
对位与枚举分组
在分组与汇总 一文中,我们了解了如何根据表中的数据,按需要分组,并计算汇总结果。需要注意的是,在分组汇总时,会根据值是否相等,将各组按照分组字段或表达式分组,并升序排序。在数据分析时,有时我们需要数据按照指定的次序排序,或者需要根据指定的条件来分组,这时可以使用对齐或枚举分组。
对齐
在将序列或序表中的数据排序时,常用sort函数,而排序的结果只能选择升序或降序。如果需要将数据按照指定的顺序排序,在集算器中可以使用对齐函数align,如:
|
|
A |
B |
|
1 |
[three,one,four,six,two] |
[one,two,three,four,five,six] |
|
2 |
=A1.sort() |
=A1.align(B1) |
|
3 |
=demo.query("select EID,NAME,GENDER, STATE,DEPT from EMPLOYEE") |
[California,Texas,Florida,Illinois] |
|
4 |
=A3.align(B3,STATE) |
|
A1中的序列中是一些字符串成员,而B1中给出了对齐将要使用的基本序列:

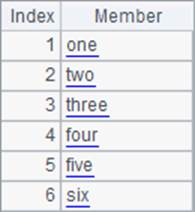
A2和B2中将A1中的成员重新排序,A2用普通的sort函数,而B2中,用align函数,将序列成员按照B1排列。计算后,A2和B2中的结果如下:
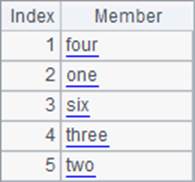
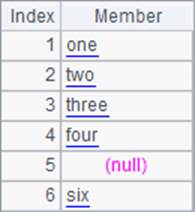
用sort排序只能按照字母顺序升序或降序,而用align排序将根据基准序列中成员的位置排序,如果找不到对应的成员,则对应位置是空。
对齐函数用得最多的还是将序表或排列中的记录排序,如A3中选出一些员工资料,在A4中从中按指定顺序,选出一些州的员工数据。A3中数据如下:
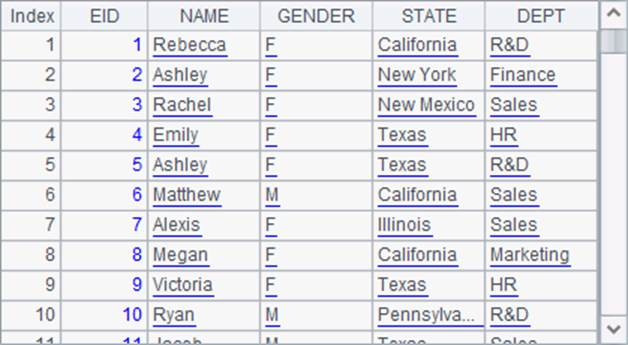
A4根据B3序列中的顺序,找出一些州的员工资料:
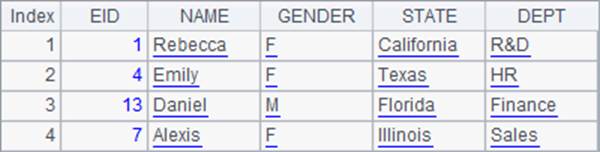
对齐后,每个州中都找出了第1位员工的资料,返回了这些记录构成的排列。
对齐分组
在上面的例子中,在对齐时,每个州中只获得了满足条件的第1条数据。在很多情况下,我们需要找出对应的所有数据,此时可以用align@a进行对齐分组,如:
|
|
A |
B |
|
1 |
=demo.query("select EID,NAME,GENDER, STATE, DEPT from EMPLOYEE") |
[California,Texas,Florida,Illinois] |
|
2 |
=A1.align@a(B1,STATE) |
|
|
3 |
=A2.new(STATE,~.count(GENDER=="M"):Male, ~.count(GENDER=="F"):Female) |
|
|
4 |
=A1.align@n(B1,STATE) |
|
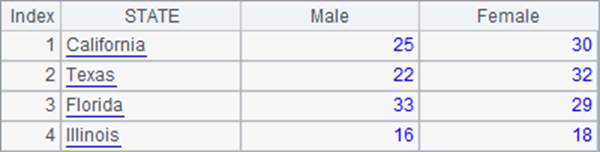
A2在align函数中添加了@a选项,在对齐时,对应每个州将找到所有对应的记录:

对齐分组后的返回值是由各个分组构成的序列,A2中的结果是个由序列构成的序列。和用group分组类似,align@a对齐分组后的结果,也经常用来进一步计算。如A3中,根据分组结果,进一步汇总计算出每州男员工和女员工的总数:
在对齐分组时,可能有一些数据,无法与基准序列中的任何一个成员对应。集算器提供了另一种模式的对齐分组选项align@n,在这种模式下,所有无法对应的成员,将被划分到一个新组中。如A4中的分组结果如下:
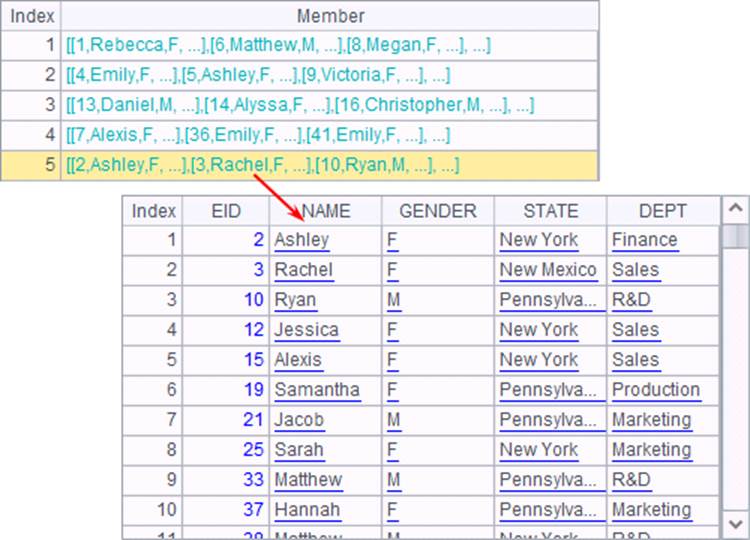
比较A2和A4中对齐分组的结果,我们可以发现,A4中多出了一个分组,存储了指定的4个州之外的员工记录。
在对齐分组时,基准序列也可以由计算获得,如:
|
|
A |
|
1 |
=demo.query("select EID,NAME,GENDER, STATE,DEPT from EMPLOYEE") |
|
2 |
=A1.groups(STATE;count(~):Count) |
|
3 |
=A2.sort(-Count) |
|
4 |
=A1.align@a(A3:STATE,STATE) |
在A2中,用groups分组汇总计算出各个州的员工总数,并在A3中将结果按员工总数降序排序。A2和A3中的结果如下:
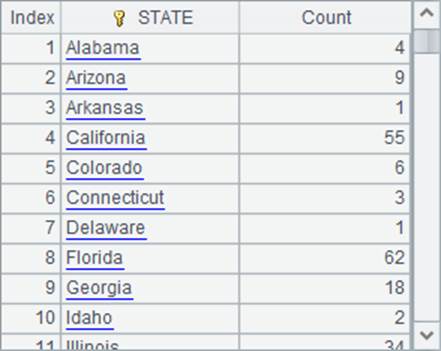
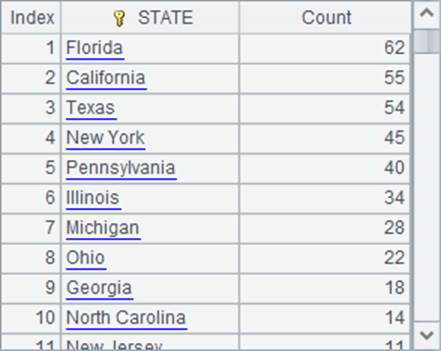
A4在对齐分组时,从A3的排序结果中获得州数据,计算出对齐时的基准序列。结果如下:
