
主键与索引功能
集算器的序表中,可以指定某个或某些字段作为主键,基于主键的查找可以使用专门的函数,不仅可以简化书写,更能有效地提高计算性能。
find 和 pfind
主键,是数据库表中经常见到,主键字段的值被用来在表中唯一标识一条记录,因此主键字段的值是不能重复的,在很多数据库中对此作了强制规定。
在集算器中,序表中类似于主键的字段可以有多个,这些字段均称为键,需要有着确定的次序。在序表中,所有键字段的取值称为主键。序表假定主键值在记录中是唯一的,但并没有硬性检查,主键值重复了也不会报错。T.pfind(k)和T.find(k)函数,都可以用来根据主键的值k在序表T中查找记录,其中pfind返回找到的第1条记录的序号,find返回找到的第1条记录。在函数中,根据T中键的个数,k可能是单值或序列。
如果需要将主键设为指定的字段,则需要使用T.keys(Fi,…) 函数,设置序表T的主键为Fi,…。在用create(Fi,…) 函数创建空序表时,可以在某些字段名前添加#表示该字段为键。如=create(#OrderID,Client,SellerId,Amount,OrderDate),在新建的空序表中,OrderID是主键。
在序表中查找记录,我们通常使用常规的定位函数T.select() 和T.pselect()这两个函数,下面我们来看一下pfind和find跟它们的对比。
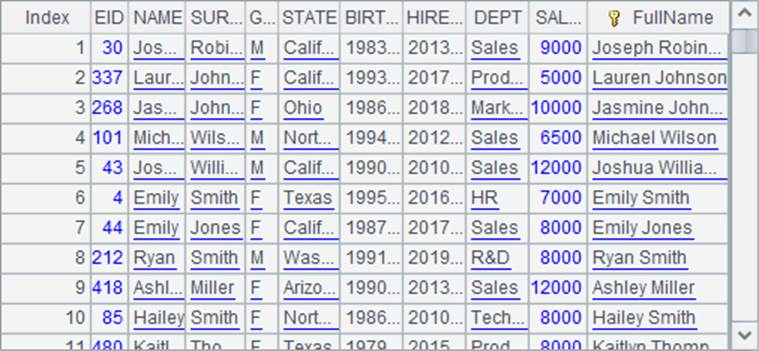
在这里,将使用demo数据库中的EMPLOYEE表作为需要查找的序表,并在其中添加FullName字段,准备用员工的全名来查找:
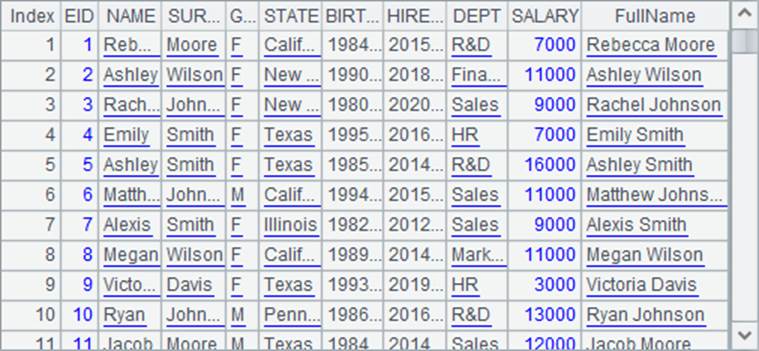
为了更明显地发现用主键来查找数据的性能优势,我们随机生成10000个全名,并根据这些全名,分别用pselect和pfind来查找,计算两种方法的耗时:
|
|
A |
|
1 |
=demo.query("select * from EMPLOYEE") |
|
2 |
=A1.derive(NAME+" "+SURNAME:FullName) |
|
3 |
=10000.(A2(rand(A2.len())+1).FullName) |
|
4 |
=now() |
|
5 |
=A3.(A2.pselect(FullName:A3.~)) |
|
6 |
=interval@ms(A4,now()) |
|
7 |
=now() |
|
8 |
>A2.keys(FullName) |
|
9 |
=A3.(A2.pfind(A3.~)) |
|
10 |
=interval@ms(A7,now()) |
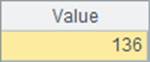
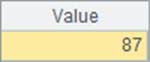
A5和A9中基于相同的数据,分别使用pselect和pfind函数在序表中查找记录的位置,其中,使用pfind之前,需要用keys函数设定序表的主键。A6和A10中分别计算出耗费的毫秒数如下:
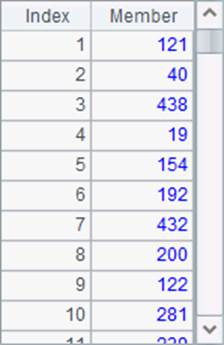
而A5与A9中的查找结果是相同的:
用类似的方法,还可以对比select与find函数,为了与find函数保持一致,在select函数中使用了@1选项,同样只找到第1个结果即返回:
|
|
A |
|
1 |
=demo.query("select * from EMPLOYEE") |
|
2 |
=A1.derive(NAME+" "+SURNAME:FullName) |
|
3 |
=10000.(A2(rand(A2.len())+1).FullName) |
|
4 |
=now() |
|
5 |
=A3.(A2.select@1(FullName==A3.~)) |
|
6 |
=interval@ms(A4,now()) |
|
7 |
=now() |
|
8 |
>A2.keys(FullName) |
|
9 |
=A3.(A2.find(A3.~)) |
|
10 |
=interval@ms(A7,now()) |
A6和A10中分别计算出耗费的毫秒数如下:
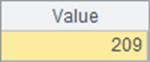
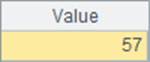
A5与A9中的查找结果仍然是相同的:
从上面的对比不难看出,基于主键的查找函数,效率明显高于常规的定位函数。
主键与索引表
为什么在集算器中,使用主键查找,会明显提升效率呢?这是由于使用主键值的判断更加简易,不必去计算过滤表达式的值。另外,在使用主键查找计算时,还可以使用主键的索引表来处理。
在调用keys时添加@i选项,就会根据主键生成索引表。生成索引表时,会根据所有的主键值来生成哈希表,根据哈希值,将主键划分为很多组,而哈希值即为对应的组号。
在通常情况下,根据字段值在序表中查找某条记录时,需要逐条比较,直到发现目标记录为止。对于n条记录的序表,平均要比较n/2次。
而有了索引表,在根据主键字段的值,在序表中查找某条记录时,情况就不同了。首先,会根据主键的值计算哈希值,这样就可以根据它直接找到索引表中对应的组,然后只需要与同组的记录比较就可以了。同样对于n条记录的序表,如果序表的主键根据哈希值分布在k个组中,那么平均只需要比较n/2k次就可以了。这样的方法,虽然在生成索引表与执行查找前,付出了计算哈希值的代价,但是大大减少了比较的次数,尤其是索引表只需要生成1次就可以了。因此,在使用基于主键的查找函数时,序表中的数据量越大,需要查找的次数越多,对效率的提升就越明显。
在计算中,还可以用T.index(n)函数来主动为T的主键建立索引表,n为索引的长度。如果不设定,将使用默认的索引长度。
我们需要了解的是,用find,pfind等利用主键值查找的函数,可以通过在序表中为主键建立索引表,更有效地提升计算性能。因此,如果主键本身就可以作为索引定位记录时,就不必再去建立索引表了,如上面员工资料表中的EID字段,它本身就表示着记录在序表中的位置,用EID直接找到对应的记录效率会更高:
|
|
A |
|
1 |
=demo.query("select * from EMPLOYEE").keys(EID) |
|
2 |
=10000.(A1(rand(A1.len())+1).EID) |
|
3 |
=now() |
|
4 |
=A2.(A1(A2.~)) |
|
5 |
=interval@ms(A3,now()) |
|
6 |
=now() |
|
7 |
=A2.(A1.find(A2.~)) |
|
8 |
=interval@ms(A6,now()) |
|
9 |
=demo.query("select * from EMPLOYEE").keys@i(EID) |
|
10 |
=now() |
|
11 |
=A2.(A9.find(A2.~)) |
|
12 |
=interval@ms(A10,now()) |
这一次,随机产生10000个员工编号来进行查找,A4中根据编号直接找到对应记录,A7中仍然使用find函数,而A9中设定主键时使用了keys@i建立索引表,之后在A11中类似A7做同样的查询,A5、A8和A12中分别计算3种方法的耗时如下:
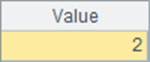
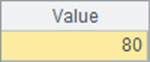
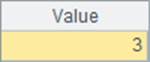
可以发现,用编号直接定位要快得多了,因为这种方法既不用比较字段值,也不必做哈希计算和建立索引表,而A10中建立了索引表后性能也非常好,但是在建立索引表的时候是需要耗时的。而A4、A7与A10中查找到的结果是相同的:

可见,在集算器中,利用序表主键的索引功能提升效率时,要注意是否适用。
switch 函数
除了find与pfind函数之外,switch函数也同样需要根据主键值在序表中查找记录,它也会自动利用主键的索引表来处理。如:
|
|
A |
|
1 |
=file("PersonnelInfo.btx ") |
|
2 |
=A1.import@b() |
|
3 |
=A1.import@b() |
|
4 |
=demo.query("select * from STATES") |
|
5 |
=now() |
|
6 |
>A2.(State=A4.select@1(ABBR:A2.State)) |
|
7 |
=interval@ms(A5,now()) |
|
8 |
=now() |
|
9 |
>A3.switch(State,A4:ABBR) |
|
10 |
=interval@ms(A8,now()) |
A2和A3中都是从集文件PersonnelInfo.btx中读取的人员资料,如下:
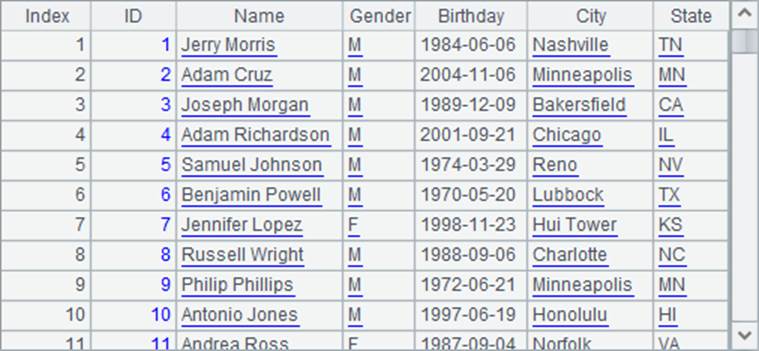
A4中是州信息表,如下:
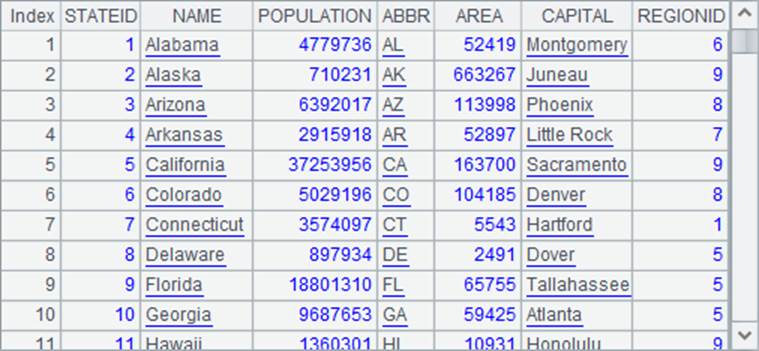
在A6和A9中,将人员资料表中的State字段变换为对应的州信息,不同的是A6中用select@1函数,A9中则使用switch函数。在A7和A10中分别计算出两种方法的耗时如下:
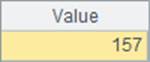
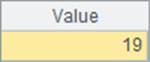
网格中的程序执行完毕后,A2与A3中的值是相同的,如下:
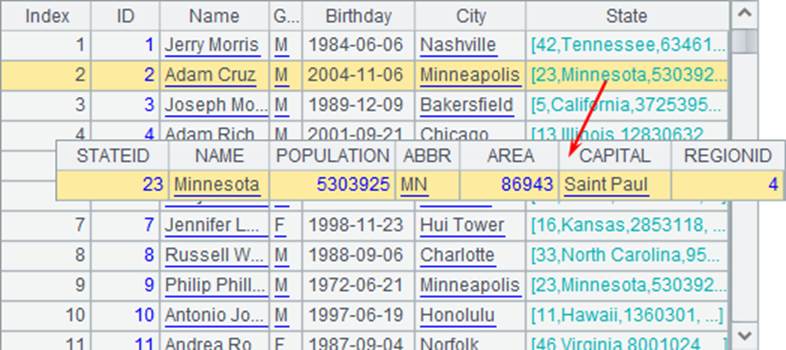
其中State字段已经被转换为了州信息表中对应的记录。
在执行switch前,同样会为序表中对应的字段建立索引表,这里是为A4中州信息表ABBR字段建立索引表,从而提升匹配效率。因此,在生成外键引用的字段时,应该适当选用switch函数。