |
|
4 |
=A1.sort@z(age(BIRTHDAY)) |
A1中取出了部分员工的资料如下:
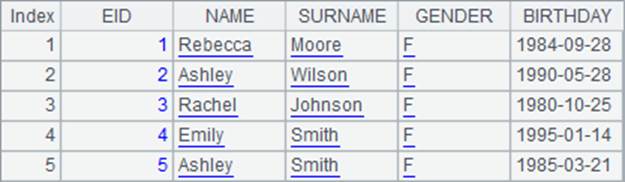
在A2中将记录按照员工全名排序,结果如下:
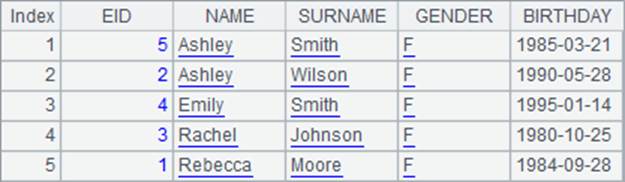
A3中根据生日将记录排序,结果如下:
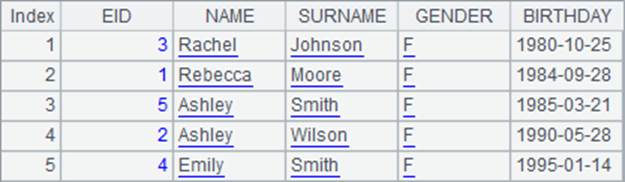
A4中根据年龄将记录降序排序,结果如下:
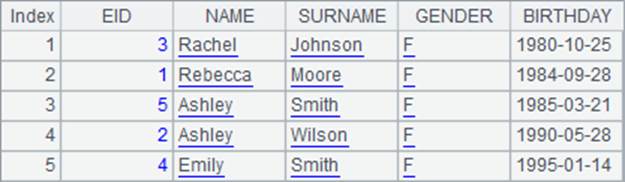
可以发现,使用sort函数,可以很方便地将序表或排列中的记录按需要排序,生成排列后返回。
我们来看A2中的结果,排序的结果是按照全名处理的,但是我们往往需要先将员工资料按照姓排名,同姓的再按照名字排序。这时,需要使用多字段排序:
|
|
A |
|
1 |
=demo.query("select EID,NAME,SURNAME,GENDER, BIRTHDAY from EMPLOYEE") |
|
2 |
=A1.sort(SURNAME,NAME) |
|
3 |
=A1.sort(GENDER,-SURNAME,-NAME) |
这里,A1中取出所有员工的资料如下:
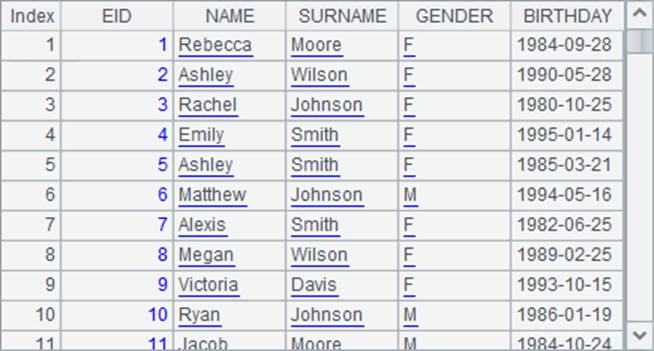
在A2中,先根据SURNAME排序,再根据NAME排序,结果如下:
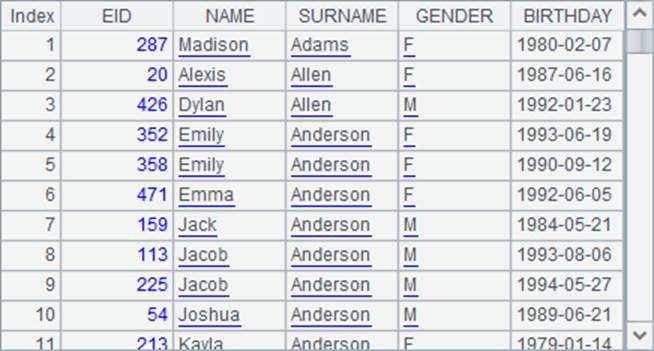
在上一节的内容中,我们了解到在使用sort,psort,rank,ranks等函数,可以添加@z选项来调整排序顺序。在用sort函数执行多字段排序时,由于各个字段的排序顺序不一定相同,因此不能使用@z选项,但可以在需要逆序排序的表达式前添加负号。如A3中的表达式,GENDER表示按性别升序排序,-SURNAME表示按姓降序排序,如果未添加标记,则表示升序排序。A3中的排序结果如下:
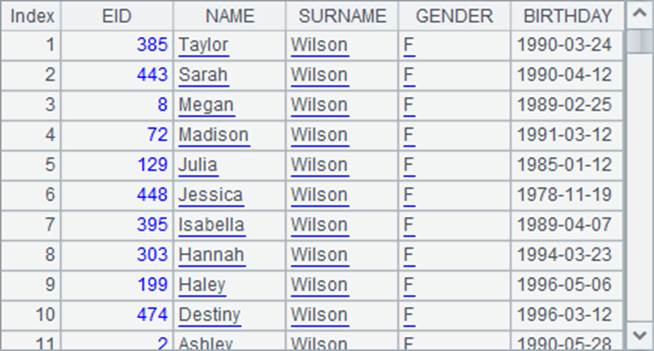
在将记录排序时,如果使用了非英文字符串,也可以在sort函数中添加语言参数。
在将序表中的记录排序时,有时我们只需要得到排在前几位的数据,此时可以使用top函数或者ptop函数。如:
|
|
A |
|
1 |
=demo.query("select EID,NAME,SURNAME,GENDER, BIRTHDAY from EMPLOYEE") |
|
2 |
=A1.top(5,age(BIRTHDAY)) |
|
3 |
=A1.ptop(5,age(BIRTHDAY)) |
|
4 |
=A1.top(5;age(BIRTHDAY)) |
