
建模
本章节主要介绍建模前模型选项的配置,执行建模操作,以及建模后模型文件信息。
模型选项
模型选项模块是对当前模型进行设置,模型参数的配置会影响模型质量。模型选项中包含对【常规】、【二分类模型】、【回归模型】、【多分类模型】的设置。
常规
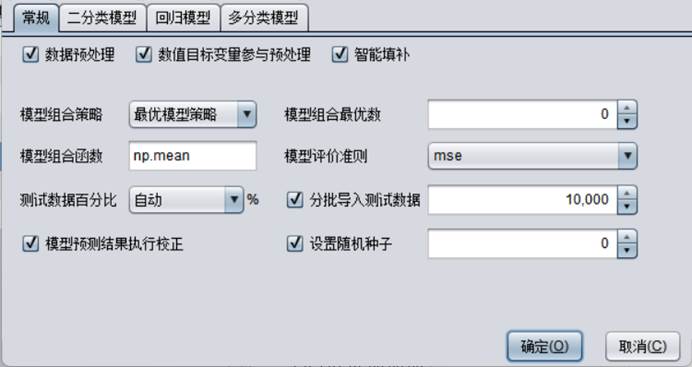
【数据预处理】:决定建模前是否对数据进行预处理。
【数值目标变量参与预处理】:决定预建模前是否对数值目标变量进行预处理。
【智能填补】:采用智能补缺算法对缺失值进行补充。
【模型组合策略】:分为两种,最优模型策略、简单模型组合。最优模型策略表示选出最佳的前几个模型进行组合,计算量较多。简单模型组合表示不进行筛选,而是将所有定义出的模型组合到一起,计算量较少。
【模型组合最优数】:控制如何选择最优模型组合。0表示选择组合后效果最好的模型;大于0表示选择固定的前n个最好模型;小于0表示在最好的前n个模型中,选择使组合效果最好的模型。默认是0。
【模型组合函数】:定义多个模型通过什么方法组合到一起,可选numpy中的任一基本函数。默认函数是np.mean。
【模型评价准则】:二分类模型可选auc、cross_entropy、ks、ap、recall、lift、f1_score,默认为auc;回归模型可选 mse、mae、mape、r2,默认为mse;多分类模型可选cross_entropy。
【测试数据百分比】:设定用于测试打分的数据百分比。
【分批导入测试数据】:设定分批导入测试数据的条数。
【模型预测结果执行矫正】:默认会执行校正。执行校正时,模型打分会按照原始数据的平均值进行校正;不执行校正时,模型打分会保持抽样配平后的平均值不变。
【设置随机种子】:控制建模随机性。默认是0。
当设为空值时,两次运行会得到随机的结果。
当设为整数n时,两次运行n值相同,会得到相同的结果;n值不同,会得到不同的结果。
注:当值为n时,会强制所有模型的random_state参数都被设置为该值,无法自定义。
二分类模型
【二分类模型】主要用来配置建模时用到的二分类模型,选出的模型将会参与建模流程。
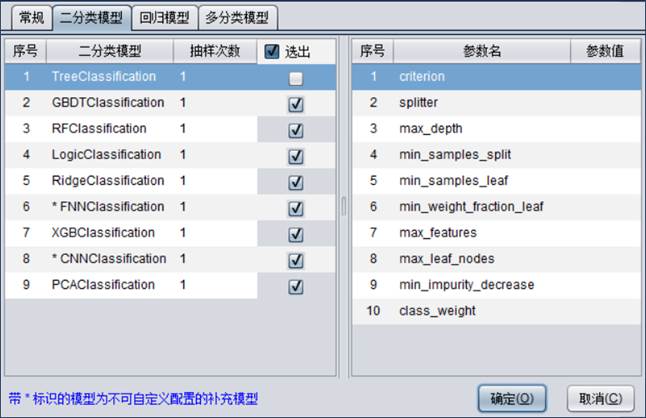
二分类模型包含9种模型:TreeClassificatio、GBDTClassification、RFClassification、LogicClassification、RidgeClassification、FNNClassification、XGBClassification、CNNClassification、PCAClassification
抽样次数是指某个模型在建模时使用几份样本。
关于二分类模型的一些参数配置说明,请参考附录1。
附录1:二分类模型参数
类型与范围的说明:每种类型后面以区间形式标识取值范围,中括号为闭区间,小括号为开区间。部分int和float有大括号,表示参考的下拉框取值,格式为{起始值, 结束值, 间隔},如{1, 5, 1}=[1,2,3,4,5],{1, 6, 2}=[1,3,5]。string类型的全部可能取值列入下拉框,不可键入;null列入下拉框,不可键入;bool类型只有true和false,全部列入下拉框,不可键入;int和float可以键入,若有参考值则将参考值列入下拉框。
部分float型,若正好为整数,需要加.0才可以,例如0.0, 1.0。
TreeClassification
|
参数 |
类型与范围 |
说明 |
|
criterion |
string: ["gini", "entropy"] |
评估分裂节点的指标 |
|
splitter |
string: ["best", "random"] |
在每个节点选择分裂的策略 |
|
max_depth |
int: [1, +∞), {1, 100, 1} null |
树最大深度 |
|
min_samples_split |
int: [1, +∞), {10, 1000, 10} float: (0, 1) |
节点分裂所需的最小样本数。int表示最小样本数,float表示最小样本占总体比例 |
|
min_samples_leaf |
int: [1, +∞), {10, 1000, 10} float: (0, 1) |
叶子节点的最小样本数。int表示最小样本数,float表示最小样本占总体比例 |
|
min_weight_fraction_leaf |
float: [0, 1), {0, 0.1, 0.01} |
叶节点上(所有输入样本的)权值之和的最小权重 |
|
max_features |
int: [1, +∞), {10, 1000, 10} float: (0, 1] string: ["auto", "sqrt", "log2"] null |
搜索最佳分裂时所用的最大变量个数。 If int, 最大变量个数 If float, 最大变量比例 If "auto", then max_features=sqrt(n_features). If "sqrt", then max_features=sqrt(n_features). If "log2", then max_features=log2(n_features). If null, then max_features=n_features. |
