cs.pjoin ()
描述:
语法
cs.pjoin(K:..,x:F,…; csi:z,Ki:…,xi:Fi,…; …)
备注:
游标cs附加计算,将cs与csi 根据关联键连接,结果将x:F,…与xi:Fi,…组成的序列返回到原游标cs中。
cs和csi 可以为游标或者排列,x:F,…缺省为cs的所有列。要求cs与csi对关联键有序。
cs和csi是一对多时,xi是聚合表达式。
cs和csi是多对一时,csi的记录将重复。
参数z控制连接方式,z只能是省略或者为null。z省略时为内连接;z为null时为左连接,z为null且xi:Fi全部省略时仅保留匹配不上的cs的记录。
当cs和csi 都是组表游标时,默认csi跟随cs跳块,即:做pjoin计算时,先取cs的数据,然后根据cs的取值范围去取csi中的数据,这样可以对csi起到过滤作用,提升计算效率。
该函数属于延迟计算函数。
参数:
|
cs |
游标/排列。 |
|
K |
cs中的关联键。 |
|
x |
cs的计算表达式。 |
|
F |
表达式x的字段名称。 |
|
csi |
游标/组表游标/排列。 |
|
z |
连接方式。 |
|
Ki |
csi中的关联键。 |
|
xi |
csi的计算表达式。 |
|
Fi |
表达式xi的字段名称。 |
选项:
|
@r |
当cs与cs1,cs2,...csi 都是组表游标,且cs1的数据量较小的情况,可使用该选项,此时cs跟随cs1跳块,可提升效率。 |
|
@f |
全连接,使用该选项时忽略参数z,不支持与@r同时使用。 |
|
@t |
cs与csi为组表游标且csi中有时间键时可用,使用该选项可将时间键作为关联键。与@f选项互斥。 |
返回值:
示例:
连接同维表:
|
|
A |
|
|
1 |
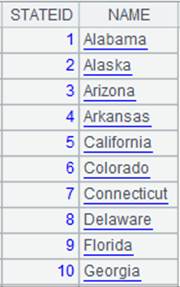
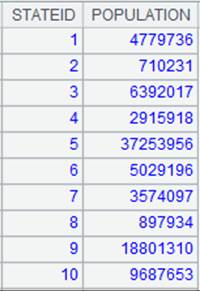
=connect("demo").cursor("select STATEID,NAME from STATENAME").sortx(STATEID) |
返回对STSTEID有序的游标,内容如下:
|
|
2 |
=connect("demo").query("select STATEID,POPULATION from STATEINFO").sort(STATEID) |
返回对STATEID有序的排列:
|
|
3 |
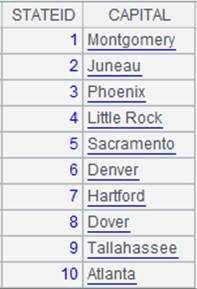
=connect("demo").query("select STATEID,CAPITAL from STATECAPITAL").sort(STATEID) |
返回对STATEID有序的排列:
|
|
4 |
