
集文件
在集算器中, 经常使用两种数据文件:普通的txt文本文件和集文件。其中,集文件使用了低CPU消耗的压缩编码,在存储时会比未经压缩的文本文件容量更小,同时在读取时效率也更高。因此,在需要使用数据文件时,集文件是更好的选择。
在文本数据 中,我们了解了如何使用文本文件中的数据,在这里我们继续了解集算器中集文件的使用。
集文件与文本文件的比较
集文件的使用与文本文件基本相同,只是在集文件的import, export及cursor等函数中需要添加@b选项。我们用实际例子来看一下:

上面的两个文件PersonnelInfo.btx和PersonnelInfo.txt分别用集文件和文本文件存储了同样的人员信息数据,包含6个字段的100,000条记录。可以看到,集文件所占的硬盘容量会更小。
再了解一下使用两种文件读取数据的情况:
|
|
A |
|
1 |
=now() |
|
2 |
=file("PersonnelInfo.btx") |
|
3 |
=A2.cursor@b() |
|
4 |
=A3.groups(State;count(~):Count) |
|
5 |
=interval@ms(A1,now()) |
其中A3中用集文件生成游标,添加了@b选项。使用集文件分组汇总时A5中得到的计算时间如下(毫秒):

|
|
A |
|
1 |
=now() |
|
2 |
=file("PersonnelInfo.txt") |
|
3 |
=A2.cursor@t() |
|
4 |
=A3.groups(State;count(~):Count) |
|
5 |
=interval@ms(A1,now()) |
类似的,使用文本文件执行同样的计算,得到的时间如下:
上面的两个网格中,分别使用集文件和文本文件,做了同样的分组聚合计算,统计每个州的员工总数,并在A5格中计算耗费时间(毫秒)。从结果可以看到,使用集文件时,数据的读取速度会明显高于文本数据文件。
因此,在集算器中,如果需要使用文件来存储数据,用集文件将会更为便利。
在集算器安装包中,提供了数据文件工具,可以在集算器安装目录的esProc\bin路径下,运行btx.exe,查看集文件。btx.exe执行后,打开窗口如下:
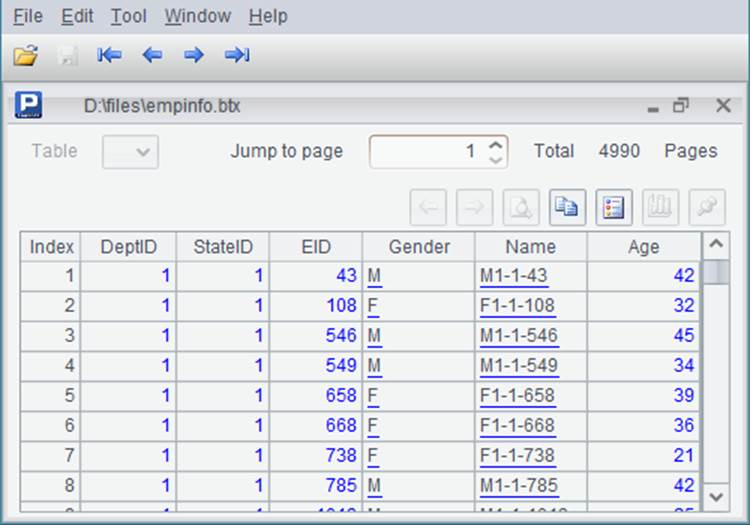
可以点击open,打开选定的集文件,其默认后缀为btx。集文件打开后,可以分页查看其中的数据:
在上方的工具栏中,可以点击相应的按键查看首页![]() ,前一页
,前一页![]() ,后一页
,后一页![]() ,最后一页
,最后一页![]() 的数据。
的数据。
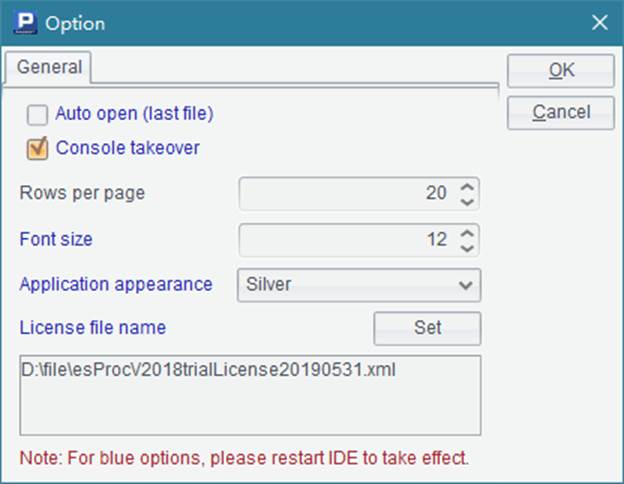
在菜单栏中点击Tool>Option可以设置集文件浏览器的一些属性,如每页显示记录条数等:
想进一步了解数据文件工具的使用,请参考《数据文件工具用户参考》。
使用游标分段读取
在大数据运算中,将数据拆分后分别计算,是常见的处理方法。在使用文件数据时,无论是文本文件或者集文件,均可以添加分段读取参数来分段读取。文本数据 中,介绍了使用文件数据生成序表时,分段读取的使用,使用游标分段读取数据与之是类似的,如:
|
|
A |
|
1 |
=file("PersonnelInfo.btx") |
|
2 |
=A1.cursor@b(;1:5) |
|
3 |
=A2.fetch() |
|
4 |
=A1.cursor@b(;2:5) |
|
5 |
=A4.fetch() |
在A2和A4中,生成游标的时候,均添加了分段参数,如1:5。根据参数,将游标中的所有数据分为5份,A2中返回第1份,A4中返回第2份。在A3和A5中,全部取出的数据如下:


PersonnelInfo.btx中共包含100,000条记录,因此可以看到,在将数据划分为5份的时候,是根据大致的容量划分的,而不是根据记录数精确均分。在分段读取数据时,集算器将自动调整读取数据的范围,以保证数据的完整性。如例子中的第1块数据和第2块数据,计算时将确保数据相连而不重复。
使用文本文件时,分段读取集文件是完全相同的,只是不再使用@b选项。在集文件中分段读取数据时,可以在调用时设定按组分段参数,具体的介绍请阅读组游标。按组分段是集文件独有的功能,普通文本文件无法使用。