|
max_leaf_nodes |
int: [1, +∞), {10, 1000, 10} null |
使用best-first fashion生成剪枝树的最大叶子节点数。null表示不限制最大叶子节点数。 |
|
min_impurity_decrease |
float: [0, 1) |
分裂节点时所需的最低impurity decrease。 |
|
class_weight |
string: [“balanced”] null |
Weights associated with classes in the form {class_label: weight}. |
GBDTClassification
|
参数 |
类型 |
说明 |
|
loss |
string: ["deviance", "exponential"] |
损失函数 |
|
learning_rate |
float: (0, 1), {0.1, 0.9, 0.1} |
学习率,越大速度越快,但可能找不到最优解 |
|
n_estimators |
int: [1, +∞), {10, 500, 10} |
boosting stages数量 |
|
subsample |
float: (0, 1], {0.1, 1, 0.1} |
每一个基本学习机使用的样本比例 |
|
criterion |
string: ["mse", "friedman_mse", "mae"] |
评估分裂节点的指标 |
|
min_samples_split |
int: [1, +∞), {10, 1000, 10} float: (0, 1) |
节点分裂所需的最小样本数。int表示最小样本数,float表示最小样本占总体比例 |
|
min_samples_leaf |
int: [1, +∞), {10, 1000, 10} float: (0, 1) |
叶子节点的最小样本数。int表示最小样本数,float表示最小样本占总体比例 |
|
min_weight_fraction_leaf |
float: [0, 1), {0, 0.1, 0.01} |
叶节点上(所有输入样本的)权值之和的最小权重 |
|
max_depth |
int: [1, +∞), {1, 100, 1} null |
树最大深度 |
|
min_impurity_decrease |
float: [0, 1) |
分裂节点时所需的最低impurity decrease。 |
|
max_features |
int: [1, +∞), {10, 1000, 10} float: (0, 1] string: ["auto", "sqrt", "log2"] null |
搜索最佳分裂时所用的最大变量个数。 If int, 最大变量个数 If float, 最大变量比例 If "auto", then max_features=sqrt(n_features). If "sqrt", then max_features=sqrt(n_features). If "log2", then max_features=log2(n_features). If null, then max_features=n_features. |
|
max_leaf_nodes |
int: [1, +∞), {10, 1000, 10} null |
使用best-first fashion生成剪枝树的最大叶子节点数。null表示不限制最大叶子节点数。 |
|
warm_start |
bool |
true使用前一次迭代的结果,false不使用前一次结果 |
RFClassification
|
参数 |
类型 |
说明 |
|
n_estimators |
int: [1, +∞), {10, 500, 10} |
树的数量 |
|
criterion |
string: ["gini", "entropy"] |
评估分裂节点的指标 |
|
max_depth |
int: [1, +∞), {1, 100, 1} null |
树最大深度 |
|
min_samples_split |
int: [1, +∞), {10, 1000, 10} float: (0, 1) |
节点分裂所需的最小样本数。int表示最小样本数,float表示最小样本占总体比例 |
|
min_samples_leaf |
int: [1, +∞), {10, 1000, 10} float: (0, 1) |
叶子节点的最小样本数。int表示最小样本数,float表示最小样本占总体比例 |
|
min_weight_fraction_leaf |
float: [0, 1), {0, 0.1, 0.01} |
叶节点上(所有输入样本的)权值之和的最小权重 |
|
max_features |
int: [1, +∞), {10, 1000, 10} float: (0, 1] string: ["auto", "sqrt", "log2"] null |
搜索最佳分裂时所用的最大变量个数。 If int, 最大变量个数 If float, 最大变量比例 If "auto", then max_features=sqrt(n_features). If "sqrt", then max_features=sqrt(n_features). If "log2", then max_features=log2(n_features). If null, then max_features=n_features. |
|
max_leaf_nodes |
int: [1, +∞), {10, 1000, 10} null |
使用best-first fashion生成剪枝树的最大叶子节点数。null表示不限制最大叶子节点数。 |
|
min_impurity_decrease |
float: [0, 1) |
分裂节点时所需的最低impurity decrease。 |
|
bootstrap |
bool |
生成树时是否使用bootstrap |
|
oob_score |
bool |
是否使用out-of-bag samples估计准确率 |
|
warm_start |
bool |
true使用前一次迭代的结果,false不使用前一次结果 |
|
class_weight |
string: [“balanced”] null |
Weights associated with classes in the form {class_label: weight}. |
LogicClassification
|
参数 |
类型 |
说明 |
|
penalty |
string: ["l1", "l2", "elasticnet", "none"] |
正则化惩罚项。"newton-cg", "sag" and "lbfgs" solvers仅支持"l2"; "elasticnet" 仅支持‘saga’ solver。"none"表示不做正则化,不支持liblinear solver。 |
|
dual |
bool |
Dual or primal formulation. Dual formulation is only implemented for l2 penalty with liblinear solver. Prefer dual=False when n_samples > n_features. |
|
tol |
float: (0, 1) |
停止迭代的容忍值 |
|
C |
float: (0, 1] |
Inverse of regularization strength; 必须是正数. |
|
fit_intercept |
bool |
是否包含截距项 |
|
intercept_scaling |
float: (0, 1] |
仅在solver="liblinear"时有效, |
|
class_weight |
string: [“balanced”] null |
Weights associated with classes in the form {class_label: weight}. |
|
solver |
string: ["newton-cg", "lbfgs", "liblinear", "sag", "saga"] |
最优化算法 |
|
max_iter |
int: [1, +∞), {10, 500, 10} |
最大迭代次数,仅在solver=["newton-cg", "lbfgs", "sag"]时有效 |
|
multi_class |
string: ["ovr", "multinomial", "auto"] |
处理多分类时的算法。"ovr"对每个分类单独建模,"multinomial"不能用于solver="liblinear" |
|
warm_start |
bool |
true使用前一次迭代的结果,false不使用前一次结果 |
RidgeClassification
|
参数 |
类型 |
说明 |
|
alpha |
float: [0, +∞], {0.0, 10.0, 0.1} |
正则化强度,必须为正数 |
|
fit_intercept |
bool |
是否包含截距项 |
|
normalize |
bool |
是否将数据标准化 |
|
max_iter |
int: [1, +∞), {10, 500, 10} null |
最大迭代次数 |
|
tol |
float: (0, 1) |
最终解的精度 |
|
class_weight |
string: [“balanced”] null |
Weights associated with classes in the form {class_label: weight}. If not given, all classes are supposed to have weight one. "balanced"自动调整。 |
|
solver |
string: ["auto", "svd", "cholesky", "lsqr", "sparse_cg", "sag", "saga"] |
最优化算法 |
FNNClassification、CNNClassification
由于神经网络的特殊性,此模型参数暂时无法开放。
XGBClassification
|
参数 |
类型 |
说明 |
|
max_depth |
int: [1, +∞), {1, 100, 1} |
树最大深度 |
|
learning_rate |
float: (0, 1), {0.1, 0.9, 0.1} |
学习率,越大速度越快,但可能找不到最优解 |
|
n_estimators |
int: [1, +∞), {10, 500, 10} |
booster trees数量 |
|
objective |
string: ["binary:logistic", "binary:logitraw", "binary:hinge"] |
学习目标 binary:logistic: 二分类logistic回归, 输出概率; binary:logitraw: 二分类logistic回归, 输出logistic变换前的打分; binary:hinge: 二分类hinge loss,直接输出0或1分类,而非概率。 |
|
booster |
string: ["gbtree", "gblinear", "dart"] |
使用booster种类 |
|
gamma |
float: [0, +∞) |
分裂节点时所需的最小损失降低值。 |
|
min_child_weight |
int: [1, +∞), {10, 1000, 10} |
子节点最小样本权重和 |
|
max_delta_step |
int: [0, +∞), {0, 10, 1} |
在每棵树的权重估计中,允许的最大delta步长。 |
|
subsample |
float: (0, 1], {0.1, 1.0, 0.1} |
用于训练模型的子样本占整个样本集合的比例。 |
|
colsample_bytree |
float: (0, 1], {0.1, 1.0, 0.1} |
在建立树时对特征采样的比例。 |
|
colsample_bylevel |
float: (0, 1], {0.1, 1.0, 0.1} |
分裂时,在每个水平层次上,对列的采样比例。 |
|
reg_alpha |
float: [0, +∞], {0.0, 10.0, 0.1} |
L1正则项 |
|
reg_lambda |
float: [0, +∞], {0.0, 10.0, 0.1} |
L2正则项 |
|
scale_pos_weight |
float: (0, +∞) |
调节正负样本平衡,负样本/正样本 |
|
base_score |
float: (0, 1), {0.1, 0.9, 0.1} |
预测值的初始值 |
PCAClassification
|
参数 |
类型 |
说明 |
|
n_components |
int or null: [1, min(行数, 列数)] |
保留主成分个数,null表示自动设置,默认为null |
|
whiten |
bool |
是否进行单位根变换 |
|
svd_solver |
string: ["auto", "full", "arpack", "randomized"] |
主成分求解方法,默认为full |
|
tol |
float: (0, 1) |
求解精度,默认0.0001 |
|
fit_intercept |
bool |
是否包含截距项 |
|
max_iter |
int: [1, +∞), {100, 1000, 100} |
最大迭代次数 |
|
reg_solver |
string: ["newton-cg", "lbfgs", "sag", "saga"] |
回归求解方法,默认"lbfgs" |
|
warm_start |
bool |
true使用前一次迭代的结果,false不使用前一次结果 |
回归模型
【回归模型】主要用来配置建模时用到的回归模型,选出的模型将会参与建模流程。
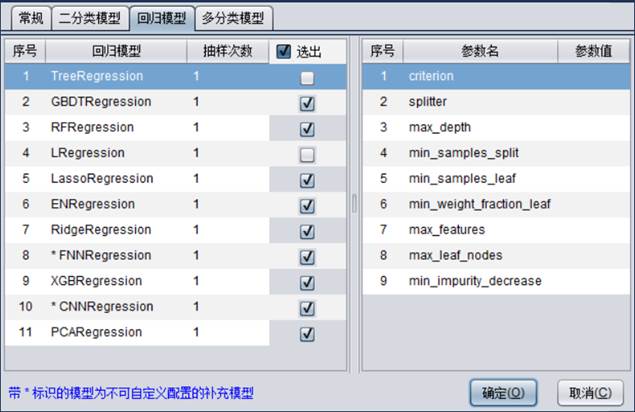
回归模型包含11种模型:TreeRegression、GBDTRegression、RFRegression、LRegression、LassoRegression、ENRegression、RidgeRegression、FNNRegression、XGBRegression、CNNRegression、PCARegression
抽样次数是指某个模型在建模时使用几份样本。
关于回归模型的一些参数配置说明,请参考附录2。
附录2:回归模型参数
类型与范围的说明:每种类型后面以区间形式标识取值范围,中括号为闭区间,小括号为开区间。部分int和float有大括号,表示参考的下拉框取值,格式为{起始值, 结束值, 间隔},如{1, 5, 1}=[1,2,3,4,5],{1, 6, 2}=[1,3,5]。string类型的全部可能取值列入下拉框,不可键入;null列入下拉框,不可键入;bool类型只有true和false,全部列入下拉框,不可键入;int和float可以键入,若有参考值则将参考值列入下拉框。
部分float型,若正好为整数,需要加.0才可以,例如0.0, 1.0。
TreeRegression
|
参数 |
类型 |
说明 |
|
criterion |
string: ["mse", "friedman_mse", "mae"] |
评估分裂节点的指标 |
|
splitter |
string: ["best", "random"] |
在每个节点选择分裂的策略 |
|
max_depth |
int: [1, +∞), {1, 100, 1} null |
树最大深度 |
|
min_samples_split |
int: [1, +∞), {10, 1000, 10} float: (0, 1) |
节点分裂所需的最小样本数。int表示最小样本数,float表示最小样本占总体比例 |
|
min_samples_leaf |
int: [1, +∞), {10, 1000, 10} float: (0, 1) |
叶子节点的最小样本数。int表示最小样本数,float表示最小样本占总体比例 |
|
min_weight_fraction_leaf |
float: [0, 1), {0, 0.1, 0.01} |
叶节点上(所有输入样本的)权值之和的最小权重 |
|
max_features |
int: [1, +∞), {10, 1000, 10} float: (0, 1] string: ["auto", "sqrt", "log2"] null |
搜索最佳分裂时所用的最大变量个数。 If int, 最大变量个数 If float, 最大变量比例 If "auto", then max_features=sqrt(n_features). If "sqrt", then max_features=sqrt(n_features). If "log2", then max_features=log2(n_features). If null, then max_features=n_features. |
|
max_leaf_nodes |
int: [1, +∞), {10, 1000, 10} null |
使用best-first fashion生成剪枝树的最大叶子节点数。null表示不限制最大叶子节点数。 |
|
min_impurity_decrease |
float: [0, 1) |
分裂节点时所需的最低impurity decrease。 |
GBDTRegression
|
参数 |
类型 |
说明 |
|
loss |
string: ["ls", "lad", "huber", "quantile"] |
损失函数 |
|
learning_rate |
float: (0, 1), {0.1, 0.9, 0.1} |
学习率,越大速度越快,但可能找不到最优解 |
|
n_estimators |
int: [1, +∞), {10, 500, 10} |
boosting stages数量 |
|
subsample |
float: (0, 1], {0.1, 1, 0.1} |
每一个基本学习机使用的样本比例 |
|
criterion |
string: ["mse", "friedman_mse", "mae"] |
评估分裂节点的指标 |
|
min_samples_split |
int: [1, +∞), {10, 1000, 10} float: (0, 1) |
节点分裂所需的最小样本数。int表示最小样本数,float表示最小样本占总体比例 |
|
min_samples_leaf |
int: [1, +∞), {10, 1000, 10} float: (0, 1) |
叶子节点的最小样本数。int表示最小样本数,float表示最小样本占总体比例 |
|
min_weight_fraction_leaf |
float: [0, 1), {0, 0.1, 0.01} |
叶节点上(所有输入样本的)权值之和的最小权重 |
|
max_depth |
int: [1, +∞), {1, 100, 1} null |
树最大深度 |
|
min_impurity_decrease |
float: [0, 1) |
分裂节点时所需的最低impurity decrease。 |
|
max_features |
int: [1, +∞), {10, 1000, 10} float: (0, 1] string: ["auto", "sqrt", "log2"] null |
搜索最佳分裂时所用的最大变量个数。 If int, 最大变量个数 If float, 最大变量比例 If "auto", then max_features=sqrt(n_features). If "sqrt", then max_features=sqrt(n_features). If "log2", then max_features=log2(n_features). If null, then max_features=n_features. |
|
alpha |
float: (0, 1), {0.1, 0.9, 0.1} |
The alpha-quantile of the huber loss function and the quantile loss function. Only if loss='huber' or loss='quantile' |
|
max_leaf_nodes |
int: [1, +∞), {10, 1000, 10} null |
使用best-first fashion生成剪枝树的最大叶子节点数。null表示不限制最大叶子节点数。 |
|
warm_start |
bool |
true使用前一次迭代的结果,false不使用前一次结果 |
RFRegression
|
参数 |
类型 |
说明 |
|
n_estimators |
int: [1, +∞), {10, 500, 10} |
树的数量 |
|
criterion |
string: ["mse", "mae"] |
评估分裂节点的指标 |
|
max_depth |
int: [1, +∞), {1, 100, 1} null |
树最大深度 |
|
min_samples_split |
int: [1, +∞), {10, 1000, 10} float: (0, 1) |
节点分裂所需的最小样本数。int表示最小样本数,float表示最小样本占总体比例 |
|
min_samples_leaf |
int: [1, +∞), {10, 1000, 10} float: (0, 1) |
叶子节点的最小样本数。int表示最小样本数,float表示最小样本占总体比例 |
|
min_weight_fraction_leaf |
float: [0, 1), {0, 0.1, 0.01} |
叶节点上(所有输入样本的)权值之和的最小权重 |
|
max_features |
int: [1, +∞), {10, 1000, 10} float: (0, 1] string: ["auto", "sqrt", "log2"] null |
搜索最佳分裂时所用的最大变量个数。 If int, 最大变量个数 If float, 最大变量比例 If "auto", then max_features=sqrt(n_features). If "sqrt", then max_features=sqrt(n_features). If "log2", then max_features=log2(n_features). If null, then max_features=n_features. |
|
max_leaf_nodes |
int: [1, +∞), {10, 1000, 10} null |
使用best-first fashion生成剪枝树的最大叶子节点数。null表示不限制最大叶子节点数。 |
|
min_impurity_decrease |
float: [0, 1) |
分裂节点时所需的最低impurity decrease。 |
|
bootstrap |
bool |
生成树时是否使用bootstrap |
|
oob_score |
bool |
是否使用out-of-bag samples估计准确率 |
|
warm_start |
bool |
true使用前一次迭代的结果,false不使用前一次结果 |
LRegression
|
参数 |
类型 |
说明 |
|
fit_intercept |
bool |
是否包含截距项 |
|
normalize |
bool |
是否将数据标准化 |
LassoRegression
|
参数 |
类型 |
说明 |
|
fit_intercept |
bool |
是否包含截距项 |
|
alpha |
float or null: [0, +∞], {0.0, 10.0, 0.1} |
正则惩罚系数,null表示自动设置,若是float,则cv和max_n_alphas不可用。 |
|
normalize |
bool |
是否将数据标准化 |
|
precompute |
string: ["auto"] bool |
是否预先计算Gram矩阵来提速 |
|
max_iter |
int: [1, +∞), {10, 500, 10} |
最大迭代次数 |
|
cv |
int: [2, 20] |
交叉验证折数 |
|
max_n_alphas |
int: [1, +∞) , {100, 1000, 100} |
交叉验证搜索的alpha个数 |
|
positive |
bool |
是否强制系数为正 |
ENRegression
|
参数 |
类型 |
说明 |
|
alpha |
float or null: : [0, +∞], {0.0, 10.0, 0.1} |
与惩罚项相乘的常数,null表示自动设置,默认为null。 |
|
l1_ratio |
float or null: [0, 1], {0.0, 1.0, 0.1} |
混合参数,l1_ratio=0为L2,l1_ratio=1为L1,0与1之间为二者的混合比例,null表示自动设置,默认为null。 |
