
游标聚合运算
除了用cs.fetch()逐次取出数据外,我们还可以直接对游标运行分组聚合运算。
游标的分组聚合运算
最常见的分组聚合运算,就是计数与求和,除此以外,聚合运算还包括求最大值、最小值及前n个数据。对游标中的数据聚合运算,可以使用cs.groups() 函数,各类聚合运算对应的聚合函数分别为count/sum/max/min/top/avg/iterate/icount/median如:
|
|
A |
|
1 |
=file("Order_Wines.txt") |
|
2 |
=file("Order_Electronics.txt") |
|
3 |
=file("Order_Foods.txt") |
|
4 |
=file("Order_Books.txt") |
|
5 |
=[A1:A4].(~.cursor@t()) |
|
6 |
=A5.mergex(Date) |
|
7 |
=A6.groups(Type;count(~):OrderCount,max(Amount):MaxAmount, sum(round(decimal(Amount),2)):Total) |
在A7中,分种类统计了各类商品的订单总数、最大交易金额及总金额。需要注意的是,在大数据计算中,双精度数据的精度往往不够,此时需要用decimal() 将数据转换为数值类型计算。在游标的分组聚合运算中,所有数据都会被遍历一次,遍历时,对每行记录执行它在相应分组的聚合计算,在一次遍历中可以同时计算多个聚合值,在遍历完成后游标会自动关闭。
A7中结果如下:
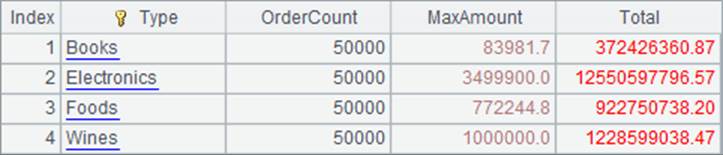
可以看出,在使用的测试文本数据中,每类商品的订单记录各有50,000条。各个文件中的数据,以及A6游标中的数据都是关于Date有序的,但是对Type并非有序,从例子中函数的使用可以知道,使用cs.groups() 函数分组汇总时,不需要游标中的数据有序。而在分组聚合后,结果会根据分组值排序。另外,由于cs.groups() 函数返回序表,因此,使用这个函数处理游标的分组聚合运算时,结果集必须是内存可以容纳的,而不适用于结果集本身是大数据的情况。
在聚合运算时,还可以统计最大/最小的n个数据,此时的聚合函数用top:
|
|
A |
|
1 |
=file("Order_Wines.txt") |
|
2 |
=file("Order_Electronics.txt") |
|
3 |
=file("Order_Foods.txt") |
|
4 |
=file("Order_Books.txt") |
|
5 |
=[A1:A4].(~.cursor@t()) |
|
6 |
=A5.mergex(Date) |
|
7 |
=A6.groups(Type;top(3,Amount):MinAmount,top(3,-Amount):MaxAmount) |
在A7中计算了每类商品订单中,总价最低的3笔订单金额和总价最高的3笔订单金额,注意其中计算最高3笔金额时,在聚合函数中添加负号,用top(3,-Amount)。结果如下:
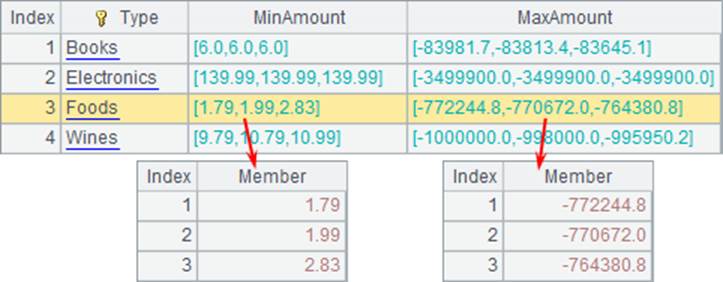
如果需要对所有记录做聚合运算,只需将在cs.groups函数中将分组表达式部分置空:
|
|
A |
|
1 |
=file("Order_Wines.txt") |
|
2 |
=file("Order_Electronics.txt") |
|
3 |
=file("Order_Foods.txt") |
|
4 |
=file("Order_Books.txt") |
|
5 |
=[A1:A4].(~.cursor@t()) |
|
6 |
=A5.mergex(Date) |
|
7 |
=A6.groups(;count(~):Count,sum(round(decimal(Amount),2)):TotalAmount) |
A7中结果如下:

由此可见,对所有记录的聚合运算,可以视为一种特殊的分组聚合。
多个游标的聚合运算
当处理多个游标的聚合运算时,可以先算出每个游标聚合运算的结果:
|
|
A |
|
1 |
=file("Order_Wines.txt") |
|
2 |
=file("Order_Electronics.txt") |
|
3 |
=file("Order_Foods.txt") |
|
4 |
=file("Order_Books.txt") |
|
5 |
=[A1:A4].(~.cursor@t()) |
|
6 |
=A5.(~.groups(Date;count(~):Count,sum(round(decimal(Amount),2)):TotalAmount)) |
在A6中,对各个文件游标分别分组聚合,计算出每类商品每天的聚合统计结果,如下:
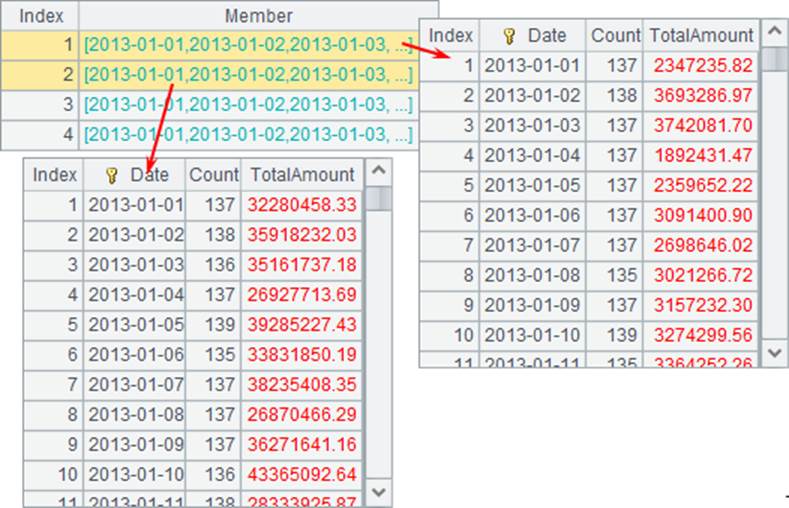
由于在使用cs.groups() 函数对游标分组聚合时,会根据分组值排序,所以对每类商品分组聚合后,无论原始数据的顺序如何,结果序表都是对时间有序的。这样,就可以进一步将结果归并,计算出所有商品每天的订单数据:
|
|
A |
|
1 |
=file("Order_Wines.txt") |
|
2 |
=file("Order_Electronics.txt") |
|
3 |
=file("Order_Foods.txt") |
|
4 |
=file("Order_Books.txt") |
|
5 |
=[A1:A4].(~.cursor@t()) |
|
6 |
=A5.(~.groups(Date;count(~):Count,sum(round(decimal(Amount),2)):TotalAmount)) |
|
7 |
=A6.merge(Date) |
|
8 |
=A7.groups(Date;sum(Count):Count,sum(round(decimal(TotalAmount),2)):TotalAmount) |
A8中的汇总结果如下:
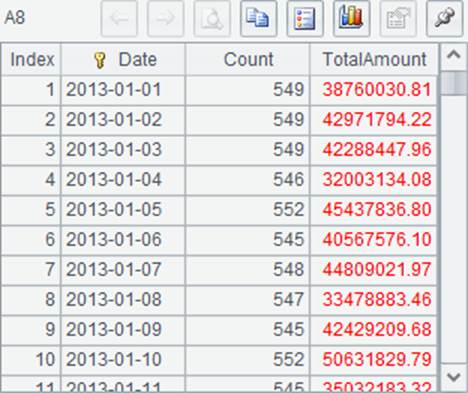
由于在各个数据文件中,每类商品的订单已经按日期排序,因此也可以先将游标有序归并再聚合运算:
|
|
A |
|
1 |
=file("Order_Wines.txt") |
|
2 |
=file("Order_Electronics.txt") |
|
3 |
=file("Order_Foods.txt") |
|
4 |
=file("Order_Books.txt") |
|
5 |
=[A1:A4].(~.cursor@t()) |
|
6 |
=A5.mergex(Date) |
|
7 |
=A6.groups(Date;count(~):Count,sum(round(decimal(Amount),2)):TotalAmount) |
可以看到,这种方法与上面的结果是相同的。对于多个数据有序的游标,先归并再分组聚合要更简便,计算效率也更高。值得注意的是,merge和mergex的区别:A.merge() 是将多个序列中的成员或多个序表中的记录有序归并,将返回序列,在执行时就计算完毕;CS.mergex() 是将多个游标中的记录有序归并,将返回游标,在游标取数时才会真正计算。而在使用时,A及CS中的数据均要求有序。关于mergex的使用,在游标归并与连接中有更详细的说明。
大数据结果集
在上一节中,我们知道,在执行分组聚合时,可以先将各部分数据分别分组聚合,这样可以获得一组有序的结果序表,再将结果归并就能得到最终结果。使用这样的方法,我们可以计算大数据结果集的分组聚合问题。
所谓大数据结果集,就是指不仅仅计算使用的源数据的数据量巨大,同时计算产生的结果也是大数据,这使得计算的结果集都无法一次读入内存,只能分步读取出来。如电信公司统计每位用户的当月账单,B2C网站统计每种商品的销售情况等,这些数据的统计结果可能会超过几百万条记录。
