
巧用集算器数据集
看如下图所示报表:

这个报表从样式来看,可以看做是一个简单的网格式报表,统计着各种收支金额,但因为取数复杂,每个格子的数据都来自一个复杂的SQL数据集,并且涉及十几个,乃至几十个数据集,蓝色区域里每个格子都需要从各自的数据集里检索遍历,查找与左表头关联的记录。为了方便体会这一点,我们将上图报表简化一下,如下图所示:

C1,D1单元格都分别从ds2,ds3中取数,并通过关联条件与B1关联, 诸如这种几十个数据集在报表端的遍历、关联,如果遇到大数据量,大的并发,速度就会受到影响,并且这也只适合一对一的情况,如果遇到一对多的情况,就无法如此运用了。
所以,如果这些数据集能整合为一个数据集,所有的关联都放在数据集里去处理,那么报表端的计算就变得灵活简单的多,但是SQL数据集去完成这个拼接比较困难,也会很慢,集算器数据集正好能完成这个工作,速度也会大幅提升,解决思路如下:
1、 通过fork多线程取数,并行读出每个数据集
eg:
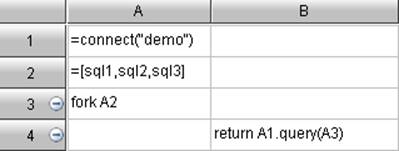
2、 通过join/align完成每个数据集的横向拼接
eg:=join@l(A3(1):amount1,订单ID;A3(2):amount2,订单ID;A3(3):amount3,订单ID)
3、 通过new返回报表一个数据集
eg:=A5.new(amount1.订单ID,amount1.订单金额,amount2.数量,amount3.回款额)
以上只是提供一个思路,具体运用哪个函数,哪个选项,还需要根据实际数据合理选择,集算器函数具体用法请参考《集算器函数参考》。
除此之外,像常见的需要用于汇总统计的原始数据量非常大,报表并不大的情况,如果每次生成报表都需要现算,一方面非常慢,另一方面数据库的压力会很大,此时传统办法可以采用存储过程数据集对数据预先进行一次压缩,生成中间表,然后再基于中间表生成报表,可以大大提高运算速度并减轻数据库的压力。但是存储过程如果脚本过于复杂,那么后期维护比较麻烦,而且数据处理的灵活性也受限,这个时候用集算器数据集或者脚本数据集来处理数据,就方便的多。