
pseudo()
本章节介绍pseudo()函数的用法。
pseudo()
生成虚表定义对象。
语法:
pseudo(pd,n)
备注:
通过定义记录pd生成虚表定义对象。设置参数n后,可从该虚表对象中取出多路游标,n为多路游标的路数。
参数:
选项:
|
@v |
组表产生的虚表,使用纯序表列式计算。 |
返回值:
虚表对象
示例:
组表作为虚表数据来源:
|
|
A |
|
|
1 |
=create(file).record(["D:/file/pseudo/app.ctx"]) |
为虚表定义记录,组表作为数据来源。 |
|
2 |
=pseudo(A1) |
生成虚表对象。 |
|
3 |
=A2.import() |
从虚表中取出序表。 |
复组表作为虚表数据来源:
|
|
A |
|
|
1 |
=create(file,zone,date).record(["pseudo/OrderInfo.ctx",[1,2],"OTime"]) |
为虚表定义记录,用复组表作为虚表数据来源。两个分表1.OrderInfo.ctx和2.OrderInfo.ctx中OTime是日期时间型,该列的数据分别是2020、2021年的。 |
|
2 |
=pseudo(A1) |
生成虚表对象。 |
|
3 |
=A2.select(OTime>date(2020,12,20)) |
按分列字段过滤数据,程序自动从相应分表获取数据。 |
|
4 |
=A3.import() |
以序表形式返回过滤后的数据。 |

设置参数n:
|
|
A |
|
|
1 |
=create(file).record(["emp.ctx"]) |
|
|
2 |
=pseudo(A1,3) |
生成虚表对象,参数n设为3。 |
|
3 |
=A2.cursor() |
从虚表中取出多路游标,路数为3。 |
使用@v选项:
|
|
A |
|
|
1 |
=create(file).record(["Emp.ctx"]) |
|
|
2 |
=pseudo@v(A1) |
由组表生成虚表对象,使用@v选项,使用纯序表列式计算。 |
|
3 |
=A2.cursor() |
生成列式游标。 |
|
4 |
=A2.import() |
生成纯序表。 |
|
5 |
=A2.memory() |
生成列式内表。 |
内存虚表:
|
|
A |
|
|
1 |
>tab=demo.query("select * from CITIES") |
获取CITIES表并将序表存储到变量tab。 |
|
2 |
=create(var).record(["tab"]) |
使用内存表来定义虚表。 |
|
3 |
=pseudo(A2) |
生成虚表对象。 |
|
4 |
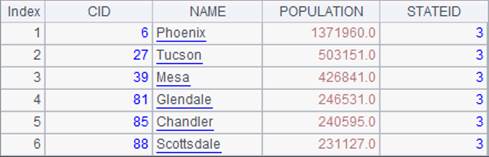
=A3.select(STATEID==3) |
从虚表中获取STATEID为3的信息。 |
|
5 |
=A4.import() |
|
虚表特殊字段定义的使用:
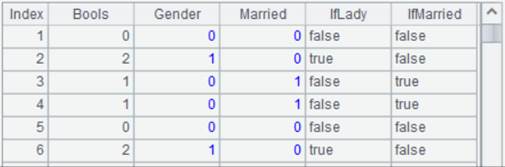
emps.ctx的数据如下图:
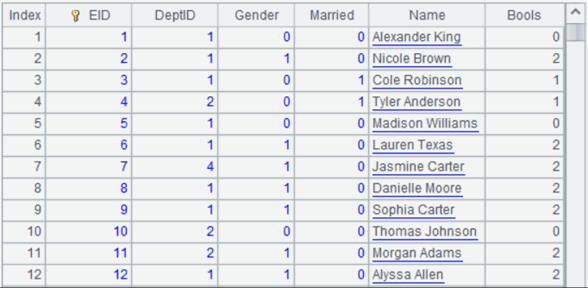
其中DeptID的字段值为1-5,分别对应部门Sales、Technology、R&D、Financial、Admin。
Bools字段存储了2个二值型字段的数据, Gender和Married。在Gender字段中,0表示男性,1表示女性;Married字段中,0表示未婚,1表示已婚。而Bools字段值则是经过bits(Gender,Married)计算的结果。
|
|
A |
|
|
1 |
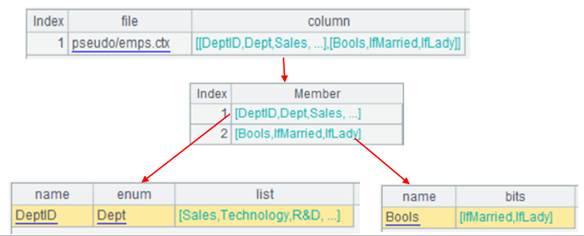
=create(file,column).record(["pseudo/emps.ctx",[{name:"DeptID",enum:"Dept",list:["Sales","Technology","R&D","Financial","Admin"]}, {name:"Bools",bits:["IfMarried","IfLady"]}]]) |
为虚表定义记录,包含一个枚举维度型伪字段Dept和一个二值维度伪字段Bools。
|
|
2 |
=pseudo(A1) |
生成虚表对象 |
|
3 |
=A2.import(DeptID,Dept) |
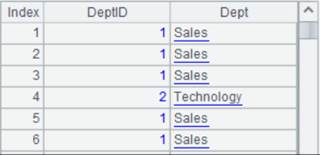
DeptID字段值1-5分别对应:["Sales","Technology","R&D","Financial","Admin"]
|
|
4 |
=A2.import(Gender,Married,IfMarried,IfLady) |
可看出Gender/Married和IfLady/IfMarried的对照关系。
|
虚表特殊字段定义-冗余字段的使用:
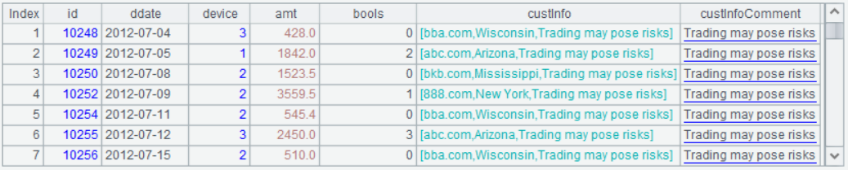
Details.ctx的数据如图:

