
- 数据类型
- 操作符
- 数学
- 字符串
- 日期时间
- 序列
- 序表
- 循环函数
- 关联运算
- 文件
- 数据库
- 游标
- 程序语句
- 系统与接口
- 集群
- 图形
- 外部库
- 组表
- 远程服务
- 简单 SQL
-
Function
- #@
- #c
- $( d)dql...
- $(db)sql;…
- ${macroExp}
- =expression
- >statement
- [a:b]
- @
- @x:…
- A()
- A. (x,…)
- [a1,…,an]
- abs()
- acos()
- acosh ()
- age()
- align()
- ali_ open ()
- ali_close()
- ali_query()
- alter()
- and ()
- append()
- argpost
- arguments (spl)
- array()
- asc ()
- asin()
- asinh()
- atan()
- atanh()
- attach()
- avg()
- base64 ()
- between()
- bi()
- bits()
- bit1(x)
- bit1(x,y)
- blob ()
- bool ()
- break {a}
- C
- Cr()
- calc()
- call()
- call path/spl( … )
- calls path/spl( … )
- callx()
- cand()
- canvas()
- case()
- ceil()
- cellname()
- cgroups()
- ch. ()
- channel()
- char()
- chardetect()
- charencode()
- chi_p ()
- chi2inv()
- chn()
- clear()
- clipboard ()
- close()
- cmp()
- cor ()
- comabs ()
- comangle ()
- combin()
- comconj ()
- comexp ()
- comimage()
- commit()
- compair ()
- complex()
- comreal ()
- comsign ()
- comstr ()
- comunwrap ()
- concat()
- conj()
- connect()
- contain()
- corskew()
- cos()
- cosh()
- count ()
- cov()
- covm()
- create()
- cs.(x)
- cuboid()
- cum()
- cumulate()
- cursor()
- date()
- datederive()
- dateinterval()
- datetime()
- day()
- days()
- decimal()
- delete()
- deq()
- derive()
- det()
- diff( )
- digits()
- directory()
- dis()
- dism()
- dql()
- dup()
- dynadb.close()
- dynadb.execute ()
- dyna_open()
- dynadb.query()
- dynadb.table ()
- E()
- E()
- elapse()
- elasticnet()
- end s
- enum()
- env()
- eq()
- error()
- eval()
- es_close ()
- es_delete ()
- es_export ()
- es_head ()
- es_open ()
- es_get ()
- es_post ()
- es_put ()
- exec()
- execute()
- exists()
- exp()
- export()
- exportavro ()
- eye()
- f@o(…)
- Faccrint()
- Faccrintm()
- fact()
- false
- Fcoupcd()
- Fcoups()
- Fdb()
- Fddb()
- Fdisc()
- Fduration()
- fetch()
- field()
- file()
- filename ()
- fill()
- fillcons ()
- fillfun ()
- fillmthd()
- find()
- Fintrate()
- finv()
- Firr()
- fisher_p()
- fjoin()
- float()
- floor()
- Fmirr()
- fname()
- fno()
- Fnper ()
- Fnpv()
- for
- fork
- format()
- Fpmt()
- Fprice()
- Frate()
- Freceived()
- freq ()
- Fsln()
- Fsyd()
- ftp_cd()
- ftp_open()
- ftp_close()
- ftp_dir()
- ftp_get()
- ftp_mget()
- ftp_mput()
- ftp_put()
- func()
- Fv()
- Fvdb()
- Fyield()
- get()
- gcd()
- gcs_ bucket ()
- gcs_ close ()
- gcs_ copy ()
- gcs_ file ()
- gcs_ list ()
- gcs_ open ()
- goto C
- group()
- groupi()
- groupn()
- groups()
- groupx()
- hash ()
- hbase_close()
- hbase_cmp()
- hbase_filter()
- hbase_filterlist()
- hbase_get()
- hbase_open()
- hbase_rest()
- hbase_scan()
- hdfs_open()
- hdfs_close()
- hdfs_dir()
- hdfs_download()
- hdfs_exists()
- hdfs_file()
- hdfs_upload()
- hdfs_write ()
- hive_open ()
- hive_close()
- hive_cursor()
- hive_execute ()
- hive_query()
- hosts()
- hour()