=A1.pjoin(STATEID,STATEID:ID,NAME;A2,STATEID,POPULATION;A3,STATEID,CAPITAL) |
游标A1附加计算,根据关联键STATEID连接A1游标与A2、A3排列,然后将STATEID列的列名称定义为ID,返回A1游标, A1游标执行计算后数据内容如下:
|
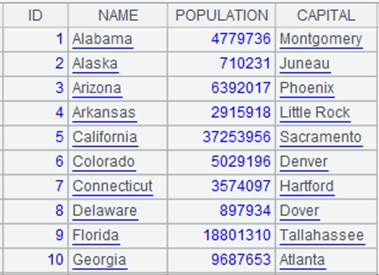
A和Ai是一对多时:
|
|
A |
|
|
1 |
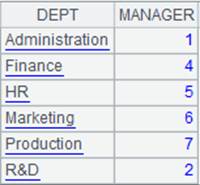
=demo.cursor("select top 6 DEPT,MANAGER from DEPARTMENT") |
返回游标,内容如下:
|
|
2 |
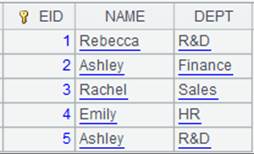
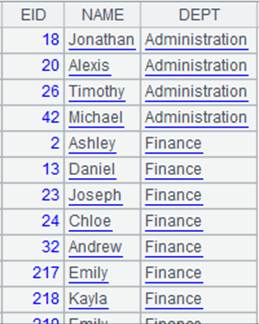
=demo.cursor("select EID,NAME,DEPT from EMPLOYEE").sortx(DEPT) |
返回游标,内容如下:
|
|
3 |
=A1.pjoin(DEPT;A2,DEPT,count(EID):Num) |
游标A1附加计算,A1与A2为一对多关系,根据DEPT连接游标A1与A2, 并计算每个DEPT下的EID数量,计算结果作为Num列,返回A1游标, A1游标执行计算后数据内容如下:
|

A和Ai是多对一时:
|
|
A |
|
|
1 |
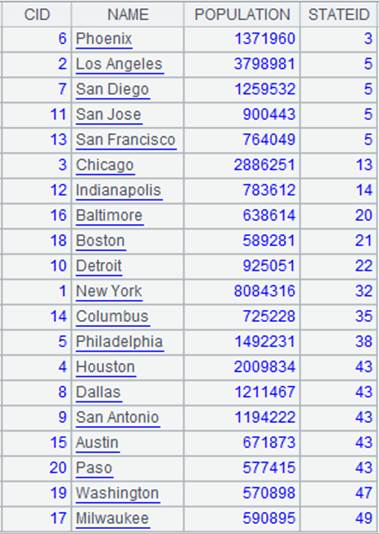
=connect("demo").cursor("SELECT top 20 CID,NAME,POPULATION,STATEID FROM CITIES").sortx(STATEID) |
返回游标,内容如下:
|
|
2 |
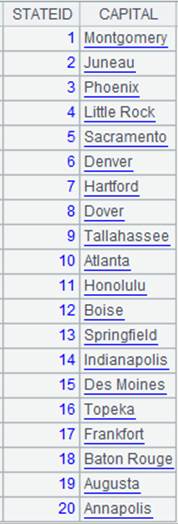
=connect("demo").cursor("SELECT top 20 STATEID,CAPITAL FROM STATECAPITAL").sortx(STATEID) |
返回游标,内容如下:
|
|
3 |
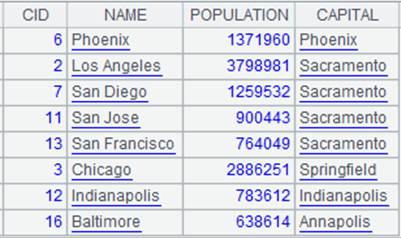
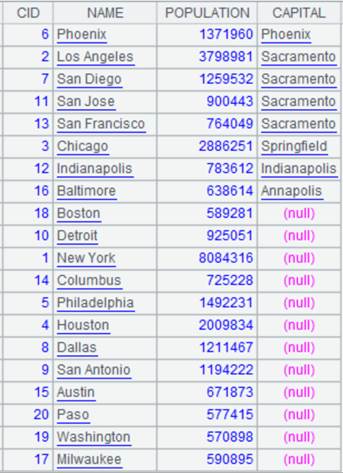
=A1.pjoin(STATEID,CID,NAME,POPULATION;A2,STATEID,CAPITAL ) |
游标A1附加计算,A1与A2为多对一关系,根据STATEID字段关联,A2的字段值会重复出现在结果集中,返回A1游标, A1游标执行计算后数据内容如下:
|
全连接:
|
|
A |
|
|
1 |