|
n_alphas |
int: [1, +∞), {100, 1000, 100} |
搜索alpha数量,当alpha为float时,此参数不可用。 |
|
cv |
int: [2, 20] |
交叉验证折数,当alpha和l1_ratio同时为float时,此参数不可用。 |
|
fit_intercept |
bool |
是否包含截距项 |
|
normalize |
bool |
是否将数据标准化 |
|
precompute |
bool |
是否预先计算Gram矩阵来提速 |
|
max_iter |
int: [1, +∞), {10, 500, 10} |
最大迭代次数 |
|
tol |
float: (0, 1) |
停止迭代的容忍值 |
|
warm_start |
bool |
true使用前一次迭代的结果,false不使用前一次结果,cv不可用时,此参数可用,cv可用时,此参数不可用。 |
|
positive |
bool |
是否强制系数为正 |
|
selection |
string: ["cyclic", "random"] |
"cyclic"表示按变量循环迭代,"random"表示随机迭代系数。 |
RidgeRegression
|
参数 |
类型 |
说明 |
|
alpha |
float: : [0, +∞], {0.0, 10.0, 0.1} |
正则化强度,必须为正数 |
|
fit_intercept |
bool |
是否包含截距项 |
|
normalize |
bool |
是否将数据标准化 |
|
max_iter |
int: [1, +∞), {10, 500, 10} null |
最大迭代次数 |
|
tol |
float: (0, 1) |
最终解的精度 |
|
solver |
string: ["auto", "svd", "cholesky", "lsqr", "sparse_cg", "sag", "saga"] |
最优化算法 |
FNNRegression、CNNRegression
由于神经网络的特殊性,此模型参数暂时无法开放
XGBRegression
|
参数 |
类型 |
说明 |
|
max_depth |
int: [1, +∞), {1, 100, 1} |
树最大深度 |
|
learning_rate |
float: (0, 1), {0.1, 0.9, 0.1} |
学习率,越大速度越快,但可能找不到最优解 |
|
n_estimators |
int: [1, +∞), {10, 500, 10} |
booster trees数量 |
|
objective |
string: ["reg:squarederror", "reg:squaredlogerror", "reg:logistic"] |
学习目标 reg:squarederror: 平方损失回归; reg:squaredlogerror:对数平方损失回归; reg:logistic: logistic回归。 |
|
booster |
string: ["gbtree", "gblinear", "dart"] |
使用booster种类 |
|
gamma |
float: [0, +∞) |
分裂节点时所需的最小损失降低值。 |
|
min_child_weight |
int: [1, +∞), {10, 1000, 10} |
子节点最小样本权重和 |
|
max_delta_step |
int: [0, +∞), {0, 10, 1} |
在每棵树的权重估计中,允许的最大delta步长。 |
|
subsample |
float: (0, 1], {0.1, 1.0, 0.1} |
用于训练模型的子样本占整个样本集合的比例。 |
|
colsample_bytree |
float: (0, 1], {0.1, 1.0, 0.1} |
在建立树时对特征采样的比例。 |
|
colsample_bylevel |
float: (0, 1], {0.1, 1.0, 0.1} |
分裂时,在每个水平层次上,对列的采样比例。 |
|
reg_alpha |
float: [0, +∞], {0.0, 10.0, 0.1} |
L1正则项 |
|
reg_lambda |
float: [0, +∞], {0.0, 10.0, 0.1} |
L2正则项 |
|
scale_pos_weight |
float: (0, +∞) |
调节正负样本平衡,负样本/正样本 |
|
base_score |
float: (0, 1), {0.1, 0.9, 0.1} |
预测值的初始值 |
PCARegression
|
参数 |
类型 |
说明 |
|
n_components |
int or null: [1, min(行数, 列数)] |
保留主成分个数,null表示自动设置,默认为null |
|
whiten |
bool |
是否进行单位根变换 |
|
svd_solver |
string: ["auto", "full", "arpack", "randomized"] |
