
大报表中集算器数据集的使用
针对SQL数据集、脚本数据集和集算器数据集的大数据优化,产品提供了大报表运算。目前大报表仅支持SQL检索数据集、脚本数据集和集算器数据集三种,适用于处理大数据的网格式报表。大报表中SQL检索的使用可参见大报表章节,本节主要讲集算器数据集在大报表中的使用。
集算器数据集数据管理方式分两种:缓存—基于缓存文件取数;SPL自管理—通过自定义spl取数,每次取数后页面都会重新计算spl,取一页算一页。
当数据集用于大报表,并且需在集算器数据集中自定义缓存文件时,需将缓存文件名对应的变量设置为集算器中的缓存文件变量。
数据管理方式为缓存,数据集返回游标
添加集算器数据集,程序自动将分批取出的数据进行缓存,数据集返回游标。
第一步:打开设计器
第二步:连接数据源
第三步:新建空白报表
第四步:定义集算器数据集,选择集算器文件
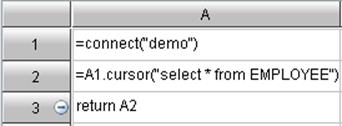
第五步:定义表达式

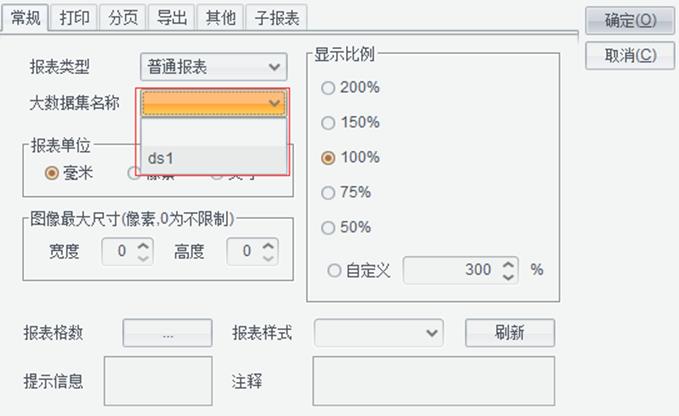
第六步:设置大数据集名称,选择ds1
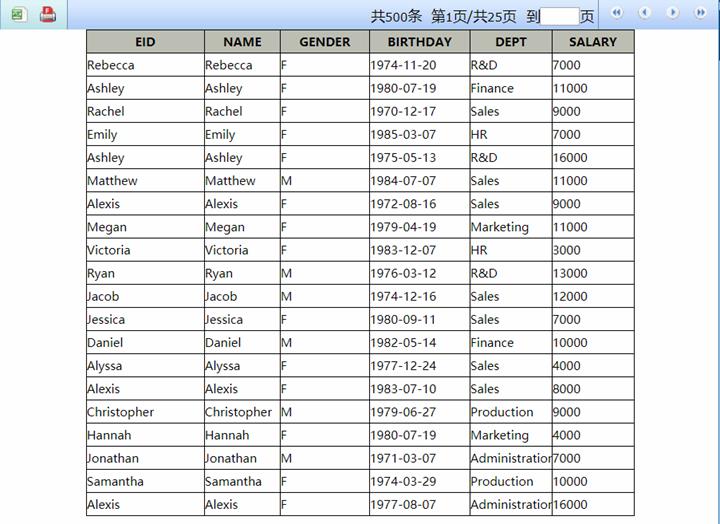
第七步:此报表另存为18.3.1.rpx,保存预览,发布报表。
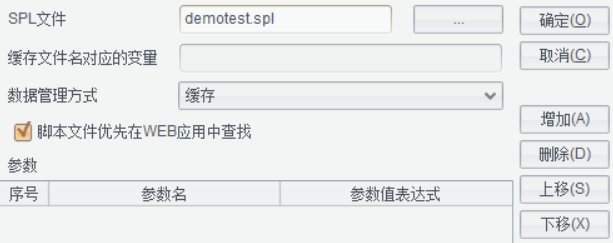
数据管理方式为缓存,集算器数据集中自定义缓存文件
使用自定义缓存文件时,集算器数据集所调用的spl只会执行一次,但如果数据量很大,那么等待的执行时间则会比较长,所以这种模式适合数据量不是很大时使用。
第一步:打开设计器
第二步:连接数据源
第三步:新建空白报表
第四步:定义集算器数据集,选择集算器文件
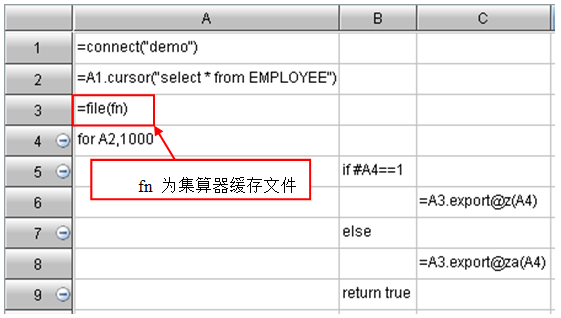
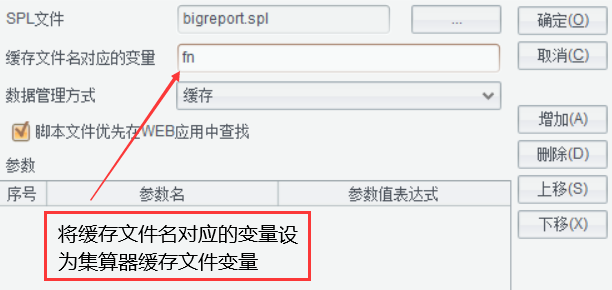
当集算器数据集中自定义缓存文件时,需将缓存文件名对应的变量设置为集算器中的缓存文件变量。缓存文件路径为raqsoftConfig.xml中定义的报表缓存目录cachedReportDir。
第五步:定义表达式

第六步:设置大数据集名称,选择ds1
第七步:此报表另存为18.3.2.rpx,保存预览,发布报表
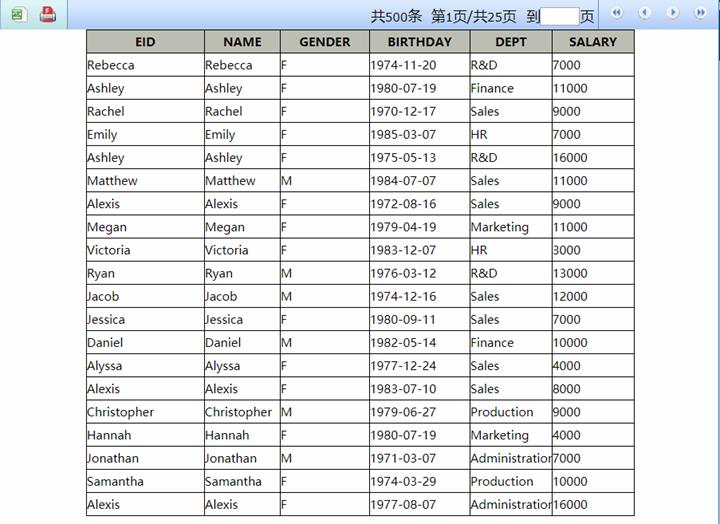
数据管理方式为 SPL 自管理
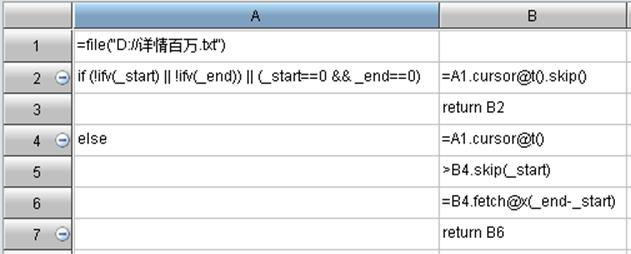
使用SPL自管理时自定义的spl需要判断_start和_end的值,程序每次都会根据_start起始行和_end结束行获取每页记录,_start/_end变量名是程序定义的,不可修改。spl中需要对参数_start和_end添加是否为空的判断,如果没有这两个参数,则需要返回总条数,用于计算显示总页数;否则,则根据_start和_end返回其间的Table或排列。
获取每页记录时,程序会自动根据每页行数(tag标签中rowNumPerPage属性)设置_start和_end的值。如每页20行,则取第11页时程序会自动将_start设为200,_end则会自动设为220,以此类推。
计算时每取一页都会重新计算spl,如果需要连接数据库,则每次都会重新连接。
第一步:打开设计器
第二步:“工具”-> “数据源”菜单,连接数据源
第三步:新建空白报表
第四步:“报表”-> “数据集”菜单,定义集算器数据集,选择集算器文件
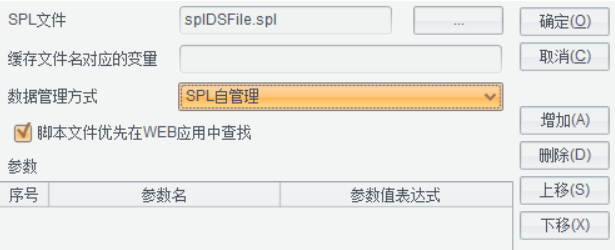
其中集算器文件内容如下:
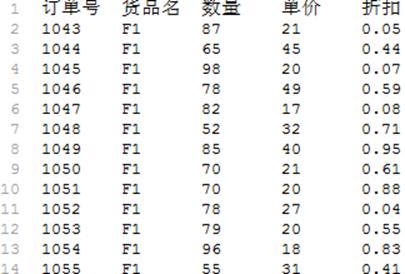
文本文件“详情百万.txt”有百万条数据,数据结构如下:
第五步:定义表达式

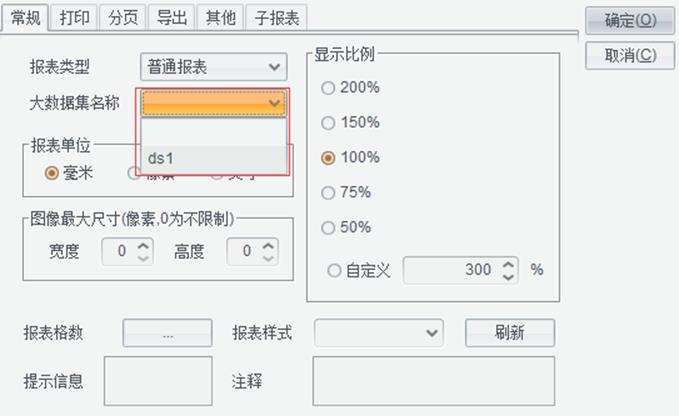
第六步:设置大数据集名称
第七步:此报表另存为18.3.3.rpx,发布报表