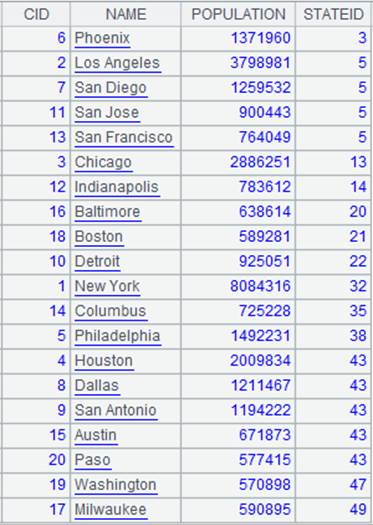
=connect("demo").cursor("SELECT top 20 CID,NAME,POPULATION,STATEID FROM CITIES").sortx(STATEID) |
返回游标,内容如下:
|
|
2 |
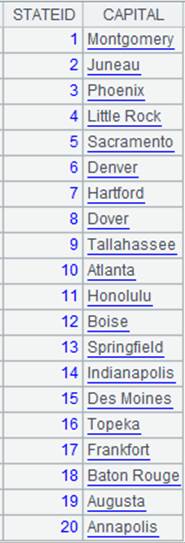
=connect("demo").cursor("SELECT top 20 STATEID,CAPITAL FROM STATECAPITAL").sortx(STATEID) |
返回游标,内容如下:
|
|
3 |
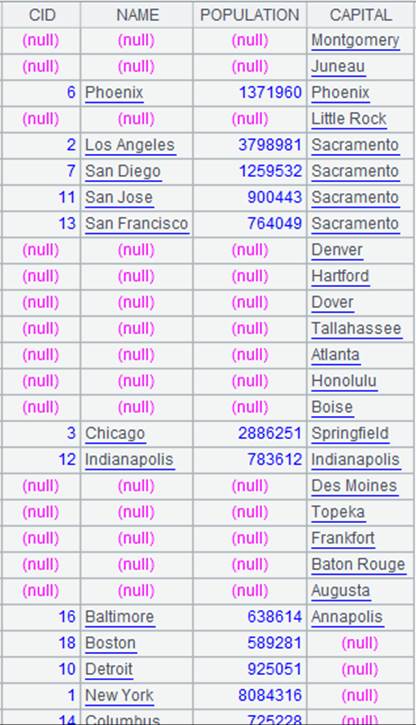
=A1.pjoin@f(STATEID,CID,NAME,POPULATION;A2,STATEID,CAPITAL ) |
游标A1附加计算,使用@f选项,全连接,关联不上的记录字段显示为null,返回A1游标, A1游标执行计算后数据内容如下:
|
左连接方式1:
|
|
A |
|
|
1 |
=connect("demo").cursor("SELECT top 20 CID,NAME,POPULATION,STATEID FROM CITIES").sortx(STATEID) |
返回游标,内容如下:
|
|
2 |
=connect("demo").cursor("SELECT top 20 STATEID,CAPITAL FROM STATECAPITAL").sortx(STATEID) |
返回游标,内容如下:
|
|
3 |
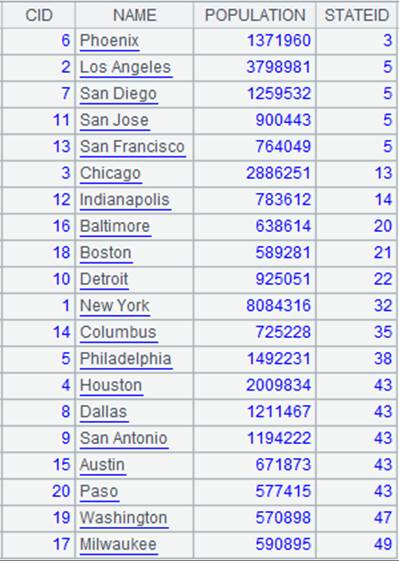
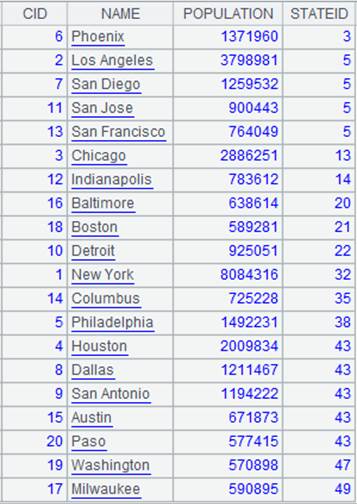
=A1.pjoin(STATEID,CID,NAME,POPULATION;A2:null,STATEID,CAPITAL ) |
游标A1附加计算,z参数为null时为左连接,A1中的记录全部列出,A2中关联不上的字段显示为null,返回A1游标, A1游标执行计算后数据内容如下:
|
左连接方式2:
|
|
A |
|
|
1 |
=connect("demo").cursor("SELECT top 20 CID,NAME,POPULATION,STATEID FROM CITIES").sortx(STATEID) |
返回游标,内容如下:
|
|
2 |
=connect("demo").cursor("SELECT top 20 STATEID,CAPITAL FROM STATECAPITAL").sortx(STATEID) |
返回游标,内容如下:
|
|
3 |
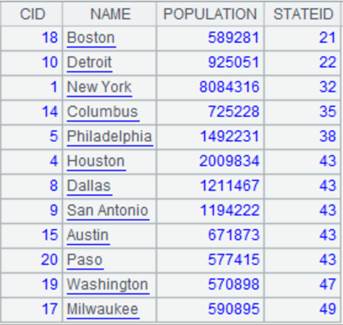