custInfoComment为冗余字段,存放 custInfo.comment 的值。
|
|
A |
|
|
1 |
=create(file,column).record(["pseudo/Details.ctx",[{name:"custInfoComment",exp:"custInfo.comment"}]]) |
为虚表定义了一个计算式 exp:"custInfo.comment",和对应的真实字段 custInfoComment。
|
|
2 |
=pseudo(A1) |
生成虚表对象。 |
|
3 |
=A2.select(pos(custInfo.comment,"risk")) |
过滤条件中出现了计算式,所以并不会取出 custInfo 的记录再取其中的字段,而是被替换成真实字段 custInfoComment 。 |
|
4 |
=A3.import() |
取出过滤结果:
|
|
5 |
=file("pseudo/details_new.btx").cursor@b(id,ddate,device,amt,bools,custInfo) |
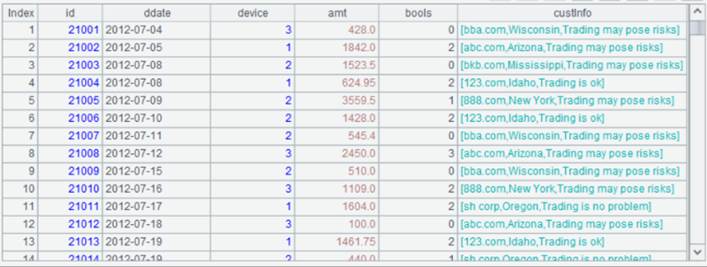
details_new.btx数据如下:
|
|
6 |
=A2.append(A5) |
追加数据,系统会自动转换生成 custInfoComment。 |
|
7 |
=A3.import() |
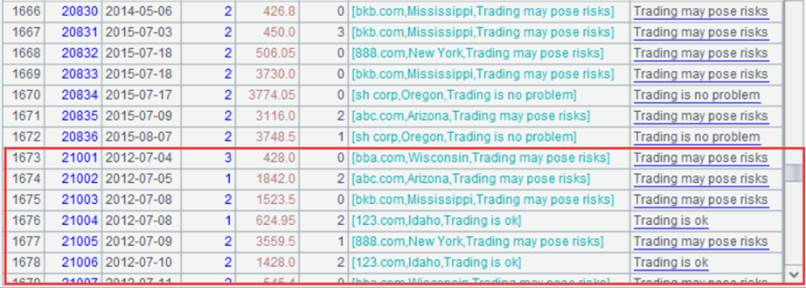
追加数据后的Details.ctx:
|