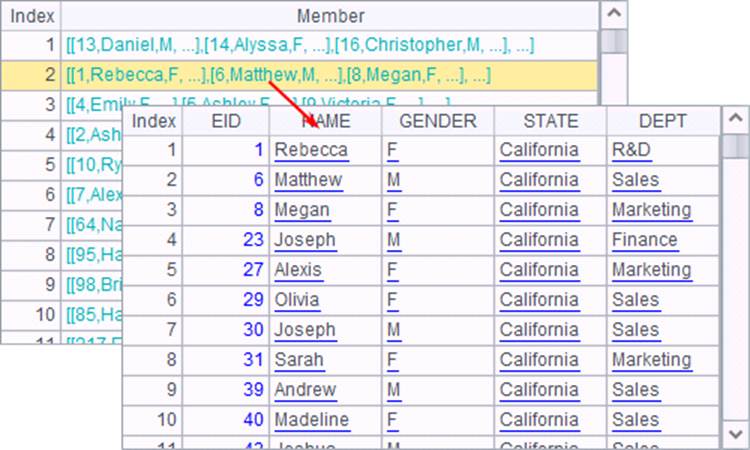
在对齐分组时,还有一种方式是用P.align(n,y),直接划分为n个组,并根据分组表达式y直接计算出每个成员对应的组号,如:
|
|
A |
|
1 |
=demo.query("select EID,NAME,GENDER, STATE,DEPT from EMPLOYEE") |
|
2 |
=A1.align@a(26,asc(left(NAME,1))-64) |
|
3 |
[HR,R&D,Finance,Marketing] |
|
4 |
=A1.align@a(A3.len(),A3.pos(DEPT)) |
在A2的表达式 =A1.align@a(26,asc(left(NAME,1))-64) 中,left(NAME,1) 取出员工名的首字母,再用asc函数转为ASCII码,减去64后就将各个大写字母对应到1~26的组号中。对齐分组后,结果如下:
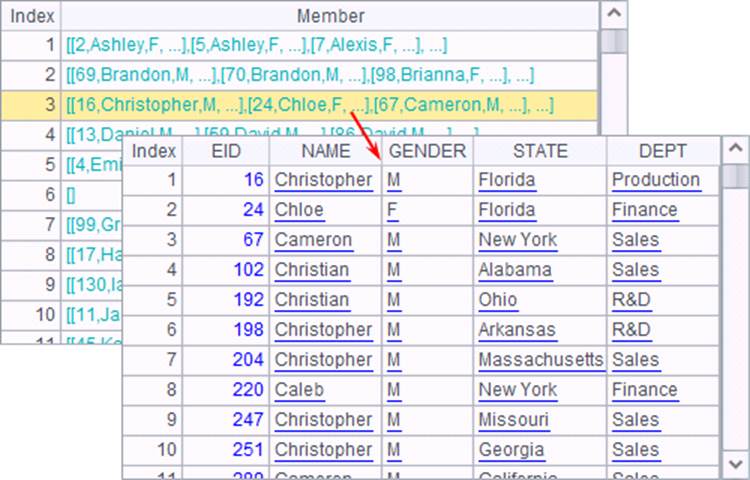
分组后,同一组内的员工,姓名的首字母相同。
在使用P.align(n,y)方式时,有时也用定位函数,如pos,pmax等函数来计算组号,A4中将员工按照指定的部门序列对齐分组,结果如下:
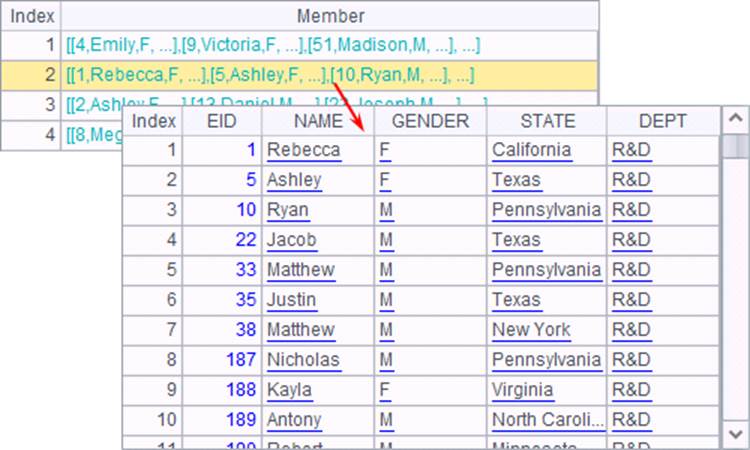
在用group将数据分组时,各个组会按照分组值升序排序,而使用对齐分组,就能指定顺序。
找到满足的条件
在将数据分组时,有时并非按照数值相同处理,而是需要根据一些条件,如根据订单金额的范围,或员工的年龄段等来分组。
分组时的条件可以用一些字符串表示,如"?>3","[2,3,5,7].pos(?)>0"等。在一个条件表达式字符串构成的序列中,可以用penum函数来判断一个数满足第几个条件,如:
|
|
A |
|
1 |
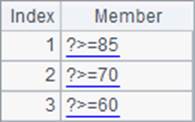
[?>=85,?>=70,?>=60] |
|
2 |
=A1.penum(100) |
|
3 |
=A1.penum(66) |
|
4 |
=A1.penum(54) |
A1中是一个由条件表达式构成的字符串序列:
A2和A3中,各自计算出100和66满足其中的第几个条件,计算结果如下:
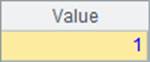

从结果中可以看出,当某个数满足多个条件时,只会返回第一个满足条件的序号。如100实际上可以满足所有3个条件,但结果是1。
在A4表达式中的54无法满足任何一个条件,返回的结果是null。
和对齐分组有些类似,在penum函数中也可以添加@n选项,在数据无法满足k个条件中的任何一个时,返回k+1。特别的,当条件表达式是空时,可以视为任何数据均可满足的条件。如:
|
|
A |
|
1 |
[?>=85,?>=70,?>=60] |
|
2 |
=A1.penum@n(54) |
|
3 |
[?>=85,?>=70,?>=60,null] |
|
4 |
=A3.penum(54) |
A2和A4中的结果如下:
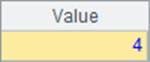
其中,在A2中,54无法满足3个条件中的任何一个,使用了penum@n函数,返回4。A4中,54可以满足第4个空条件。如果在枚举条件中使用null,要求必须将其放在最后1位。
在penum函数中还可以添加@r选项,表示条件可重复。此时将返回数据可以满足的所有条件的序号构成的序列,如:
|
|
A |
|
1 |
[?>=85,?>=70,?>=60,null] |
|
2 |
=A1.penum@r(100) |
|
3 |
=A1.penum@r(66) |
|
4 |
=A1.penum@r(54) |
A2,A3和A4中分别返回100,66和54满足条件的序号数列,结果如下:
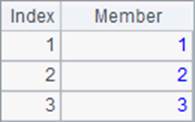
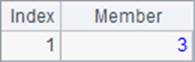
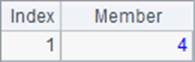
值得注意的是,虽然null条件视为一定满足,但是用penum@r函数时,如果其它条件能被满足,null的条件对应的序号就不会出现在结果中。同时可以发现,在使用@r选项时,即使只满足1个条件,结果也会返回序列而不是数。
枚举分组
设定一个条件表达式字符串构成的序列E后,还可以用P.enum(E,y) 函数来将一个序列P中的所有成员分组,运算时,将依次对每个成员计算表达式y,判断结果第几个条件,并将P中的成员分配到对应的组中,默认情况下,P中的每个成员只会置入第1个满足条件的组中。如:
|
|
A |
|
1 |