=A1.pjoin(STATEID;A2:null,STATEID) |
游标A1附加计算,z参数为null且参数xi:Fi省略时,仅保留匹配不上的A1的记录,返回A1游标, A1游标执行计算后数据内容如下:
|

连接组表游标:
|
|
A |
|
|
1 |
=file("DEPARTMENT.ctx").open().cursor() |
返回组表游标,内容如下:
|
|
2 |
=file("EMPLOYEE.ctx").open().cursor() |
返回组表游标,内容如下:
|
|
3 |
=A1.pjoin@r(DEPT;A2,DEPT,count(EID):Num) |
游标A1附加计算,A1与A2为一对多关系,根据DEPT连接游标A1与A2, 并计算每个DEPT下的EID数量,计算结果作为Num列,使用@r选项,返回A1游标, A1游标执行计算后数据内容如下:
|



csi中有时间键:
|
|
A |
|
|
1 |
=file("transaction.btx").cursor@b() |
返回游标,游标内容对UID、Time有序。 |
|
2 |
=file("trap.ctx") |
|
|
3 |
=A2.create@ty(#UID,#Time,Change,Amount) |
创建组表,UID为基本键,Time为时间键。 |
|
4 |
=A3.append@i(A1) |
将A1游标中的记录追加到组表文件trap.ctx中。 |
|
5 |
=A4.cursor() |
返回组表游标,组表数据内如下:
… …
|
|
6 |
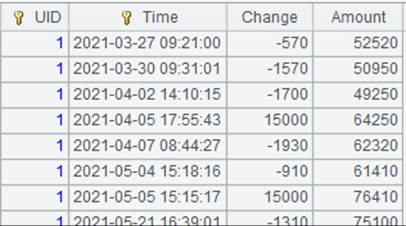
=demo.cursor("select top 5 EID, NAME, DEPT from EMPLOYEE ") |
返回游标。 |
|
7 |
=file("ep.ctx") |
|
|
8 |
=A7.create@y(#EID, NAME, DEPT) |
创建组表,EID为键。 |
|
9 |
=A8.append@i(A6) |
将A6游标中的记录追加到组表文件ep.ctx中。 |
|
10 |
返回组表游标,组表数据内容如下:
|
|
|
11 |
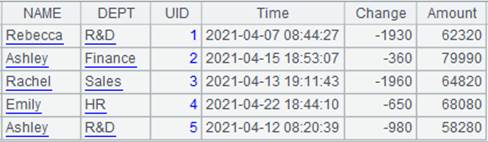
=A10.pjoin@t(EID:date(2021,5,1),NAME,DEPT;A5,UID:Time,UID,Time,Change,Amount) |
游标A10附加计算,连接组表游标A5与A10,组表trap.ctx中有时间键,使用@t选项,返回UID等于ID且2021-05-01日期前的最大Time值对应的记录,返回A10游标。 |
|
12 |
=A10.fetch() |
读取A10游标中的数据:
|