
序列与序表
序列、序表、排列是集算器中最常用的数据类型,本文将阐明它们之间的关系和各自的特性。
序列是有序的泛型集合
集合性
序列由多个数据构成, 这些数据被称为序列的成员, 成员可以是任意数据类型,比如字符串、数字、浮点、日期,序列成员还可以为空。序列具有集合的一般特性,可以进行集合运算。如:
|
|
A |
|
1 |
[] |
|
2 |
[5,6,7] |
|
3 |
[red,blue,yellow] |
|
4 |
=["blue","yellow","white"] |
|
5 |
=A3^A4 |
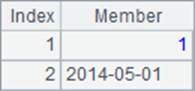
上面网格中,A1,A2和A3中的值如下:
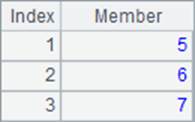

它们都是序列,其中,A1中为空序列;A2序列中的成员都是整数,也称作数列;A3的值是成员为字符串的序列。
A4中用表达式计算序列,和A3中的常数序列不同,表达式中的字符串需要用双引号扩出。A5计算A3和A4中两个序列的交集,结果也是序列。A4和A5中的结果如下:
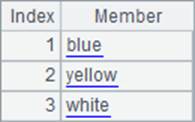
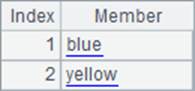
泛型性
序列是泛型集合,成员的数据类型可以不同,成员本身也可以是序列。如:
|
|
A |
B |
|
1 |
[] |
=[1,date("2014-05-01")] |
|
2 |
[5,6,7] |
=["blue",[],[5,6,7]] |
|
3 |
[red,blue,yellow] |
=["blue",A1,A2] |
网格中,B1中序列成员分别为整数和日期;B2中序列成员含有序列,与B3中的表达式等价。B1,B2和B3中的结果如下:
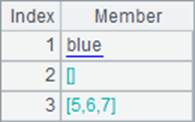
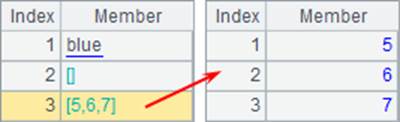
其中,序列成员用蓝色表示,可以双击查看。
有序性
一般的集合是无序的,即:成员一样但顺序不同的两个集合是相等的。序列具有有序性,成员一样但顺序不同的两个集合不相等,比如:
|
|
A |
B |
|
1 |
[Mike,Tom] |
[Tom,Mike] |
|
2 |
=A1==B1 |
|
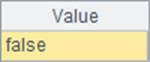
在A2中可以用表达式=A1==B1判断两个序列是否相等,其结果为false:
有序性是业务数据的普遍特性,比如:Mike排在Tom前面,可以表示前者的学习成绩更好;将销售额按月份排列,可以清晰表达销售额的变化规律。使用序列可以更方便地进行有序计算,比如:
|
|
A |
|
1 |
[Mike,Tom] |
|
2 |
=A1(2) |
|
3 |
=A1.m(-1) |
|
4 |
=A1.pos("Tom") |
|
5 |
=A1.rvs() |
A2中取出序列的第2个成员,也可以用=A1.m(2)来表示。A3中取出序列中倒数第1个成员。A4在序列中获得成员Tom的序号。A5将序列反转。A2,A3,A4和A5中的结果如下:



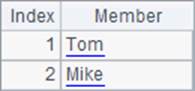
此外还有插入、删除、修改、复制、比较、聚合、子序列、排序、排名、集合运算、字符串和序列互转等。
成员都是整数的序列被称为数列,数列具有更细化的访问方法,比如:
|
|
A |
|
1 |
=to(2,5) |
A1中生成的序列如下:
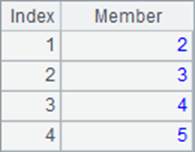
如果是从1生成序列,如=to(1,5)可以简写为=to(5)。
序表是有结构的序列
集算器继承了关系数据库中的数据表概念,称为序表。与关系数据库的概念一致,每个序表也有其自身的数据结构,由若干字段构成。序表的成员被称为记录。
有结构的二维数据对象
序列的成员可以是任意数据类型,比如普通类型、其他序列或者记录。而序表的成员一定是记录,且每条记录的结构相同。比如,下面的数据对象就是序表:

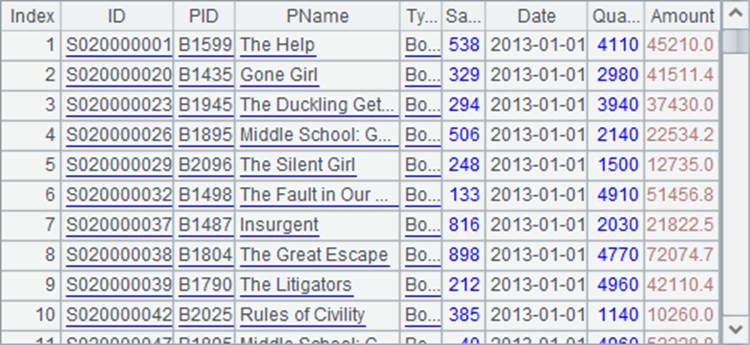
因为是有结构的二维数据对象,所以序表通常生成自SQL、文本文件、集文件、Excel文件,也可以由空白序表创建而来。下面的A1,A2,A3就是序表:
|
|
A |
|
1 |
=file("Order_Books.txt").import@t() |
|
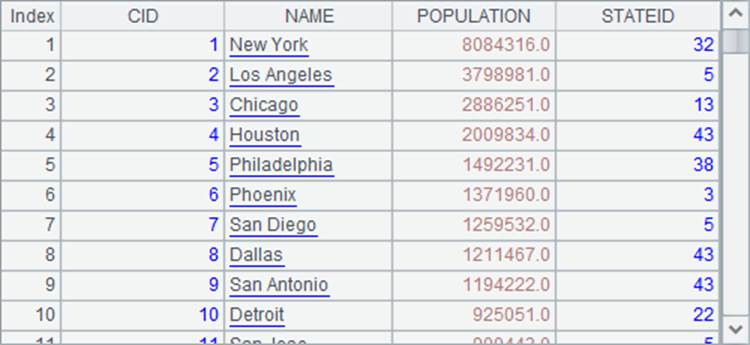
2 |
=demo.query("select * from CITIES") |
|
3 |
=create(OrderID,Client,SellerId,Amount,OrderDate) |
A1从文本文件生成序表,获得的结果就是上面的序表。A2通过SQL生成序表,A3指定字段名创建空序表。A2和A3中的数据如下:

序表支持大量的结构化数据算法,包括查询、排序、求和,平均值,合并重复记录等。比如:
|
|
A |
|
1 |
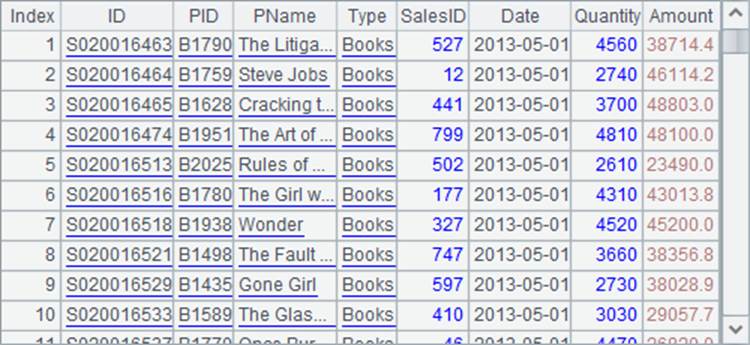
=file("Order_Books.txt").import@t() |
|
2 |
=A1.select(Amount>=20000 && month(Date)==5) |
|
3 |
=A1.sort(SalesID,-Date) |
|
4 |
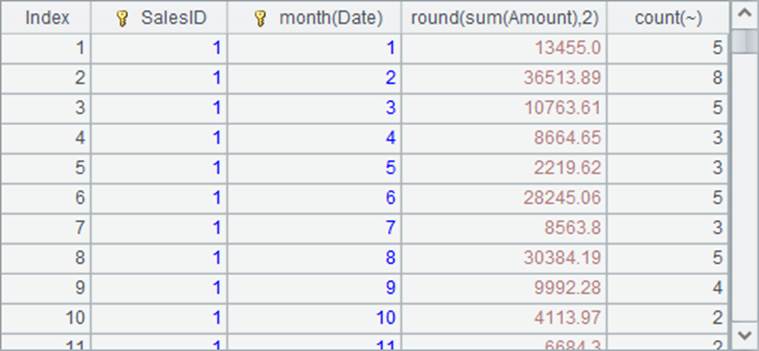
=A1.groups(SalesID, month(Date); round(sum(Amount),2), count(~)) |
A2中查询出Amount字段大于等于20000,Date是5月的记录:
A3将记录按照SalesID字段升序排列,SalesID一样时将按Date降序排列:

A4按SalesID和月份,对每一组数据的Amount求和,并计算该组订单计数:
序表仍然属于序列,序列的集合性、有序性及其相关的函数都适用于序表。对于泛型性,由于序表的成员必然是同结构的记录,序列意义上的泛型不再支持,不过记录的字段取值可以是泛型数据,可以说是另一种意义的泛型性。因为这些特性,序表比传统程序语言更擅长处理复杂的计算问题。
比如利用有序性解答:每个月的销售额比上个月增长了百分之几。序表的算法如下:
|
|
A |
|
1 |
=file("Order_Books.txt").import@t() |
|
2 |
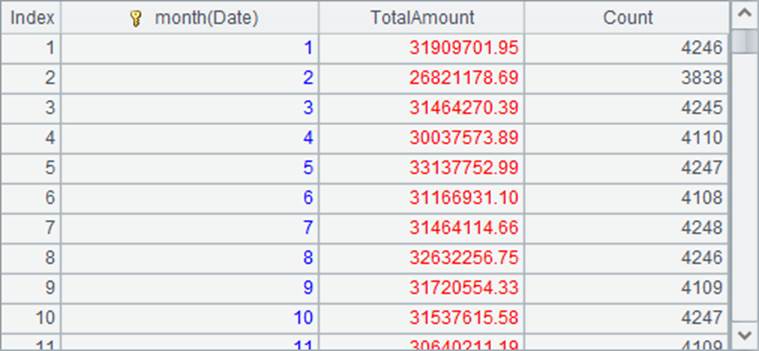
=A1.groups(month(Date); sum(decimal(string(Amount))):TotalAmount, count(~):Count) |
|
3 |
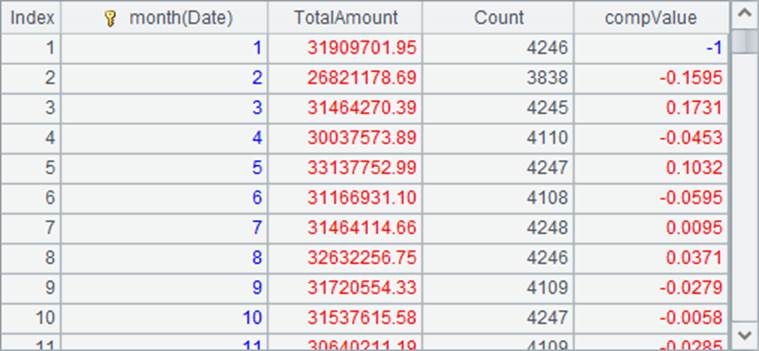
=A2.derive(round(TotalAmount/TotalAmount[-1]-1,4): compValue) |
A2中先统计出每月的总销售额:
A3中计算出最终结果如下:
利用集合性:假设业务上将订购数量大于1000的订单称为大订单,单价大于10000的订单称为重要合同,请找出:①既是大订单又是重要订单的订单;②以及除此之外的其他订单:
|
|
A |
B |
|
1 |
=file("Order_Books.txt").import@t() |
|
|
2 |
Big |
=A1.select(Quantity>1000) |
|
3 |
Importance |
=A1.select(Amount>10000) |
|
4 |
=B2^B3 |
=A1\A4 |
先在B2中选出大合同,再在B3中选出重要合同。A4中计算出2种合同的交集,就是问题①的答案:
B4中,用全部的订单与问题①的结果做差集,即可得到问题②的答案:
注意,上述代码中的A1中是序表,而B2,B3,A4和B4中,都是由序表派生出的排列,两者的区别和联系将在下面讲。
排列是对序表记录的引用
如果针对序表的计算每次都生成新的序表,显然会占用大量的内存。比如序表Order_Books中本来有50,000条记录,查询后获得30,000条,如果创建新的序表,则内存中的总记录数就是80,000条。事实上,查询出的记录是原序表的一部分,不必创建新的序表,只要用某种数据对象来存储原序表中30,000条记录的引用就够了。这种数据对象就是排列。
排列具有一定的透明性
通常情况下,用户不必刻意区分排列和序表,就像不必刻意区分引用和实体数据。比如前面例子中的查询、排序、交集等算法既可以用于排列也可以用于序表,语法上完全一样:
|
|
A |
B |
|
1 |
=file("Order_Books.txt").import@t() |
=A1.to() |
|
2 |
=A1.select(Amount>=20000 && month(Date)==5) |
=B1.select(Amount>=20000 && month(Date)==5) |
|
3 |
=A1.sort(SalesID,-Date) |
=B1.sort(SalesID,-Date) |
注意:A1中是序表,B1是用其生成的排列。而A2,B2,A3,B3中的计算结果均为排列。
排列之间可以进行集合运算,如序表是特殊的序列 中的订单计算。而不同序表中的成员总是不同的对象,对序表做集合运算通常没有实际意义,其交集恒定为空。
如果数据结构发生了变化,集算器会自动生成新序表,比如前面的例子中用groups函数计算分组汇总,或者用derive函数在序表中添加字段时。
序表会单向影响排列
不同的序表代表着不同的实体数据,因此修改了某一个序表并不会影响到其他序表。但排列是序表记录的引用,它们具有相同的实体数据,修改了序表会影响排列。如:
|
|
A |
|
1 |
=file("Order_Books.txt").import@t() |
|
2 |