|
5 |
=A1.top(-5,age(BIRTHDAY)) |
A2中用top函数计算出最小的5个年龄,A3中用ptop函数计算出年龄最小的5位员工的序号。A4中用top函数取出年龄最小的5位员工数据,其中第3个参数~表示返回A1中的原记录。 A2,A3和A4中结果如下:
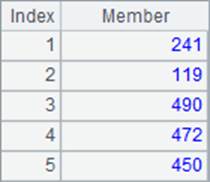
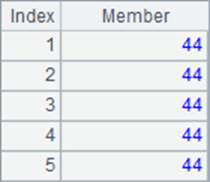
在top和ptop函数中,不能使用@z选项,如果需要计算最大的5个年龄,可以在函数参数中使用负数,如A5中的-5表示取出年龄最大的5个数据,结果如下:
在序表中计算排名
在计算排名时,有两种常见方式:计重排名,与不计重复的排名。如比赛中出现了2个并列第1名的选手,如果计算重复名次,那么排在他们下一位的选手就是第3名了;如果不计重复排名,那么将不考虑并列名次多占的位置,排在他们下一位的记为第2名。在集算器中,用rank可以计算排名结果,用rank可以计算单个数据的排名,如果添加@i选项,将去除重复值后再计算名次,如:
|
|
A |
|
1 |
=demo.query("select * from EMPLOYEE") |
|
2 |
=A1.ranks(SALARY) |
|
3 |
=A1.ranks@i(SALARY) |
|
4 |
=A1.rank(10000,SALARY) |
|
5 |
=A1.rank@i(10000,SALARY) |
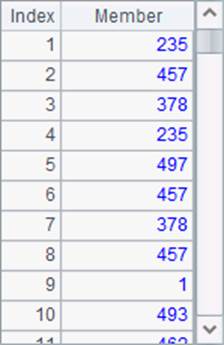
A2中计算出所有员工的薪水排名,A3中计算出员工薪水的不计重复排名,A2和A3中的结果如下:
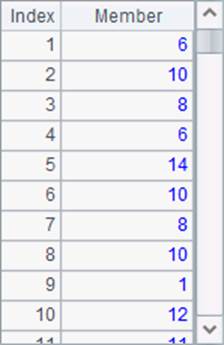
我们再来看一下A1中的员工数据:
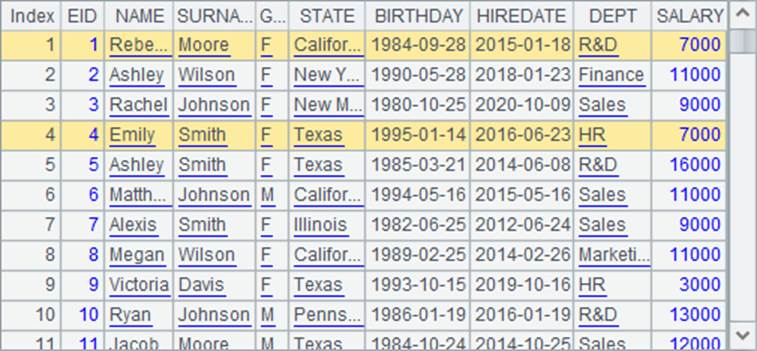
对比后可以发现,薪水相同的员工,如Rebecca和Emily,同样方法中计算出的薪水排名也是相同的。但是A3中计算出的名次显得靠前很多,这是由于不计重复的排名方式中,并列的名次不会影响后面的名次。实际上,A2中的排名结果更能反映出真实的排位。
A4中计算出10000在员工的薪水中可以排到的名次;A5中计算不计重复排名时,10000在员工薪水中的排名。A4和A5中结果如下:
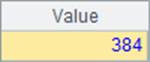
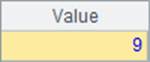
同样,不计重复的排名,结果会比普通排名更靠前。在计算rank@i和ranks@i时,类似于先将结果用id函数列出所有不重复的结果,再计算排名。