- htmlparse ()
- httpfile()
- httpupload()
- I ()
- i()
- icursor()
- icount ()
- id()
- if
- if()
- ifa()
- ifdate()
- ifind()
- ifn()
- ifnumber()
- ifpure()
- ifr()
- ifstring()
- ift()
- iftime()
- ifv()
- ifx_close()
- ifx_conn()
- ifx_cursor()
- ifx_listfrag()
- ifx_savefrag()
- ifx_setfrag()
- ifx_takefrag()
- import()
- importavro ()
- impute()
- index()
- inf()
- influx_close ()
- influx_insert ()
- influx_open ()
- influx_query ()
- influx2_close()
- influx2_delete()
- influx2_open()
- influx2_query()
- influx2_rest()
- insert()
- int()
- interval()
- inv()
- inverse()
- invoke()
- isalpha ()
- isdigit()
- isect()
- iselect()
- islower()
- ismiss ()
- ismissm ()
- isolate()
- isupper()
- iterate()
- j()
- join()
- joinx()
- json()
- jvm()
- k()
- kafka_close()
- kafka_commit()
- kafka_offset ()
- kafka_open()
- kafka_poll()
- kafka_send ()
- key()
- keys()
- kmeans()
- lasso ()
- lcm ()
- left()
- len()
- lg()
- like()
- linefit()
- lineplan ()
- ln()
- load()
- lock()
- long()
- lower()
- m()
- mae()
- makimamthd()
- max()
- maxp()
- mcumsum()
- mcursor()
- md5()
- median()
- memory()
- merge()
- mergex()
- mfind()
- mi()
- mid()
- millisecond()
- min()
- minp()
- minute()
- mmean()
- mnorm()
- mode()
- modify()
- mongo_close()
- mongo_open ()
- mongo_shell()
- month()
- movefile()
- movmthd ()
- mul()
- mse()
- mstd()
- msum()
- mvp()
- n.f(x)
- name()
- new()
- news()
- next {a}
- nodes()
- norm()
- norminv()
- not ()
- now()
- ntile()
- null
- number()
- numnorm()
- nvl()
- o()
- olap_close()
- olap_open ()
- olap_query ()
- ones()
- open()
- or()
- oss_ bucket ()
- oss_ close ()
- oss_ copy ()
- oss_ file ()
- oss_ list ()
- oss_ open ()
- output()
- p()
- pad()
- parse()
- paste ()
- pca ()
- pchipmthd ()
- pdate()
- pearson ()
- penum()
- periods()
- permut()
- pfind()
- pi()
- pivot()
- pjoin()
- pls()
- pmax()
- pmin()
- polyfit()
- pos()
- power()
- prior()
- proc()
- product()
- proportion()
- property()
- pseg()
- pselect()
- pseudo()
- psort()
- ptop()
- push()
- Qconnect()
- Qdirectory ()
- Qenv()
- Qfile()
- Qload()
- Qlock()
- Qmove()
- query()
- r(T,F)
- r.(x,…)
- r.F
- r.F=x
- r2dbc_close()
- r2dbc_exec()
- r2dbc_open()
- r2dbc_query()
- rand ()
- rands()
- range()
- rank()
- ranki()
- rankm ()
- ranks()
- read()
- record()
- redis_close ()
- redis_command()
- redis_open ()
- regex()
- register()
- remainder()
- rename()
- replace ()
- report_config()
- report_export ()
- report_open()
- report_run()
- reportlite_config ()
- reportlite_export ()
- reportlite_open()
- reportlite_run()
- reset()
- result
- return xi
- rgb()
- ridge()
- right()
- rmmiss ()
- rmmissdim ()
- rollback()
- round()
- row()
- run()
- rvs()
- s3_ bucket ()
- s3_ close ()
- s3_ copy ()
- s3_ file ()
- s3_ list ()
- s3_ open ()
- sap_client()
- sap_close()
- sap_cursor()
- sap_execute()
- sap_getparam()