虚表特殊字段定义-字段别名的使用:
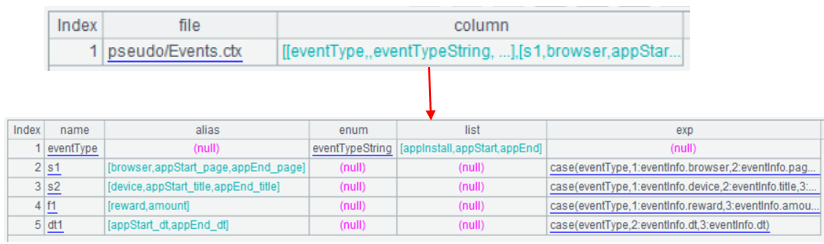
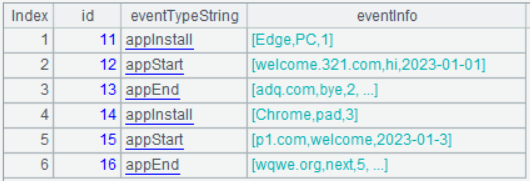
Events.ctx的数据如图:

每一行数据是一个事件。每个事件都存储了事件类型 eventType 以及这类事件对应的属性信息 eventInfo。
其中事件类型 eventType的字段值为1-3,分别对应appInstall、appStart、appEnd。
eventInfo 是一个记录字段,又包含多个字段,用来存储多个属性。
s1、s2、f1、dt1是真字段,存储三类事件的属性。s1 存储三类事件的三个字符串属性 browser、page和page。s2 存储三类事件的三个字符串属性device、title和title。f1存储appInstall和appEnd事件的两个数值属性reward和amount。dt1存储appInstall和appEnd事件的两个日期时间属性dt和dt。
|
|
A |
|
|
=create(file,column).record(["pseudo/Events.ctx",[{name:"eventType",alias:null,enum:"eventTypeString",list:["appInstall","appStart","appEnd"],exp:null}, {name:"s1",alias:["browser","appStart_page","appEnd_page"],enum:null,list:null,exp:"case(eventType,1:eventInfo.browser,2:eventInfo.page,3:eventInfo.page)"}, {name:"s2",alias:["device","appStart_title","appEnd_title"],enum:null,list:null,exp:"case(eventType,1:eventInfo.device,2:eventInfo.title,3:eventInfo.title)"}, {name:"f1",alias:["reward","amount"],enum:null,list:null,exp:"case(eventType,1:eventInfo.reward,3:eventInfo.amount)"}, {name:"dt1",alias:["appStart_dt","appEnd_dt"],enum:null,list:null,exp:"case(eventType,2:eventInfo.dt,3:eventInfo.dt)"}]]) |
在虚表的定义中为每个真字段配置多个有业务含义的别名。 真字段 s1 的三个别名 "browser","appStart_page","appEnd_page",以及对应的计算式 exp:"case(eventType, 1:eventInfo.browser, 2: eventInfo.page, 3: eventInfo.page)"。 eventType 取值如果不是 1、2 或者 3,真字段 s1 应该为 null。所以这里不能写成 case(eventType, 1:eventInfo.browser;eventInfo.page)。 s2、f1、dt1 的写法和 s1 类似。 |
|
|
2 |
=pseudo(A1) |
生成虚表对象 |
|
3 |
=A2.select(eventTypeString=="appInstall" && browser=="firefox") |
过滤条件中出现了字段别名,SPL 并不会取出 eventInfo 的记录再取其中的字段,而是自动替换成真实字段 s1,用冗余字段的值完成后续计算。 |
|
4 |
=A3.import(id,eventTypeString,browser,reward) |
取出过滤结果
|
|
5 |
=file("pseudo/events_new.btx").cursor@b(id,eventTypeString,eventInfo) |
events_new.btx数据如下:
|
|
6 |
=A2.append(A5) |
追加数据。系统会根据eventTypeString,eventInfo自动生成 s1、f1 等。 |
|
7 |
=A2.import() |
追加数据后的Events.ctx:
|


T.pseudo(T’,…)
描述:
设置虚表同步分段。
语法:
备注:
根据虚表T设置虚表T’,… 使用T同样的分段。设置虚表分段后,可从该虚表对象中取出多路游标。
参数:
|
T |
已分段的虚表对象。 |
|
T’ |
待分段的虚表对象。 |
示例:
|
|
A |
|
|
1 |
=create(file).record(["emp1.ctx"]) |
|
|
2 |
=pseudo(A1,3) |
由组表生成虚表对象,设置路数为3。 |
|
3 |
=create(file).record(["emp2.ctx"]) |
|
|
4 |
=pseudo(A3) |
生成虚表对象。 |
|
5 |
=A2.pseudo(A4) |
对虚表A4使用A2同样的分段。 |
|
6 |
=A4.cursor() |
从A4 中取出多路游标。 |