=A1.select(SalesID==363) |
|
3 |
>A1.modify(3, 1:SalesID) |
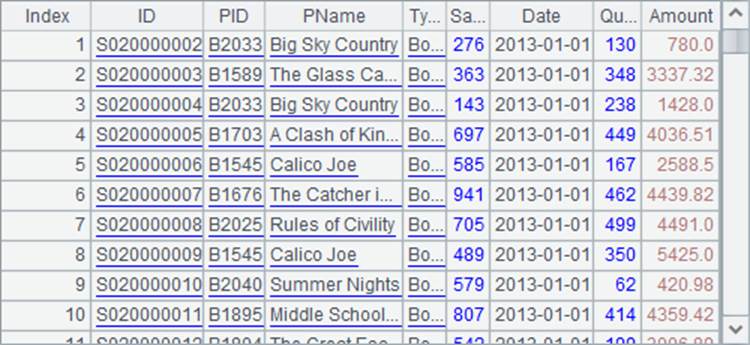
在工具栏中点击![]() 分步执行,可以看到A1中的序表如下,其中第3条记录的SalesID字段是363:
分步执行,可以看到A1中的序表如下,其中第3条记录的SalesID字段是363:
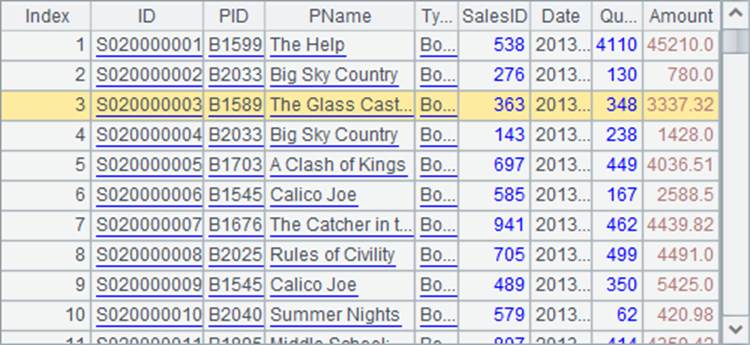
A2从中选出所有SalesID为363的记录,构成排列如下:
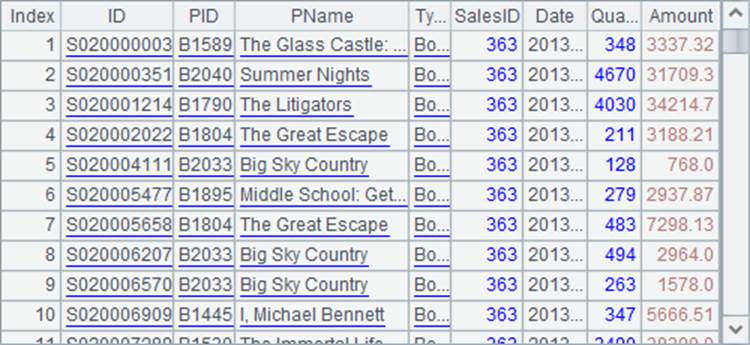
A3中,修改了A1中的序表,修改了其中第3条记录,将其SalesID字段变为1。此时再次查看A1中的序表,可以发现第3条记录已经被修改:

再查看A2中的排列,虽然并没有直接修改A2中的数据,但由于其记录来自序表,因此会发现其中对应的记录也被修改:
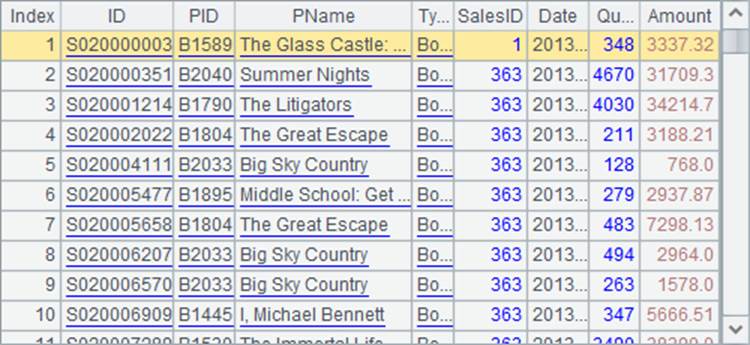
如果有多个排列都源自于同一个序表,则这些排列中的相应数据都会发生变化。
很多时候,这种影响是程序员不希望发生的,比如上面的情况,由于A3中对序表数据的修改,是在A2中执行选出记录之后,因此造成了A2选出的数据中,出现了SalesID不等于363的记录(因为引用未发生变化),这在业务上有时是错误的。
为了避免这种影响,用户应当在生成排列前就完成对序表的修改,比如:
- TSeq.modify(5, 1000: Amount) /将OrderID=5的记录的Amount字段修改为1000,即小于2000。
- RSeq =TSeq.select(Amount>2000) / OrderID=5的记录不会出现在RSeq中。
|
|
A |
|
1 |
=file("Order_Books.txt").import@t() |
|
2 |
>A1.modify(3, 1:SalesID) |
|
3 |
=A1.select(SalesID==363) |
先在A2中修改数据,再执行选出,这样A3中查询出的排列如下:
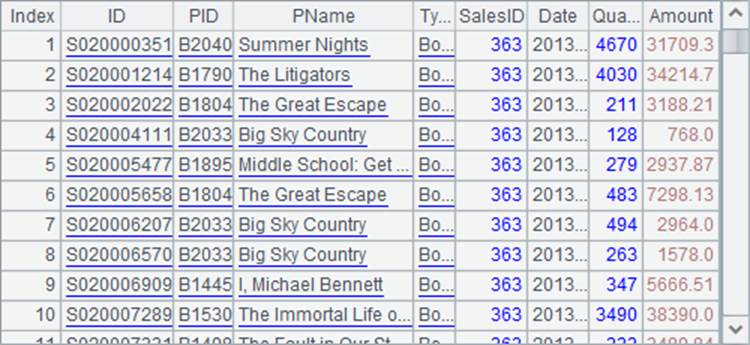
上述的计算结果才符合业务逻辑。当然,只要理解了序表和排列的引用关系,上述计算顺序是再自然不过的事情了。
需要注意的是,排列不支持modify等修改原序表的函数,所以这种影响是单向和安全,用户可以放心使用排列和序表。