- sap_table()
- savepoint()
- sbs()
- se()
- second()
- segp()
- select()
- seq()
- sert()
- setenum()
- sf_close()
- sf_open ()
- sf_query ()
- sf_wsdlclose ()
- sf_wsdlopen ()
- sf_wsdlquery ()
- sf_wsdlview ()
- sg ()
- shift()
- sign()
- sin()
- sinh()
- size()
- skew ()
- skip()
- sleep()
- smooth()
- sort()
- sortx()
- spark_ open()
- spark_close()
- spark_cursor()
- spark_query()
- spark_read()
- spearman ()
- splinemthd ()
- split()
- splserver()
- sqlparse()
- sqltranslate ()
- substr ()
- stax_close()
- stax_open()
- stax_cursor()
- stax_query()
- sqrt()
- step()
- string()
- structure
- sum()
- svm()
- swap()
- switch()
- syncfile(hs,p)
- system()
- T()
- tarcorskew()
- tan()
- tanh()
- time()
- tinv()
- to()
- top()
- total()
- transpose()
- trim()
- true
- try
- ttest_p ()
- typeof(x)
- union( )
- update()
- upper ()
- urlencode()
- uuid()
- v()
- var()
- was_ bucket ()
- was_ close ()
- was_ copy ()
- was_ file ()
- was_ list ()
- was_ open ()
- web_crawl()
- webhdfs()
- webhdfs_file()
- words()
- workday()
- workdays()
- write()
- ws_call()
- ws_client()
- xjoin()
- xjoinx()
- xlscell()
- xlsclose()
- xlsexport ()
- xlsimport ()
- xlsmove()
- xlsopen()
- xlswrite()
- xml()
- xor()
- xunion( )
- year()
- ym2_close ()
- ym2_env ()
- ym2_mcfload ()
- ym2_model ()
- ym2_pcfload ()
- ym2_pcfsave ()
- ym2_predict()
- ym2_result()
- zeros()
- zip()
- zip_add()
- zip_close()
- zip_compress()
- zip_del()
- zip_encrypt()
- zip_extract()
- zip_open()
- 交列
- 关系运算
- 十六进制长整数
- 取余求整
- 和列
- 四则运算
- 复合赋值
- 字符串
- 字符串拼接
- 对位运算
- 差列
- 并列
- 序列乘
- 序表常数
- 记录常数
- 异或列
- 循环函数中的表达式书写规则
- 批运算
- 标识符
- 相反数
- 空列
- 赋值
- 赋值计算
- 转义符
- 逻辑运算
- 长整数
- 单元格类型
- 代码块类型
- 图元
A.regex()
描述:
用正则表达式匹配序列中的字符串成员。
语法:
|
A.regex(rs,Fi) |
正则表达式rs无拆出项时,用数据类型为字符串的字段Fi和rs匹配。返回排列A中经过过滤后的新排列。Fi省略时用当前记录和rs匹配。 |
|
A.regex(rs;Fi,…) |
正则表达式rs有拆出项时,用正则表达式rs拆分序列A中的字符串成员,返回结果拼成以Fi为字段的序表。 |
备注:
用正则表达式rs匹配序列A中的字符串成员,返回结果拼成以Fi为字段的序表。
参数:
|
A |
成员为字符串的序列或排列。 |
|
rs |
正则表达式。 拆出项指的是以分隔符分隔的多个正则表达式,并且每个正则表达式用括号括起来。每个拆出项匹配按顺序对应的字段。例如:"(.*),(a.*)" 为逗号分隔的两个拆出项。 |
|
Fi |
字段名,数据类型为字符串。 |
选项:
|
@c |
大小写不敏感。 |
|
@u |
使用unicode。 |
返回值:
序表
示例:
|
|
A |
|
|
1 |
=demo.query("select NAME,SURNAME from EMPLOYEE") |
|
|
2 |
=A1.(~. array().concat@c()) |
转换为字串序列:
|
|
3 |
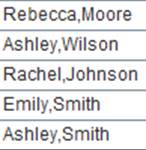
=A2.regex("A.*") |
省略Fi,默认用当前记录和rs匹配:
|
|
4 |
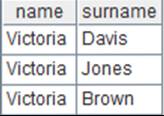
=A2.regex("(V.*),(.*)";name,surname) |
对A2成员正则匹配后返回序表:
|
|
5 |
=file("D:\\a.txt").import@ts() |
|
|
6 |
=A5.(#1).regex@c("(.*),(a.*)";id,name) |
匹配姓名以a或A开头的人员:
|
|
7 |
=demo.query("select 部门,姓名 from 员工表") |
|
|
8 |
=A7.(~.array().concat@c()) |
|
|
9 |
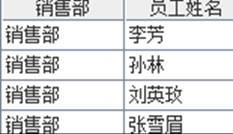
=A8.regex@u("(\\u9500\\u552e\\u90e8),(.*)";销售部,员工姓名) |
使用unicode匹配销售部:
|
|
10 |
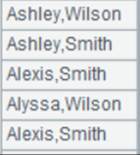
=A1.regex("V.*",NAME) |
正则表达式rs无拆出项时,用数据类型为字符串的字段Fi和rs匹配:
|



相关概念: