内存区
当数据量较大,同时又需要快速计算时,可以在多台分机上,将集群组表常驻内存,后续查询可以直接访问内存数据。在分机启动时,将共享数据加载入内存区,根据内存区的编号提供全进程数据访问。
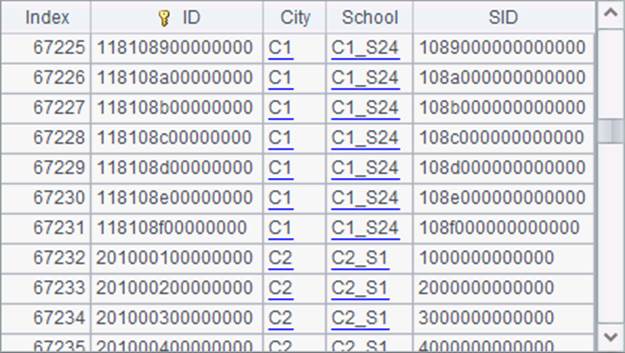
为了加载内存区的数据,需要分机在运行时执行初始化。分机运行时的初始化是靠执行init.splx来实现的,这个SPL文件放置在分机的主路径或者寻址路径中,可以自行设计在内存区加载的共享数据,如:
|
|
A |
B |
|
1 |
… |
/共用的一些初始化代码 |
|
2 |
if i> 0 |
|
|
3 |
|
=file("students.ctx":i) |
|
4 |
|
=B3.open().cursor().fetch() |
|
5 |
|
>env(STUDENTS, B4) |
在init.splx中,需要定义3个参数i,n和j,分别表示当前分机号、分机总数和任务名,将在初始化执行时传入:
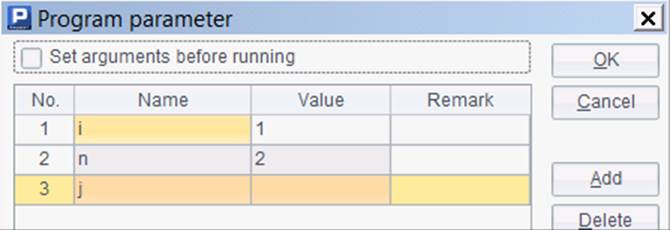
在这段初始化代码中,在读取文件数据时,file(fn:z) 表示在当前分机的数据区z中寻找文件fn,并用env(v, data) 函数将读出的数据存入当前分机内存区中的全局变量v中。
下面,来看如何使用内存区中的集群组表:
|
|
A |
|
1 |
[192.168.1.112:8281, 192.168.1.112:8282] |
|
2 |
=hosts (2,A1;) |
|
3 |
=memory(A2,STUDENTS) |
|
4 |
=A3.cursor().fetch() |
这里使用本机启动的两个分机,端口分别为8281和8282。A2中用hosts(n, h; j) 在分机主进程序列h中,查找分区值为1到n的可用分机序列,将对这些分机分别执行init.splx中的代码,加载对应的集群组表到内存区。初始化文件init.splx需要存储在每个分机的主路径中,在分机启动时会自动加载。结果即为找到的分机序列:

在分机窗口中能够看到对应的初始化执行情况,如:

A3中,memory(h, v) 使用各个分机内存区中的全局变量v共同构成集群组表。A4中使用内存区中的集群组表查询,它的使用和普通的集群组表是相同的。A4中查询结果如下: