
import()
本章介绍import()函数的多种用法。
S.import()
描述:
用字符串中读出的内容作为记录返回成序表。
语法:
S.import(Fi:type;fmt,…;s)
备注:
用字符串S中读出的内容作为记录,最终返回成序表。
参数:
|
S |
字符串。字符串的格式:记录间用换行符隔开,字段间用自选分隔符隔开,缺省为tab键隔开。 |
|
Fi |
读出的字段,缺省读出所有。 |
|
type |
字段类型,包括:bool、int、long、float、decimal、number、string、date、time和datetime,缺省使用第一行数据类型。type为整数时表示排号键,排号数据目前只允许使用16个字节。 |
|
fmt |
日期时间格式。 |
|
s |
自选分隔符,缺省默认分隔符是tab。 |
选项:
|
@t |
f中第一行记录作为字段名,不使用本选项则使用_1,_2,…作为字段名。 |
|
@c |
s缺省时用逗号分隔。 |
|
@s |
不拆分字段,读成单字段串构成的序表,忽略参数。 |
|
@i |
结果集只有1列时返回成序列。 |
|
@q |
剥离数据项两端引号,包括标题,处理转义;中间的引号不管。 |
|
@a |
将单引号作为引号处理,缺省不处理,与@q组合使用时也是将单引号作为引号处理。 |
|
@o |
使用Excel标准转义,串中双个引号表示一个引号,其它字符不转义。 |
|
@p |
解析时处理括号和引号匹配,括号内分隔符不算,同时引号外转义也处理。 |
|
@f |
不做任何解析,简单用分隔符拆成串。 |
|
@l |
允许续行,行尾是转义字符\。 |
|
@k |
保留数据项两端的空白符,缺省将自动trim。 |
|
@e |
Fi在串中不存在时将生成null,缺省将报错。 |
|
@d |
行内有数据不匹配类型和格式时删除该行,此时会按type检查类型;@p@q时括号和引号不匹配时也删除该行。 |
|
@n |
行内的列数不匹配算时忽略此行。 |
|
@v |
与@d或@n联合使用,出现不匹配时抛出违例,并且中断程序,输出出错行的内容。 |
|
@w |
将每行读成序列,返回序列的序列,列名也算作一行。 |
|
@r |
先读成串再解析,避免某些字符集的错误,使用该选项速度会慢。 |
返回值:
序表
示例:
|
|
A |
|
|
1 |
=demo.query("select * from EMPLOYEE") |
|
|
2 |
=A1.(~.array().concat@c()) |
转换为字串序列:
|
|
3 |
=A2(1).import(;",") |
选取序列中的一个字串,从字串中选出所有字段,并指定分隔符为逗号,最后返回结果为序表:
|
|
4 |
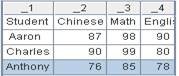
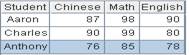
=demo.query("select EID,NAME,SURNAME from EMPLOYEE") |
|
|
5 |
= A4.export() |
|
|
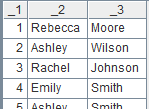
6 |
= A4.export@t(EID:id,NAME:name,SURNAME:surname;"|") |
|
|
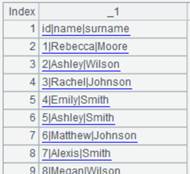
7 |
=A5.import() |
无参数,缺省分隔符为tab,用_1,_2,…作为字段名:
|
|
8 |
=A6.import@t(id:int,name;"|") |
选出id和name字段,分隔符为“|” :
|
|
9 |
=A6.import@f() |
使用@f选项,直接用分隔符拆成串:
|
|
10 |
1,2,"3,3",(4,4),[5,5],'6,6' |
|
|
11 |
=A10.import@c() |
使用@c选项,分隔符缺省使用逗号:
|
|
12 |
=A10.import@cp() |
使用@p选项,解析时处理括号和引号匹配:
|
|
13 |
=A10.import@cpa() |
使用@a选项,将单引号作为引号处理:
|
|
14 |
=A2(1).import@c() |
使用@c选项,分隔符缺省使用逗号:
|
|
15 |
=A5.import@s() |
使用@s选项,不拆分字段,读成单字段串构成的序表:
|
|
16 |
=A5.import@si() |
结果集只有1列时返回成序列:
|
|
17 |
"uy'd'uj" |
|
|
18 |
=A17.import() |
|
|
19 |
=A17.import@q() |
使用@q先剥离两端的引号后再转为序表,中间的引号不作处理:
|
|
20 |
f1,f2,f3 2,"dd""ff",3 |
|
|
21 |
=A20.import@coq() |
使用@o选项,串中两个引号表示一个引号:
|
|
22 |
=" abc ".import@k() |
保留两端的空白符。 |
|
23 |
=A6.import@te(id:int,name,dept;"|") |
dept在串中不存在时生成null:
|
|
24 |
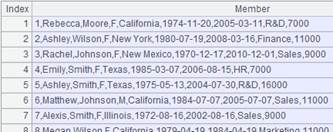
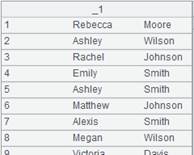
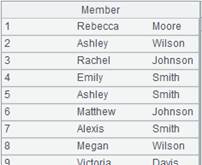
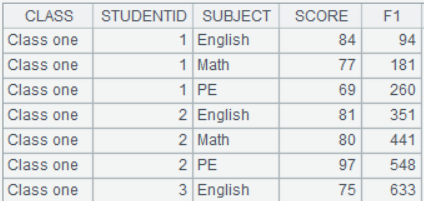
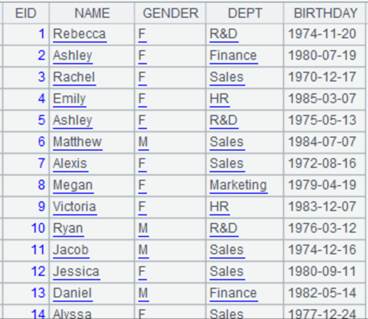
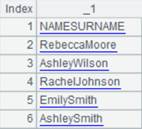
id|name|surname a|Rebecca|Moore 2|Ashley|Wilson 3|Rachel|Johnson 4|Emily|Smith 5|Ashley|Smith 6|Matthew|Johnson 7|Alexis|Smith 8|Megan|Wilson |
|
|
25 |
=A24.import@td(id:int,name;"|") |
行内有数据不匹配类型,则删除该行:
|
|
26 |
=A24.import@tvd(id:int,name;"|") |
检查类型匹配且出错时抛出违例,中断程序,输出出错行的内容,此处报错信息: Error in cell A26。 |
|
27 |
id|name|surname 1|Rebecca|Moore 2|Ashley 3|Rachel|Johnson 4|Emily |
|
|
28 |
=A27.import@tdn(id:int,name,surname;"|") |
第2、3行内数据列数与序表不匹配,故忽略这两行:
|
|
29 |
=A24.import@w(;"|") |
使用@w选项,将行读成序列的序列:
|
|
30 |
11,22,"3",\ 33,44,55, 66,77,88 |
|
|
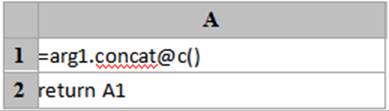
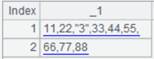
31 |
=A30.import@l() |
使用@l选项,行尾为转义符\时允许续行:
|
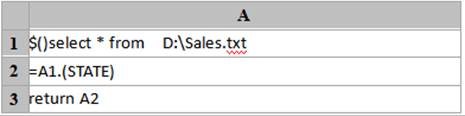


相关概念:
f.import()
描述:
读取文件内容并返回成序表。
语法:
|
f.import() |
|
|
f.import(Fi:type:fmt,…;k:n,s) |
从文本文件f中读取n段中的第k段数据,Fi为读出的字段,缺省读出所有字段。s为自选分隔符,缺省分隔符是tab。 在分段读取时,会自动调整位置使读取到的整条内容读入记录,同时会保证读取时数据的连续性,避免出现重复或遗漏。 |
备注:
读取文件f,将读取的每行内容作为一个记录形成序表返回。
参数:
|
f |
文件。 |
|
Fi |
读出的字段,缺省读出所有,用#时表示用序号定位。 |
|
type |
字段类型,包括:bool、int、long、float、decimal、string、date、time和datetime,缺省使用第一行数据类型。type为整数时表示排号键,排号数据目前只允许使用16个字节。 |
|
fmt |
日期时间格式。 |
|
s |
自选分隔符,缺省默认分隔符是tab。省略参数s时,s前边的逗号可以省略。 |
|
k |
分段号。 |
|
n |
总段数。k和n都省略时表示读全文件。 |
选项:
|
@t |
f中第一行记录作为字段名,不使用本选项就使用_1,_2,…作为字段名,Fi是#i时仍保持原列名。 |
|
@b |
读取由export方式写出的二进制文件,支持参数Fi、k和n,不支持参数type和s,忽略选项@t@s@i@q。记录数少或不分段文件在分段读取时可能会有空段。 |
|
@e |
Fi在文件中不存在时将生成null,缺省将报错。 |
|
@s |
不拆分字段,读成单字段串构成的序表,忽略参数。 |
|
@i |
结果集只有1列时返回成序列。 |
|
@q |
剥离数据项两端引号,包括标题,处理转义;中间的引号不管。 |
|
@a |
将单引号作为引号处理,缺省不处理,与@q组合使用时也是将单引号作为引号处理。 |
|
@p |
解析时处理括号和引号匹配,括号内分隔符不算,同时引号外转义也处理。 |
|
@f |
不做任何解析,简单用分隔符拆成串。 |
|
@l |
允许续行,行尾是转义字符\。 |
|
@m |
多线程取数,加快读取文件速度。结果集次序不确定,有k:n参数时忽略该选项。常用于从大文件取数。配置信息中并行数需大于1。@o时可能错,有k:n参数时也是这样。 |
|
@c |
s缺省时用逗号分隔。 |
|
@o |
使用Excel标准转义,串中双个引号表示一个引号,其它字符不转义。 |
|
@k |
保留数据项两端的空白符,缺省将自动trim。 |
|
@d |
行内有数据不匹配类型和格式时删除该行,此时会按type检查类型;@p@q时括号和引号不匹配时也删除该行。 |
|
@n |
列数和第一行不匹配也作为错误处理,将被抛弃。 |
|
@v |
@d@n时检查类型匹配且出错时抛出违例,并且中断程序,输出出错行的内容。 |
|
@w |
将每行读成序列,返回序列的序列,列名也算作一行。 |
|
@r |
先读成串再解析,避免某些字符集的错误,使用该选项速度会慢。 |
返回值:
序表
示例:
|
|
A |
|
|
1 |
=file("D:\\score.txt").import() |
|
|
2 |
=file("D:\\score.txt").import@t() |
|
|
3 |
=file("D:\\score.txt").import(;1:2) |
省略选出字段和分隔符s,读取分段中的第一段数据。 |
|
4 |
=file("D:\\Department2.txt").import(;,"|") |
省略选出字段,k和n。读取全文件。 |
|
5 |
=file("D:\\Department2.txt").import(;1:3,"|") |
省略选出字段。 |
|
6 |
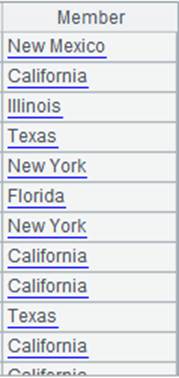
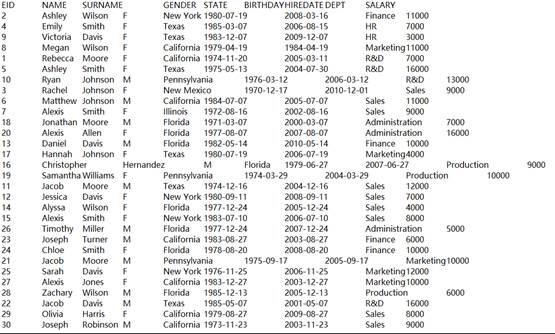
=file("D:\\EMPLOYEE.txt").import@c(GENDER;1:2) |
EMPLOYEE.txt内容以逗号分隔,读取第一段数据中的GENDER的字段值。 |
|
7 |
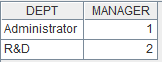
=file("D:\\Department5.txt").import@t(DEPT,MANAGER:int;1:3,"/") |
Department5.txt内容以斜杠分隔,按照指定字段DEPT和MANAGER读出:
|
|
8 |
=file("D:\\score.txt").import@e(EID;1:3) |
score.txt文件中没有字段EID,因此返回空。 |
|
9 |
|
|
|
10 |
=file("D:\\EMPLOYEE.btx").import@b(;1:2) |
读取f.export@z(A,x:F,…;)导出的集文件(分段二进制文件)EMPLOYEE.btx,并且取第1段内容。 |
|
11 |
=file("D:\\orders.txt").import@mt(;,",") |
文件比较大,加快读取文件速度。结果跟文件里的记录顺序不一致。 |
|
12 |
=file("D:\\StuName.txt").import@i() |
StuName.txt只有1列,返回成序列。 |
|
13 |
=file("D:\\test.txt").import@t() |
个别标题及字段值带有引号:
|
|
14 |
=file("D:\\test.txt").import@tq() |
使用@q选项,去除数据项两端的引号,包含标题,中间的不管:
|
|
15 |
=file("D:\\Sale1.txt").import() |
取出Sale1.txt中的所有记录。 |
|
16 |
=file("D:\\ Sale1.txt").import(#1,#3) |
取出Sale1.txt中的第1列与第3列。 |
|
17 |
=file("D:/Dep3.txt").import@cqo() |
Dep3.txt文件内容:
使用@o选项,串中两个引号表示一个引号,返回结果:
|
|
18 |
=file("D:/Dep1.txt").import@k() |
保留数据项两端的空白符。 |
|
19 |
=file("D:/Department1.txt").import@t(id:int,name;,"|") |
|
|
20 |
=file("D:/Department1.txt").import@td(id:int,name;,"|") |
行内有数据不匹配类型时删除该行。 |
|
21 |
=file("D:/Department1.txt").import@tdv(id:int,name;,"|") |
检查类型匹配且出错时抛出违例,中断程序,输出出错行的内容。 |
|
22 |
=file("Dep2.txt").import@tdn(id:int,name,surname;,"|") |
Dep2.txt文件内容:
第6、8行列数与第一行不匹配,故忽略:
|
|
23 |
=file("D://EMP1.txt").import@s(;1:2) |
不拆分字段,读成单字段串构成的序表,忽略参数: |
|
24 |
=file("D://EMP2.txt").import(#2:date:"yyyy/MM/dd") |
EMP2txt文件内容:
将文件里格式为yyyy/MM/dd的数据解析成日期类型的字段:
|
|
25 |
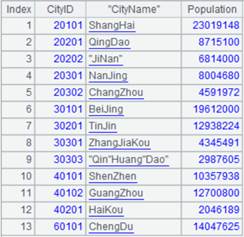
=file("City.txt").import@w() |
使用@w选项,返回序列的序列:
|
|
26 |
=file("D://t1.txt").import@c() |
t1.txt文件内容:
使用@c选项,分隔符缺省使用逗号,返回结果:
|
|
27 |
=file("D://t1.txt").import@cp() |
使用@p选项,解析时处理括号和引号匹配:
|
|
28 |
=file("D://t1.txt").import@cpa() |
使用@a选项,将单引号做为引号处理:
|
|
29 |
=file("D://t2.txt").import@l() |
t2.txt内容如下:
使用@l选项,行尾为转义符\时允许续行:
|
|
30 |
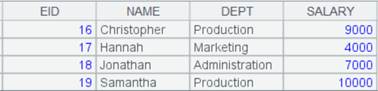
=file("D://t3.txt").import@f() |
使用@f选项,直接用分隔符拆成串:
|




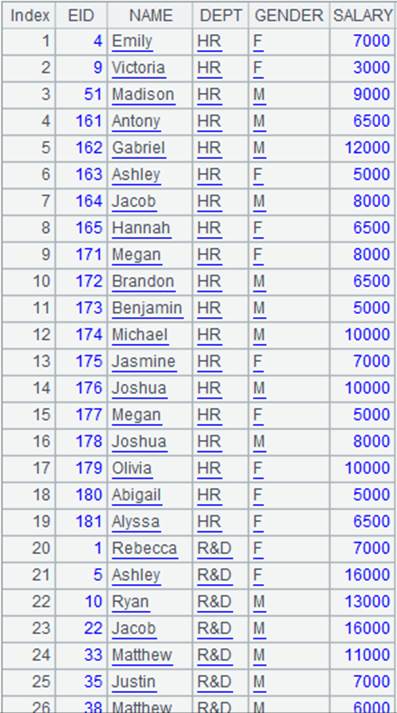
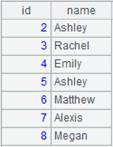

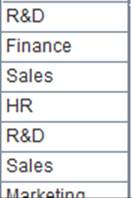
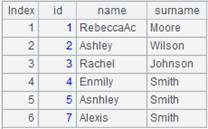





注意:
txt文件的格式:记录间用回车符隔开,字段间用自选分隔符隔开,缺省为tab键隔开。
相关概念:
T.import()
描述:
根据实表返回序表。
语法:
T.import(x:C,…;wi,...)
备注:
根据实表T返回序表,相当于T.cursor(...).fetch()。
参数:
|
T |
实表。 |
|
x |
表达式。 |
|
C |
列名。 |
|
wi |
过滤条件,缺省读取全集,多个条件之间用逗号隔开,为AND关系。除常规的过滤表达式外,过滤条件中还支持如下几种写法,其中K表示实表T中的字段: 1.K=w w通常使用表达式Ti.find(K)或Ti.pfind(K),Ti为序表,w为null或false时将被过滤掉;当w为表达式Ti.find(K)且被选出字段C,...中包含K时,K将被赋值为Ti的指引字段; 当w为表达式Ti.pfind(K)且被选出字段C,...中包含K时,K将被赋值为K在Ti 中的序号。 2.(K1=w1,…Ki=wi,w) Ki=wi为赋值表达式,参数wi通常可以使用表达式Ti.find(Ki)或Ti.pfind(K),Ti为序表;当wi为表达式Ti.find(Ki)且被选出字段C,...中包含Ki时,Ki将被赋值为Ti的指引字段; 当wi为表达式Ti.pfind(Ki)且被选出字段C,...中包含Ki时,Ki将被赋值为Ki在Ti 中的序号。 w为过滤表达式, w中可引用Ki。 3.K:Ti Ti为序表,用实表中Ki的值与Ti的键值作对比,匹配不上的将被过滤掉;当选出字段C,...中包含K时,K将被赋值为Ti的指引字段。 4.K:Ti:null 符合K:Ti的记录将被过滤掉。 5.K:Ti:# 用序号定位,根据实表中K的值去对比序表Ti的记录序号,对应不上的记录将被过滤掉;当选出字段C,...中包含K时,K将被赋值为Ti的指引字段。 |
选项:
|
@v |
生成纯序表列式。 |
|
@x |
完成后自动关闭T。 |
序表
示例:
|
|
A |
|
|
1 |
for 100 |
|
|
2 |
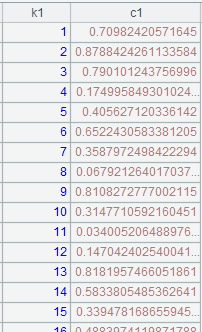
=to(10000).new(#:k1,rand():c1).sort@o(k1) |
生成数据。 |
|
3 |
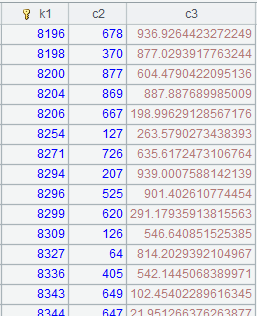
=to(10000).new(#:k1,rand(10000):c2,rand()*1000:c3).sort@o(k1) |
|
|
4 |
=A2.cursor() |
|
|
5 |
=A3.cursor() |
|
|
6 |
=file("D:\\tb1.ctx") |
创建组表基表。 |
|
7 |
=A6.create(#k1,c1) |
|
|
8 |
=A7.append(A4) |
|
|
9 |
=A7.attach(table4,c2,c3) |
|
|
10 |
=A9.append(A5) |
|
|
11 |
=A9.cursor(;c2<1000;2:3) |
将附表中c2<1000的记录分为3段,返回第2段的所有列组成的游标。 |
|
12 |
=A11.fetch() |
获得游标中的数据。 |
|
13 |
=A9.import@x(;c2<1000;2:3) |
结果与A12相同,完成后自动关闭A9实表。 |
多种过滤方式
|
|
A |
|
|
1 |
=file("emp.ctx") |
|
|
2 |
=A1.open() |
打开组表文件。 |
|
3 |
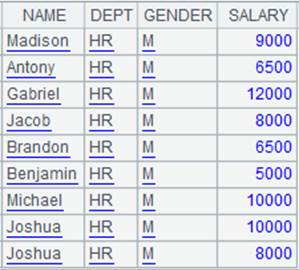
=A2.import() |
省略参数,返回实表中的所有数据 :
|
|
4 |
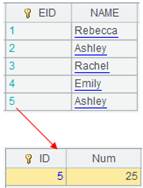
=5.new(~:ID,~*~:Num).keys(ID) |
生成ID为键的序表:
|
|
5 |
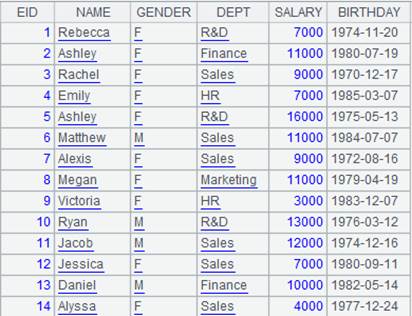
=A2.import(EID,NAME;EID=A4.find(EID)) |
使用K=w过滤方式,w是Ti.find(K),实表中使EID=A4.find(EID)计算结果为null或false的记录过滤掉;EID为选出字段,赋值为序表A4的指引字段:
|
|
6 |
=A2.import(EID,NAME;EID=A4.pfind(EID)) |
使用K=w过滤方式,w是Ti.pfind(K),实表中使EID=A4.pfind(EID)计算结果为null或false的记录过滤掉;EID为选出字段,赋值为EID在序表A4中的序号:
|
|
7 |
=A2.import(EID,NAME;EID:A4) |
使用K:Ti过滤方式,用实表中EID的值与序表的键值作对比,匹配不上的将被过滤掉
|
|
8 |
=A2.import(NAME,SALARY;EID:A4) |
K不被选出的情况,EID不是选出字段,仅过滤
|
|
9 |
=A2.import(EID,NAME;EID:A4:null) |
使用K:Ti:null过滤方式,用实表中EID的值与序表的键值作对比,可以匹配上的将被过滤掉
|
|
10 |
=A2.import(EID,NAME;EID:A4:#) |
使用K:Ti:#过滤方式,根据实表中EID的值去对比序表的记录序号,对应不上的记录将被过滤掉
|
|
11 |
=connect("demo").query("select top 2 NAME,GENDER from employee").keys(NAME) |
返回序表,键为NAME
|
|
12 |
=A2.import(EID,NAME;(EID=A4.find(EID),NAME=A11.find(NAME), EID!=null&&NAME!=null)) |
使用(K1=w1,…Ki=wi,w)过滤方式,返回符合所有条件的记录
|




T.import()
描述:
从虚表中取出序表。
语法:
T.import(xi:Ci,…)
备注:
从虚表T中取出序表,xi为字段表达式,Ci为序表的字段名,缺省为虚表的字段名,xi:Ci省略时取出所有字段。
参数:
|
T |
虚表。 |
|
xi |
字段表达式。 |
|
Ci |
结果序表的字段名。 |
返回值:
序表
示例:
|
|
A |
|
|
1 |
=create(file).record(["D:/file/pseudo/empT.ctx"]) |
|
|
2 |
=pseudo(A1) |
生成虚表对象。 |
|
3 |
从虚表中取出序表,无参数时取出所有字段:
|
|
|
4 |
从虚表中取出虚表,取出字段包含EID、NAME、SALARY,列名为eid、NAME、salary:
|