在集算器中,可以使用cs.groupx() 函数来计算大结果集的分组聚合。在下面我们用商品订单的每日统计结果模拟一下大数据结果集的使用。为了体会内存的限制,这里要求每次只能读取100条记录,那么需要分组聚合计算每天的订单时,必须使用groupx函数:
|
|
A |
|
1 |
=file("Order_Wines.txt") |
|
2 |
=file("Order_Electronics.txt") |
|
3 |
=file("Order_Foods.txt") |
|
4 |
=file("Order_Books.txt") |
|
5 |
=[A1:A4].(~.cursor@t()) |
|
6 |
=A5.conjx() |
|
7 |
=A6.groupx(Date;count(~):Count,sum(round(decimal(Amount),2)):TotalAmount;100) |
|
8 |
=A7.fetch(100) |
|
9 |
=A7.fetch(100) |
|
10 |
=A7.fetch(100) |
|
11 |
=A7.fetch(100) |
A6中,各个游标中数据依次连接,并非按日期排序。在A7中分组聚合后,将返回游标,而非序表,这样在A8~A11中即可分步读取数据,数据如下:
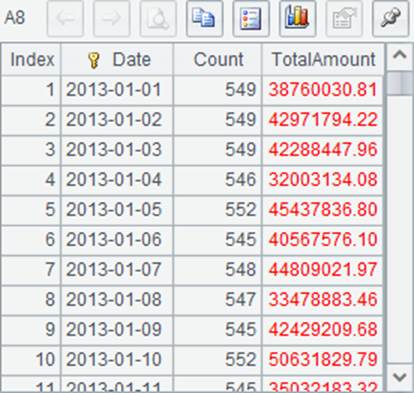
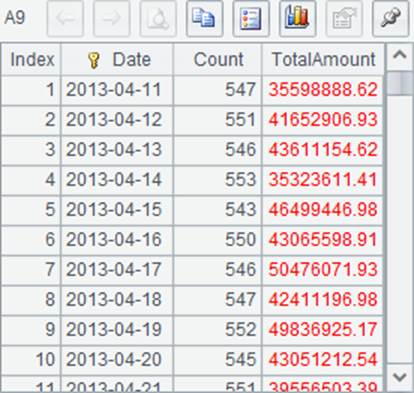
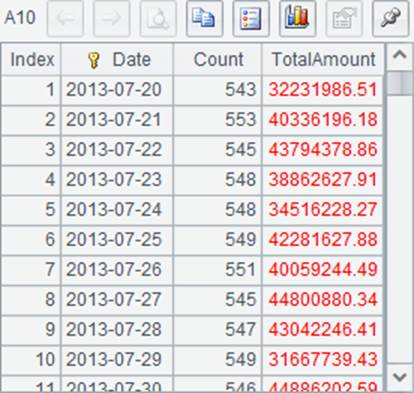

其中,A8~A10各读出100天的统计结果,而A11中读出了剩余的数据。游标中的数据全部读出后,将自动关闭。
在A7中,使用groupx函数,将数据按日期分组聚合,并设定缓冲行数为100。A7中的groupx函数中,最后一个参数100,表示内存中最多容纳100条数据,每100条数据就需缓存数据。这个参数在实际应用中是不需要设定的,集算器在执行缓存时会自动估算当前内存可容纳的数据条数,在必须的情况下才缓存数据。这样,在A7执行时,将边读取游标A6中的数据,边拆分聚合,每出现100行聚合结果,即缓存到一个临时文件中,以此类推。而A7中的计算结果,是由这些临时文件构成的文件组游标:
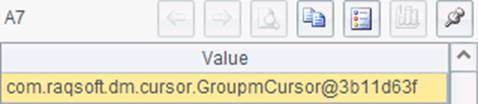
如果分步执行,那么在A7执行后,可以在系统的临时目录中看到生成的临时文件:
为了更清楚的了解到这些集文件中的内容,可以读出这些文件中的数据,如:
|
|
A |
|
1 |
=file("temp/tmpdata1372633253707222252").import@b() |
|
2 |
=file("temp/tmpdata2669923936558108709").import@b() |
|
3 |
=file("temp/tmpdata3937021394605697131").import@b() |
|
4 |
=file("temp/tmpdata8767777617311441973").import@b() |
A1和A3中读出的数据分别如下:
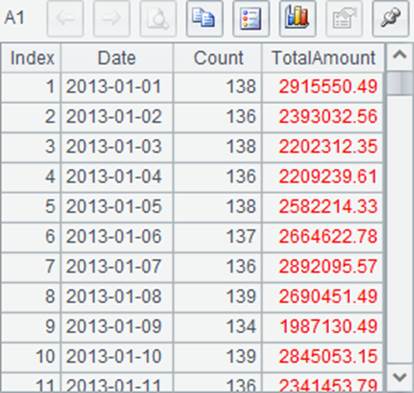

临时文件的名称时随机生成的,从中取出一些文件读取数据,可以看到,每个临时文件中都存储了部分连续的原始记录的分组聚合结果,而且在文件内按照日期完成了排序。实际上,根据函数中的缓冲行数,除了最后一个临时文件,每个文件中都正好包含100个日期的部分汇总数据。使用groupx生成游标,在用这个游标fetch取数时,会将所有的临时文件中的数据再次有序归并后计算出结果。
在使用临时文件的游标取数结束,或者关闭后,涉及的临时文件将自动删除。关于外存分组的计算方式,可以阅读大数据结果集的外存分组原理进一步了解。