=demo.query("select EID,NAME,GENDER, BIRTHDAY,SALARY from EMPLOYEE") |
|
2 |
[?>=15000,?>=12000,?>=9000] |
|
3 |
=A1.enum(A2,SALARY) |
A1中查询出的序表以及A2中的枚举条件序列如下:
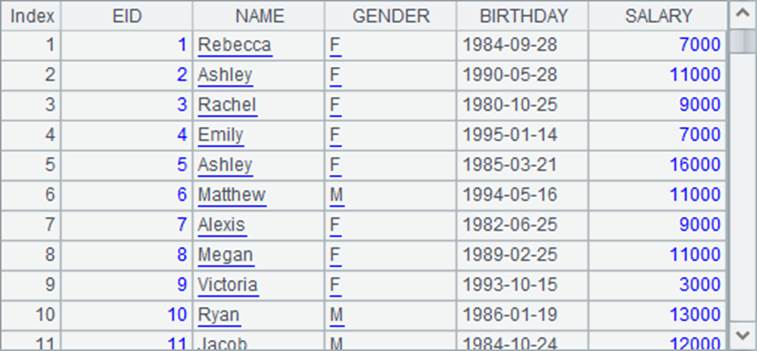

A3中,根据条件序列,枚举分组的结果如下:
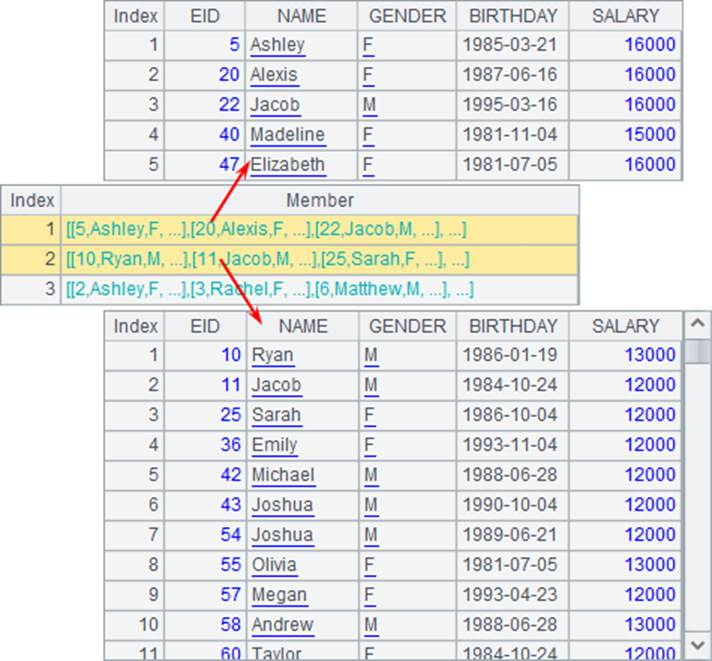
可以发现,枚举分组的每组中, SALARY并不相等,而是满足同一个条件。同样,虽然满足第1个条件的数据同样也满足后面2个条件,但默认只分到满足的第1个条件所在的组。对于不满足所有条件的数据,则不会被分到任何1组中,如第1条和第4条数据等。
和penum相似,枚举分组时,也可以在最后添加null条件,将所有不满足前面条件的记录置入;也可以使用enum@n,效果是类似的,如:
|
|
A |
|
1 |
=demo.query("select EID,NAME,GENDER, BIRTHDAY,SALARY from EMPLOYEE") |
|
2 |
[?>=15000,?>=12000,?>=9000] |
|
3 |
=A1.enum@n(A2,SALARY) |
|
4 |
[?>=15000,?>=12000,?>=9000,null] |
|
5 |
=A1.enum(A4,SALARY) |
A3和A5中的结果是相同的:
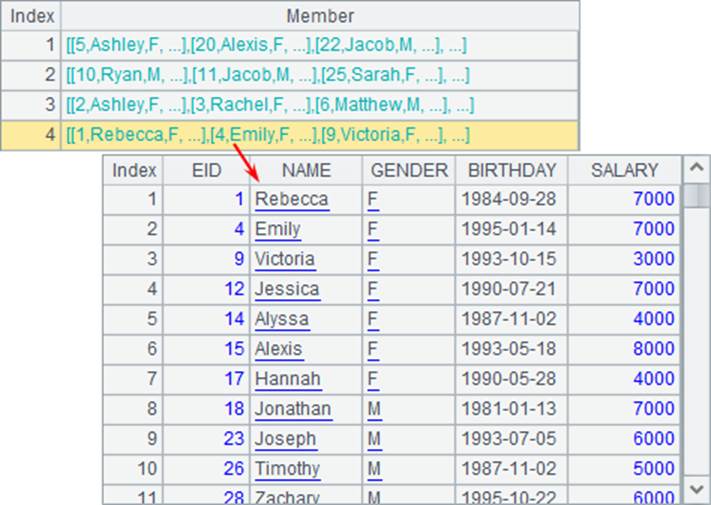
和上例的结果对比,可以发现,用enum@n函数,或者在条件序列最后添加null,都将把所有不满足前面条件的数据,分到一个分组中。
缺省情况下,enum函数在计算时假定不会有重复分组,即P中成员不会同时满足两个条件表达式。如果需要重复分组时,需要添加@r选项。如:
|
|
A |
|
1 |
=demo.query("select EID,NAME,GENDER, BIRTHDAY,SALARY from EMPLOYEE") |
|
2 |
[?>=15000,?>=12000,?>=9000] |
|
3 |
=A1.enum@r(A2,SALARY) |
A3中用enum@r重复枚举分组,结果如下:

从分组结果中可以发现,采用重复分组后,第1组中的成员出现在全部3组中,而第2组的成员也重复出现在了后两组中。