主成分求解方法,默认为full |
|
tol |
float: (0, 1) |
求解精度,默认0.0001 |
|
fit_intercept |
bool |
是否包含截距项 |
|
normalize |
bool |
是否将数据标准化 |
多分类模型
【多分类模型】主要用来配置建模时用到的多分类模型,选出的模型将会参与建模流程。
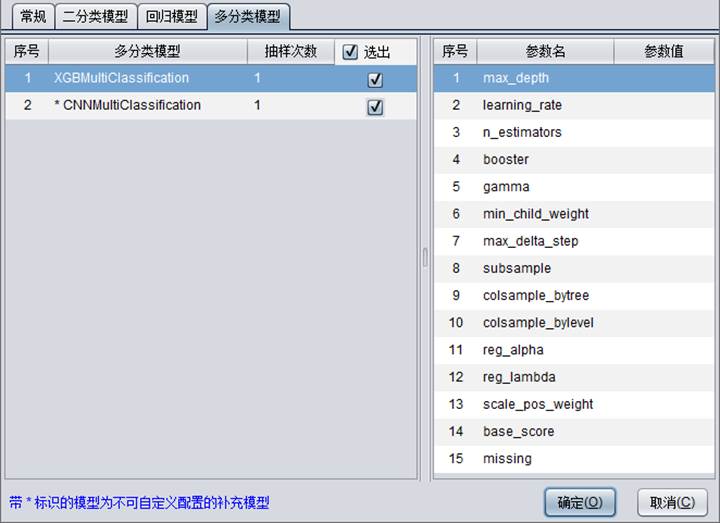
多分类模型包含2种模型:XGBMultiClassification、CNNMultiClassification
抽样次数是指某个模型在建模时使用几份样本。
关于多分类模型的一些参数配置说明,请参考附录3。
附录3:多分类模型参数
XGBMultiClassification
|
参数 |
类型 |
说明 |
|
max_depth |
int: [1, +∞), {1, 100, 1} |
树最大深度 |
|
learning_rate |
float: (0, 1), {0.1, 0.9, 0.1} |
学习率,越大速度越快,但可能找不到最优解 |
|
n_estimators |
int: [1, +∞), {10, 500, 10} |
booster trees数量 |
|
booster |
string: ["gbtree", "gblinear", "dart"] |
使用booster种类 |
|
gamma |
float: [0, +∞) |
分裂节点时所需的最小损失降低值。 |
|
min_child_weight |
int: [1, +∞), {10, 1000, 10} |
子节点最小样本权重和 |
|
max_delta_step |
int: [0, +∞), {0, 10, 1} |
在每棵树的权重估计中,允许的最大delta步长。 |
|
subsample |
float: (0, 1], {0.1, 1.0, 0.1} |
用于训练模型的子样本占整个样本集合的比例。 |
|
colsample_bytree |
float: (0, 1], {0.1, 1.0, 0.1} |
在建立树时对特征采样的比例。 |
|
colsample_bylevel |
float: (0, 1], {0.1, 1.0, 0.1} |
分裂时,在每个水平层次上,对列的采样比例。 |
|
reg_alpha |
float: [0, +∞], {0.0, 10.0, 0.1} |
L1正则项 |
|
reg_lambda |
float: [0, +∞], {0.0, 10.0, 0.1} |
L2正则项 |
|
scale_pos_weight |
float: (0, +∞) |
调节正负样本平衡,负样本/正样本 |
|
base_score |
float: (0, 1), {0.1, 0.9, 0.1} |
预测值的初始值 |
CNNMultiClassification
由于神经网络的特殊性,此模型参数暂时无法开放
执行建模
建模前必须选择目标变量并且在【建模文件】中选择建模文件名称。系统默认模型文件的路径与导入数据的文件在同一目录下,名称与导入文件相同。用户也可以自定义模型文件路径及名称。模型文件后缀为.pcf。如下图:
![]()
在菜单栏中点击【执行】à【建模】,或者直接在工具栏中点击![]() 执行建模,此时会弹出创建模型的窗口并输出建模相关的信息,
执行建模,此时会弹出创建模型的窗口并输出建模相关的信息,
最后输出“生成模型文件成功”表示建模完成。

建模完成之后,变量面板中会统计出各个变量的“重要度”,如下图所示,通过重要度可以体现出每个变量对未来预测结果的影响力,重要度越高,说明对预测结果影响越大。重要度为0的变量对预测结果无影响。从下面显示结果可以看到,Sex(性别)变量对预测结果影响最大。
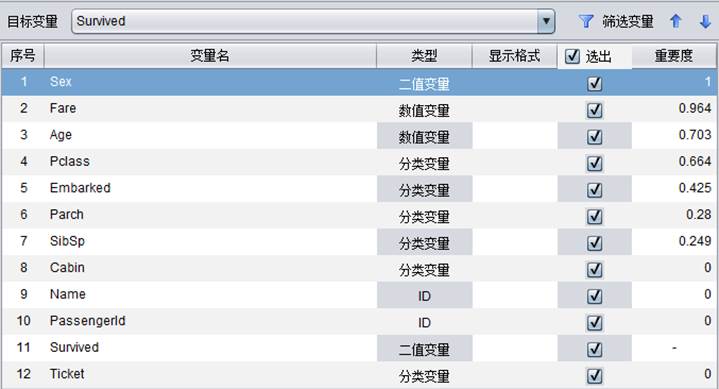
模型文件信息
模型描述
易明建模功能中包含多种算法,具体如下:Decision Tree(决策树),Gradient Boosting(梯度提升),Logistic Regression(逻辑回归),Neural Network(神经网络),Random Forest(随机森林),Elastic Net(ElasticNet回归),LASSO Regression(套索回归),Linear Regression(线性回归),Ridge Regression(岭回归),XGBoost(梯度提升算法)。
执行建模完成后,可以在创建模型窗口中点击按钮![]() 来查看使用的算法,模型描述中的算法可以有一种或多种,本示例中的模型描述如下:
来查看使用的算法,模型描述中的算法可以有一种或多种,本示例中的模型描述如下:
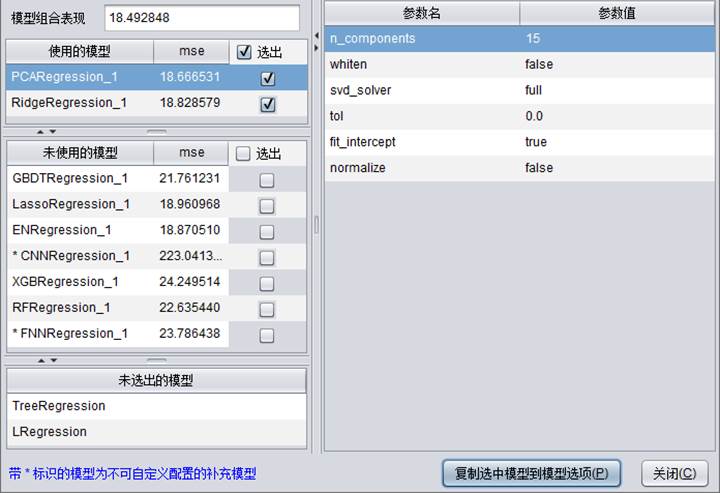
模型表现
模型表现功能中展示该模型相关信息。
在创建模型窗口中点击【模型表现】按钮:
![]()
不同类型的目标变量,模型表现中图表显示的参数及形式也不相同。
以二值变量Survived作为目标变量的模型表现:

以数值变量Age作为目标变量的模型表现:
